
Design Facebook Likes (Distributed Counter)
Problem Context
👍 Facebook's Like button is one of the most clicked elements on the internet. With over 3 billion monthly active users, Facebook processes billions of likes every single day.
This is fundamentally a distributed counting problem. It's a simple system but at Facebook's scale, the simple increment becomes one of the hardest problems in distributed systems.
Functional Requirements
The Like feature seems simple, but clarifying exact behavior with your interviewer prevents getting out of scope. Does "like count" include reactions? Are we handling comments too?
Core Functional Requirements
- FR1: Users should be able to like and unlike content.
- FR2: Users should be able to view the total like count on any content.
- FR3: Users should be able to see whether they have already liked something.
Out of Scope
- Reactions beyond "like" (love, haha, angry, etc.)
- Like notifications and activity feeds
- Analytics on who liked what
- Comment likes (we'll focus on post likes)
Non-Functional Requirements
Core Non-Functional Requirements
- NFR1: Like action should complete within 1 second.
- NFR2: Like counts can be eventually consistent within 5 seconds.
- NFR3: System should handle 1M+ likes/second during viral events.
- NFR4: System should be highly available (99.99%+).
Notice NFR2: we explicitly accept eventual consistency. Nobody needs the exact like count very quickly.
Here's our whiteboard so far.

Let's keep going!
The Set Up
Defining the Core Entities
- Like: A record that user X liked content Y at time Z.
- LikeCount: The aggregated count of likes for a piece of content.
- Content: The thing being liked (post, photo, video). We treat this as an external entity.
API Interface
Our API is straightforward. There are three endpoints that cover all functional requirements.
In an interview, don't over-engineer the API. These three endpoints are sufficient for our requirements.
1. Like Content
POST /content/{contentId}/like
Request Headers:
Authorization: Bearer <token>
Response:
{
"success": true,
"liked": true,
"newCount": 4521
}
The user sends their intent to like. We return the updated state including whether they've now liked it and the approximate new count.
2. Unlike Content
DELETE /content/{contentId}/like
Request Headers:
Authorization: Bearer <token>
Response:
{
"success": true,
"liked": false,
"newCount": 4520
}
Same pattern as liking, but removes the like.
3. Get Like Status
GET /content/{contentId}/likes
Request Headers:
Authorization: Bearer <token>
Response:
{
"count": 4520,
"userLiked": true
}
Returns the current count and whether the requesting user has liked this content. This is called every time content is rendered.
The userLiked field is critical for UX. The button must show filled/unfilled state correctly. This is a separate concern from the count and has stricter consistency requirements.
High-Level Design
Let's tackle our functional requirements:
- FR1: Like and unlike content
- FR2: View like count
- FR3: See if user already liked
We'll start with a simple approach and build it up. In an interview, you need to build a functioning system before trying to do large optimizations.
1) The Simplest Approach: FR1, FR2
A user clicks like, and we write to a database. When someone views the post, we count the likes.
