
Design Uber Backend (Dispatch & Matching)
Problem Context
🚗 Uber is a global ride-hailing platform that connects riders with drivers in real-time. It handles millions of concurrent users in hundreds of cities worldwide.
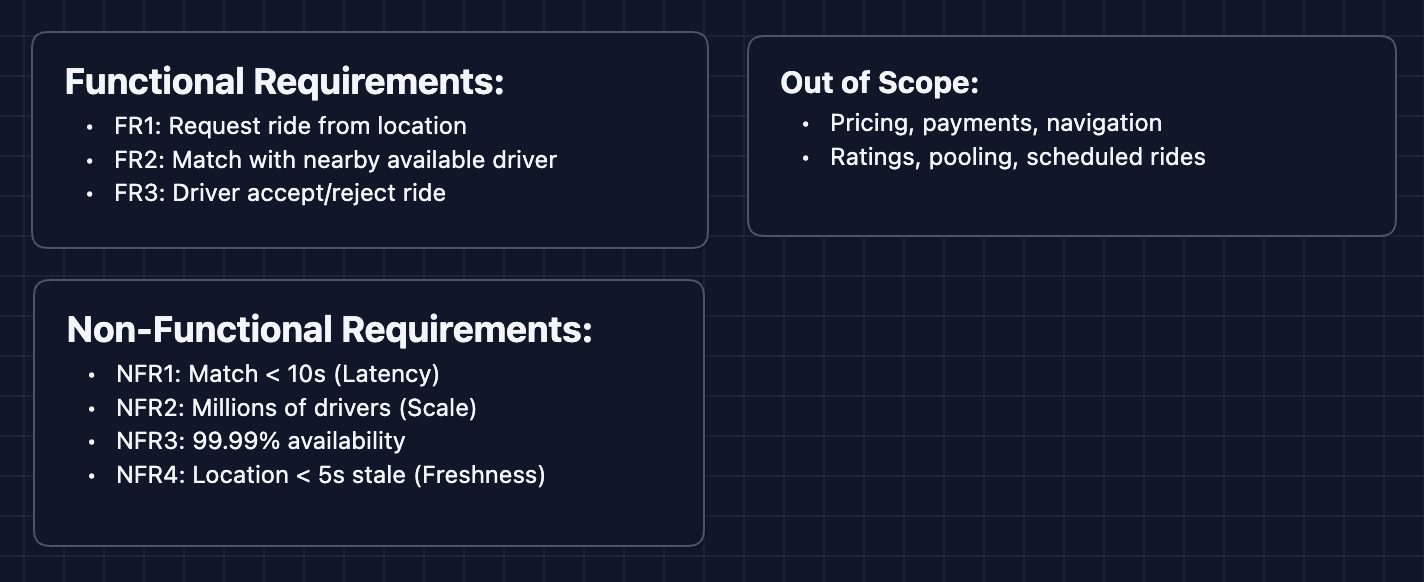
Functional Requirements
In an interview, first clarify the scope with the interviewer. This article will focus on the dispatch and matching system.
Core Functional Requirements
- FR1: Riders should be able to request a ride from their current location.
- FR2: The system should match riders with nearby available drivers.
- FR3: Drivers should be able to accept or reject ride requests.
Out of Scope
- Pricing and surge logic (dynamic pricing is its own system).
- Payment processing.
- Navigation and routing (handled by mapping services).
- Driver ratings and reviews.
- Ride pooling (UberPool).
- Scheduled/future rides.
Focusing on dispatch and matching lets us explore the real-time, location-based challenges that make Uber technically interesting.
Non-Functional Requirements
Core Non-Functional Requirements
- NFR1: Match latency should be < 10 seconds from request to driver notification.
- NFR2: System should handle millions of concurrent drivers sending location updates.
- NFR3: System should be highly available (99.99%+).
- NFR4: Location data should be fresh (< 5 second staleness).
Here's our starting point:
Let's build the system!
The Set Up
Defining the Core Entities
For this problem, we have several entities to work with:
- Rider: A user requesting a ride.
- Driver: A partner providing rides. Has a status:
OFFLINE,AVAILABLE, orON_TRIP. - Ride Request: The intent to travel from pickup to destination.
- Trip: The actual ride, created once a driver accepts.