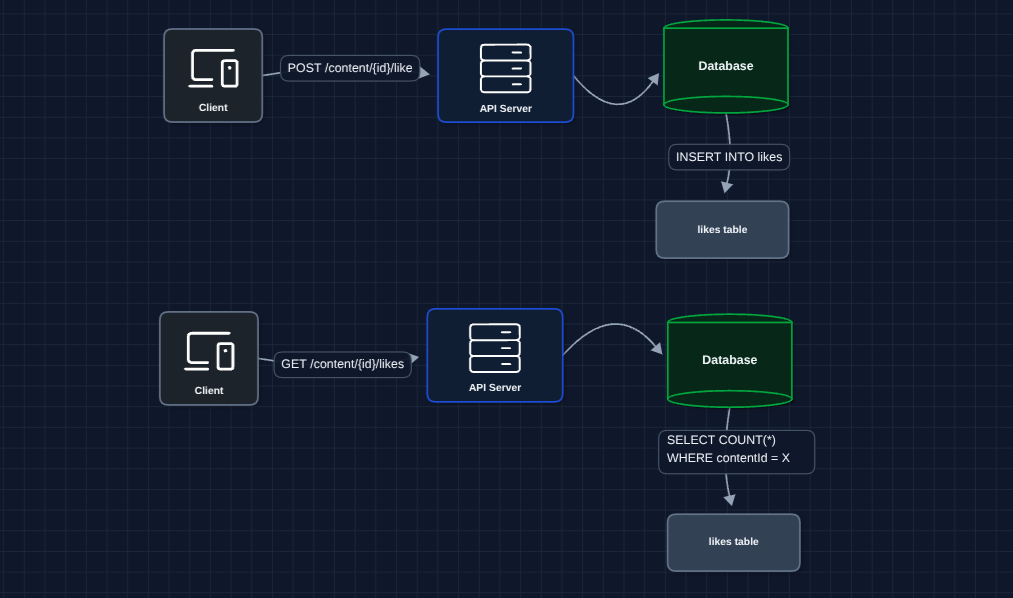
Every like is a row, and every read counts rows. You may start to see some flaws.
What breaks?
- Counting is expensive:
SELECT COUNT(*)over millions of rows is slow. - No scale: One database becomes a bottleneck.
- High latency reads: Every page load runs an aggregation query.
We need to pre-compute the count instead of calculating it on every read.
2) Pre-Computed Counter: FR2
Instead of counting rows on every read, let's maintain a running total. When someone likes, we increment the counter. When they view, we just read the counter.
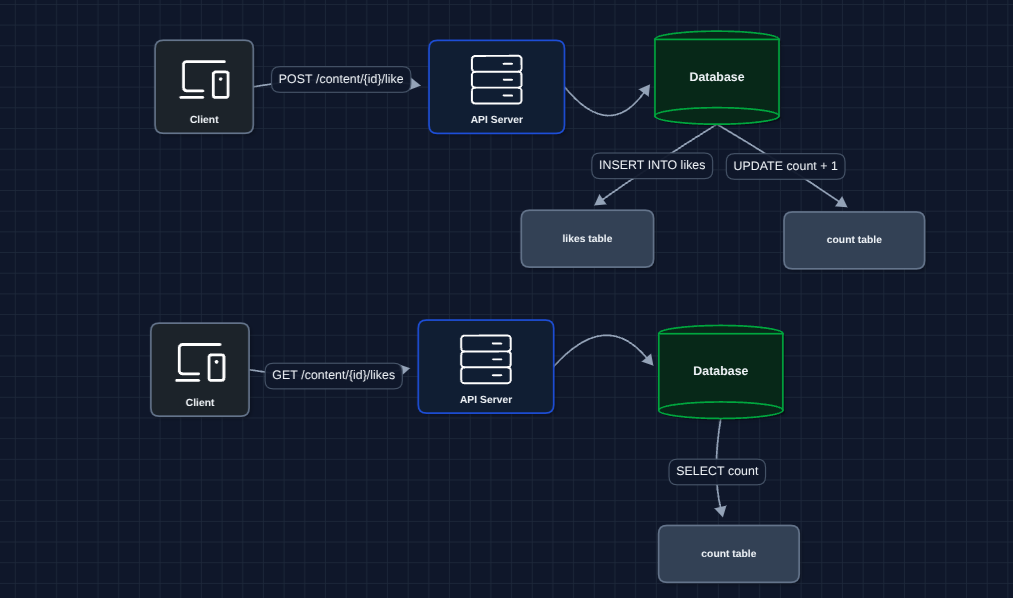
Reads are now instant and we just fetch one row from counts table.
What breaks?
- Write contention: Every like to the same post updates the SAME row in
counts. - Hot key problem: A viral post getting 100K likes/second means 100K updates/second to ONE row.
- Database locks: Row-level locking causes all concurrent writes to queue up.
This is the hot key problem.
3) Sharded Counters: NFR3 (Scale)
The hot key problem exists because all writes target one row. The fix: split that one row into many rows.
Instead of one counter for contentId "post123", we create N counter shards:
post123_shard_0post123_shard_1post123_shard_2- ... up to N shards
Each like randomly picks a shard to increment. The total count = sum of all shards.
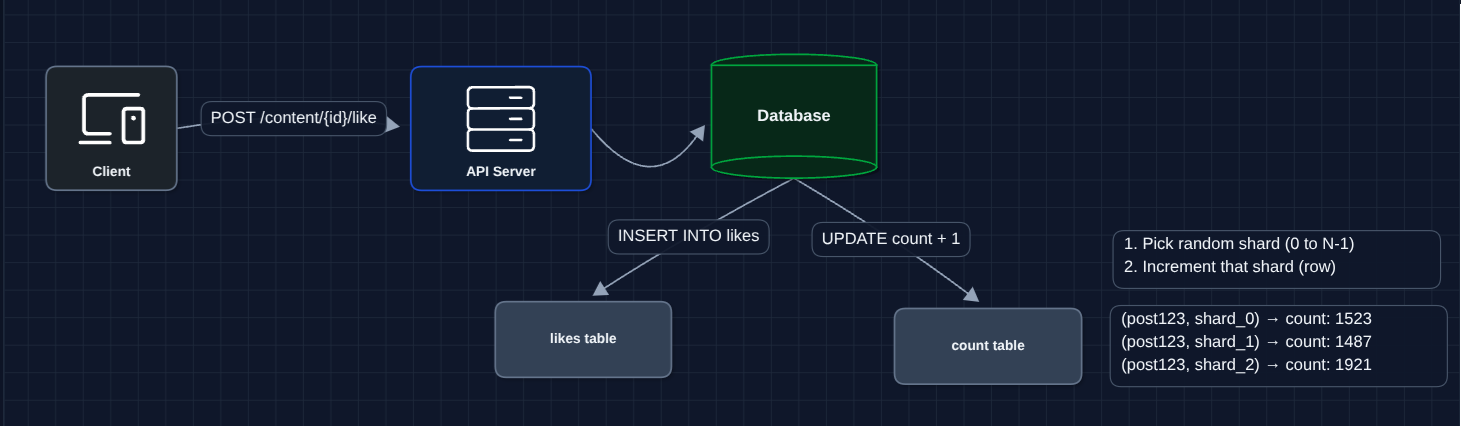
With 100 shards, each shard handles only 1/100th of the traffic. The database can handle this easily.
What breaks?
- Reads are slower: Now we must read N shards and sum them just to get the count.
- Read amplification: Popular content = many shards = many reads per view.
4) Aggregation Cache: FR2 + NFR3
Reads shouldn't pay the cost of summing shards every time. Let's cache the aggregated total.
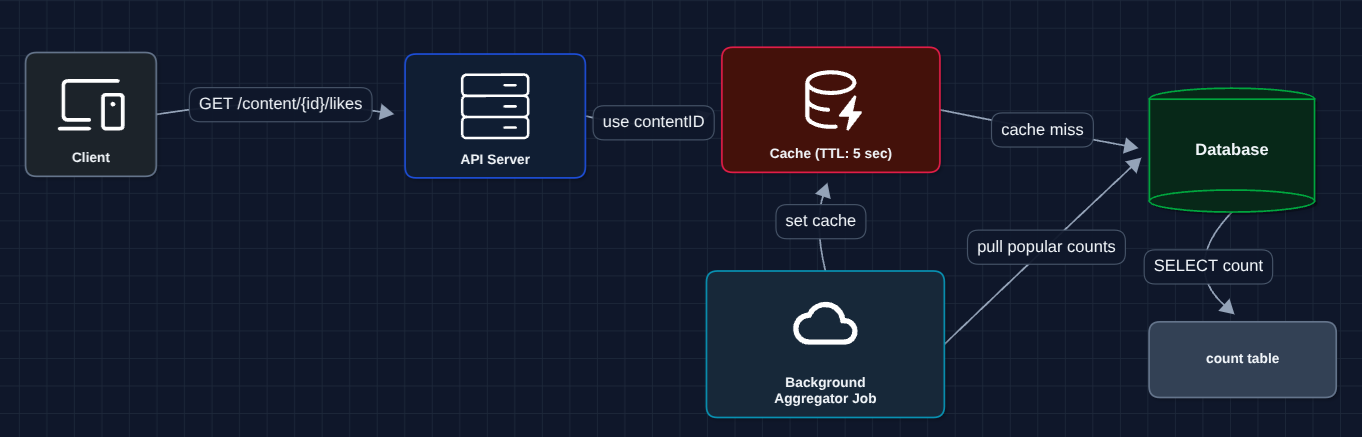
Reads now hit the cache directly. The aggregator periodically sums shards and updates the cache for very popular content. This is why NFR2 allows 5 seconds of staleness (it gives us room to batch aggregation).