- Location: GPS coordinates (latitude, longitude) with a timestamp.
API Interface
Our APIs serve two types of users: Drivers (updating location and accepting rides) and Riders (requesting rides and tracking status).
Focus on what each API accomplishes, not exact syntax. In an interview, you want to convey the flow of data, even if the routes are different.
Driver APIs
1. Update Location (Called every 4 seconds while online)
POST /drivers/{driverId}/location
Request: {
latitude,
longitude,
timestamp
}
Response: { status: "ok" }
This is the most frequent API call in the system. With 1 million active drivers, that's 250,000 writes per second.
2. Go Online/Offline
PUT /drivers/{driverId}/status
Request: { status: "AVAILABLE" } // AVAILABLE | OFFLINE
Response: { status: "AVAILABLE" }
When a driver opens the app and goes online, they become eligible for matching.
3. Accept Ride
POST /rides/{rideId}/accept
Request: { driverId }
Response: {
tripId,
rider: { name, pickupLocation }
}
4. Reject Ride
POST /rides/{rideId}/reject
Request: {
driverId,
reason?
}
Response: { status: "ok" }
Rider APIs
1. Request Ride
POST /rides
Request: {
riderId,
pickupLocation: { latitude, longitude },
destination: { latitude, longitude }
}
Response: {
rideId,
status: "MATCHING",
estimatedWait
}
2. Get Ride Status
GET /rides/{rideId}
Response: {
rideId,
status,
driver: { name, rating, vehicle, location },
eta
}
Status values: MATCHING | DRIVER_ASSIGNED | EN_ROUTE | ARRIVED | IN_PROGRESS | COMPLETED
3. Cancel Ride
DELETE /rides/{rideId}
Response: { status: "CANCELLED" }
High-Level Design
Let's start with our functional requirements:
- FR1: Request ride from location
- FR2: Match with nearby available drivers
- FR3: Driver accept/reject
We'll start with the simplest design for the sake of explanation. In an interview, you might start directly at Diagram 3 once you understand the problem.
1) The Simplest System: FR1, FR2
The rider requests a ride, the server finds a driver and returns the match.
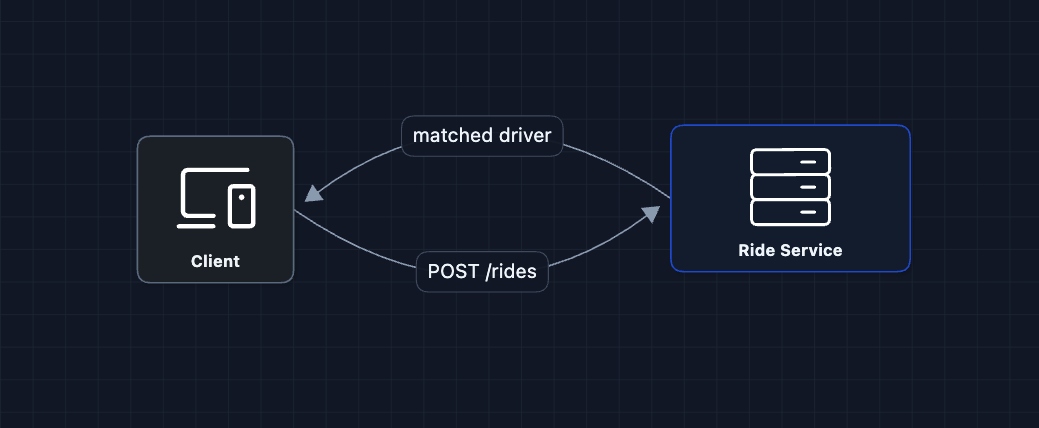
The rider requests a ride, the server finds a driver. But how do we find nearby drivers?
What breaks?
- Where are the drivers? We don't know their locations.
- How do we find nearby? We need to store and query locations.
- Which drivers are available vs. already on trips?
We need to track driver locations.
2) Add Location Storage: FR1, FR2
Drivers send their GPS coordinates every few seconds. We store them so we can query who's nearby.