What breaks?
- Write amplification: We're still hitting the database on every single like.
- Viral traffic: 1M likes/second is 1M database writes/second. That's still too many.
5) Write Buffering: NFR3 (Scale) ✅
This is a key fix for our high level design. Don't write every like to the database immediately. Buffer writes in memory and flush periodically.
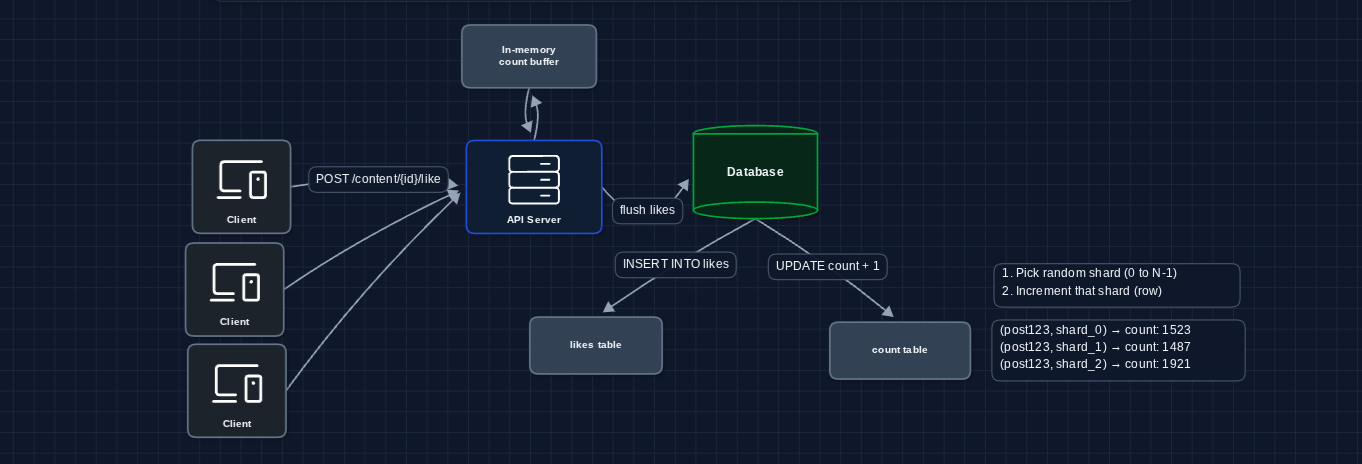
Instead of 1 million individual increments, we batch them. Each server collects likes in memory, then flushes once per second as a single increment per content.
This is our complete write path! We've reduced database writes by 1000x while maintaining correctness.