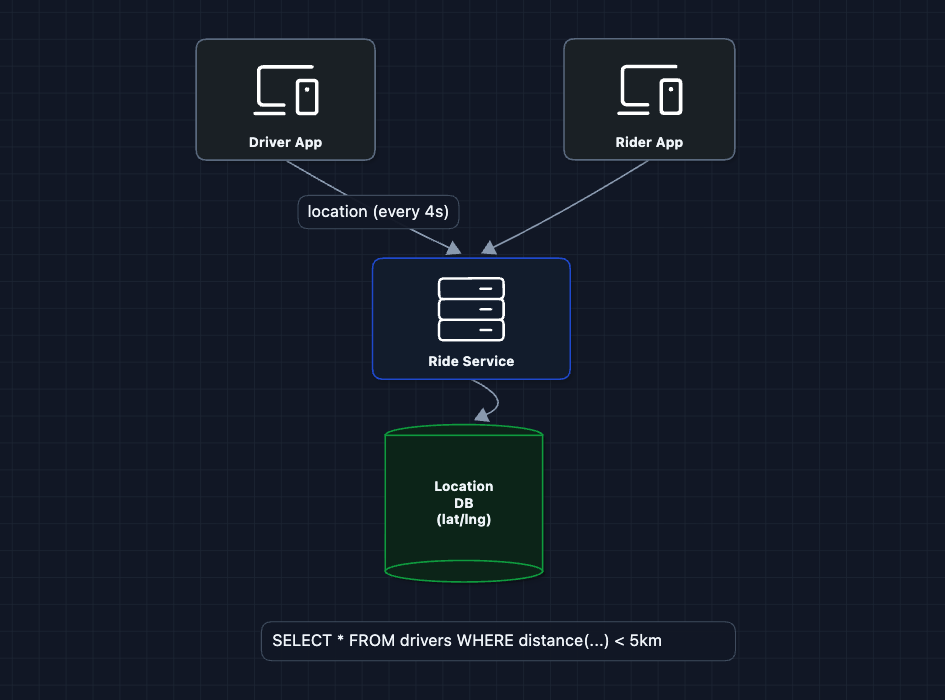
Now we have locations! But querying nearby is the problem.
What breaks?
Imagine the query: SELECT * FROM drivers WHERE distance(lat, lng, 37.77, -122.41) < 5km
This requires calculating the distance to every driver in the database. With 1 million drivers, that's 1 million distance calculations per ride request. Far too slow for our < 10 second requirement.
We need a smarter way to query locations.
3) Add Geospatial Indexing: FR1, FR2
The Location DB approach is too slow. Instead, we replace it with a Geo Index that partitions the world into cells. Find nearby becomes find drivers in this cell and adjacent cells.
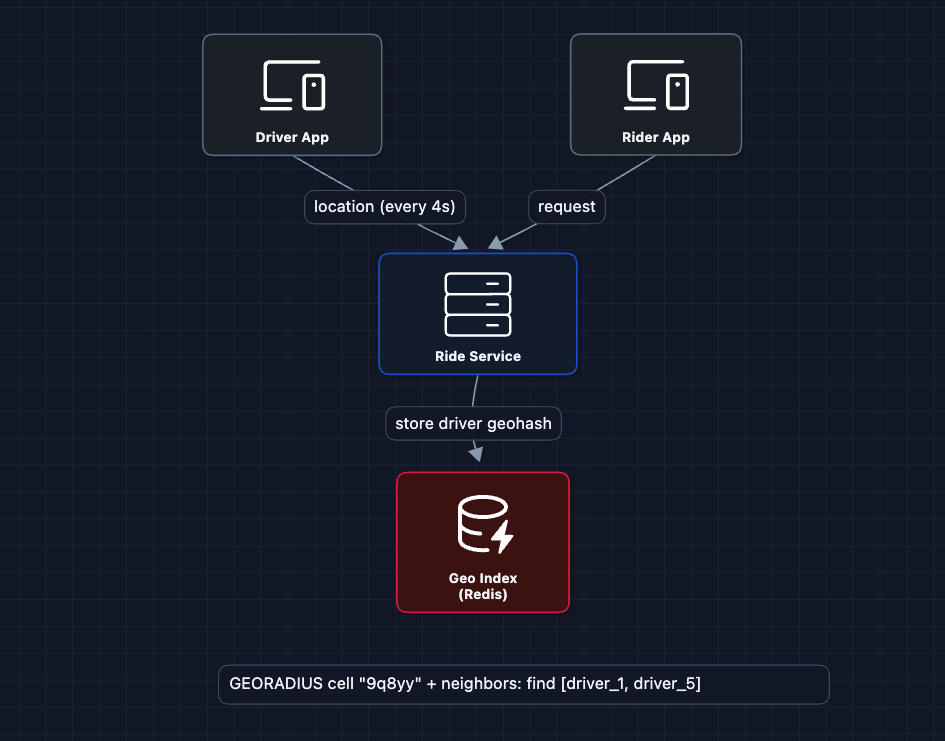
How does geospatial indexing work?