Complete System: FR1 ✅, FR2 ✅, FR3 ✅
Let's put everything together:
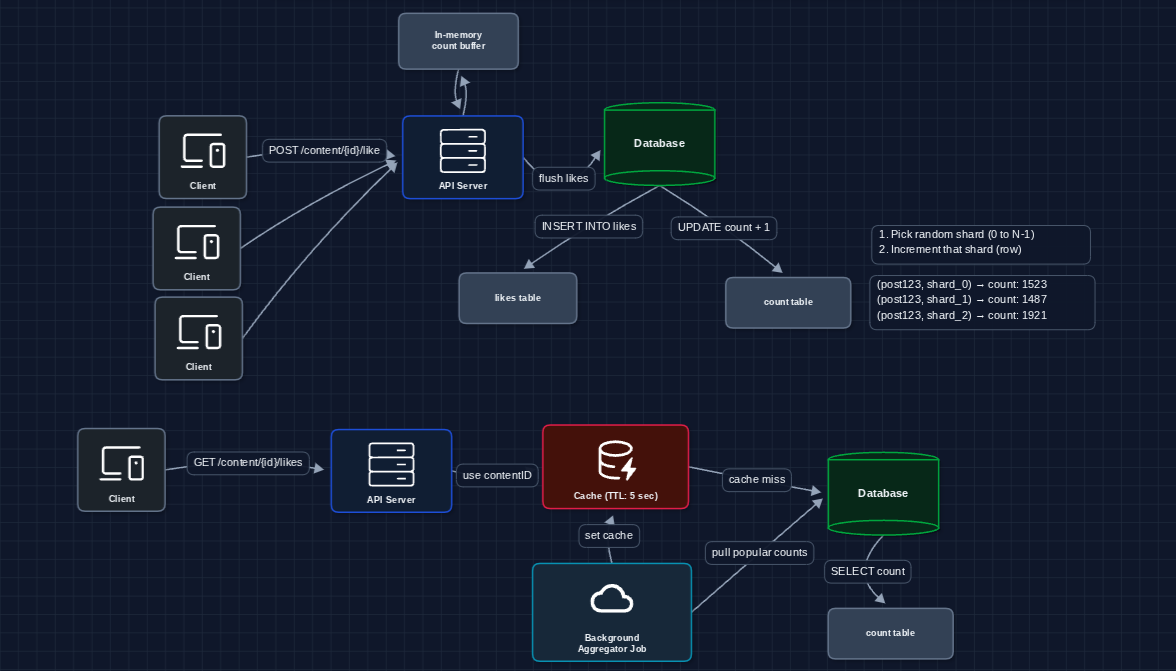
How each requirement is satisfied:
- FR1 (Like/Unlike): Write to likes table + buffer counter increment
- FR2 (View count): Read from cache (backed by aggregated shards)
- FR3 (User liked?): Query likes table for (userId, contentId) pair
Database choices:
- likes table: MySQL or PostgreSQL with application-level sharding. Both handle point lookups efficiently. At Facebook's scale, they shard across many database instances.
- counts_sharded table: Same database works fine.
- Cache: Redis or Memcached. Both are in-memory and fast. Redis is more common since you might already use it elsewhere if you are designing Facebook.
Potential Deep Dives
1) The Hot Key Problem Explained: NFR3 (Scale)
In Diagram 2, we hit a wall: all likes to one post update one row. Let's understand exactly why this fails.
Database row updates require locks. When you increment a counter, the database must:
- Acquire a lock on the row
- Read the current value
- Compute new value
- Write new value
- Release the lock

Threads queue up waiting for the lock. Even with a fast database, lock contention creates a hard ceiling.
Sharding eliminates this. With 100 shards, 100 threads can update simultaneously with each grabbing a different shard.

The shard count can be dynamic. Start with 10 shards, and if content goes viral, create more shards on-the-fly.
2) Write Buffering Strategy: NFR3 (Scale)
From Diagram 5, we buffer writes in memory before flushing. Let's go deeper into how this works.

We converted 847 individual DB writes into 1 batched write. At scale, this is the difference between surviving and melting.
But what if the server crashes before flushing?

Durability vs. Performance tradeoff: We sacrifice durability (some likes may be lost) for performance (1000x fewer writes). This is acceptable for like counts but would be catastrophic for financial systems.
3) Read Your Own Like: FR3 + Consistency
From Diagram 6, the count cache can be 5 seconds stale. But what if the user clicks like and the button still shows unliked?
The simplest solution is optimistic UI: update the button state locally before the server responds.

The server doesn't need to guarantee "read your own writes" for userLiked. The client handles it locally. The server just needs to return the correct state on initial page load.
This is what Facebook, Twitter, and Instagram actually do. The like button feels instant because it IS instant. The network request happens in the background.
4) Deduplication - One Like Per User: FR1
A user should only be able to like something once. Clicking the button 100 times shouldn't add 100 likes. The likes table from Diagram 6 handles this.

The database's primary key constraint is the source of truth. Even if two requests race past any application-level checks, the database will reject the duplicate.
5) Scaling the Likes Database: NFR3 (Scale)
The likes table in Diagram 6 stores every (userId, contentId) pair. With billions of users and millions of posts, this table grows massive. How do we scale it?
Don't confuse the likes table with the counts table. They serve different purposes and are sharded differently.
| Table | Purpose | Sharded By |
|---|---|---|
likes | Track which user liked which content (FR3, deduplication) | userId |
counts_sharded | Store the like count for each content (FR2) | contentId |
Why shard the likes table by userId?
The most frequent query is: "Has this user liked this content?" This happens on every page load to show the filled/unfilled like button. Sharding by userId makes this a single-shard lookup.

With 256 shards and billions of likes, each shard holds ~10-50 million rows. This is manageable for modern databases.
The Tradeoff: Who liked this content?
Since we shard by userId, queries like "show me everyone who liked post X" become expensive. We must query all 256 shards and merge results (scatter-gather).
| Query | Frequency | With userId Sharding |
|---|---|---|
| "Did I like this?" | Every page load | ✅ Single shard lookup |
| "Who liked this?" | Rare (click to expand) | ⚠️ Scatter-gather all shards |
How do platforms handle this?
In practice, you rarely need the full list. When Facebook shows "John, Sarah, and 4,521 others liked this", they:
- Cache a small list of recent likers per content (on each like,
LPUSHuserId to Redis,LTRIMto keep last ~10), along with the like count - Display that cached list and the count from the counter system
- Only run the expensive scatter-gather if the user clicks "See all" (which is rare)
If the owner of the post deleted it, we could run a background job to DELETE all likes for that post from the likes table, and DELETE the sharded counts from the count table.
What to Expect?
Mid-level
- Breadth over Depth (80/20): Get through Diagrams 1-4. Understand why a single counter fails under load and how sharding helps. Know what sharding actually does.
- Expect Basic Probing: "What happens if two users like at the same time?" or "Why not just use Redis?"
- The Bar: Demonstrate understanding of the hot key problem and propose sharding as the solution. Explain why like counts allow eventual consistency.
Senior
- Balanced Breadth & Depth (60/40): Complete the full HLD (Diagram 6) and articulate the write buffering strategy. Discuss at least 2 deep dives.
- Proactive Problem-Solving: You identify the consistency split (count vs. userLiked) before being asked. You bring up crash recovery implications of buffering.
- Articulate Trade-offs: "We trade durability for throughput by buffering, which is acceptable for likes but wouldn't be for payments."
- The Bar: Full system design plus deep dives into sharding strategy, write buffering, and either consistency or deduplication.
Staff
- Depth over Breadth (40/60): Breeze through the HLD quickly (~10 min). Spend time on nuances: dynamic shard creation for viral content, cache warming strategies, cross-datacenter replication of like counts.
- Experience-Backed Decisions: "In production, we found that 1-second flush intervals hit the sweet spot between latency and batch size..."
- The Bar: Address all deep dives unprompted. Discuss operational concerns: monitoring for hot content, alerting on buffer growth, gradual shard rebalancing. Connect this to similar distributed counting problems.
Practice this problem with an AI mock and good luck on your interview 👍