We use a technique called Geohash: encode latitude/longitude into a string like 9q8yy. Nearby locations share the same prefix. To find drivers within 1km, we query drivers whose geohash starts with the same prefix.
Why Redis?
Redis is ideal for the Geo Index because:
- In-memory: Sub-millisecond reads/writes for 250K location updates/second
- Built-in geo commands:
GEOADD,GEORADIUShandle geospatial queries natively - TTL support: Automatically expire stale driver locations
What breaks?
- We found nearby drivers, but are they all available? Some might be on trips already.
- We pick a driver, but what if they don't want the ride?
We need to track driver status.
4) Add Driver Status: FR2
Not every driver shown on the map is available. We need to track: OFFLINE, AVAILABLE, ON_TRIP.
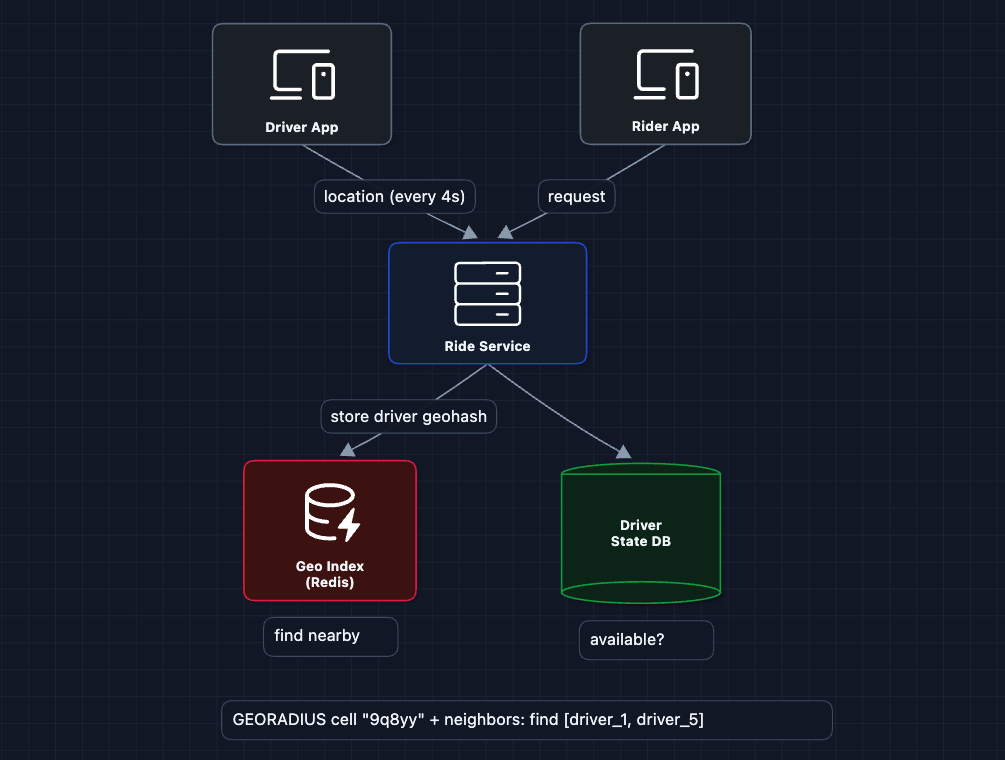
Now our matching logic:
- Query Geo Index for drivers in nearby cells
- Check Driver State DB to filter only
AVAILABLEdrivers - Pick the best one
What breaks?
We send the ride to driver_1. But what if they:
- Don't see the notification?
- Are eating lunch and reject?
- Accept but then cancel?
We need a dispatch flow with timeouts and retries.
5) Add Dispatch Flow: FR2, FR3 ✅
Instead of instantly assigning a driver, we offer the ride and wait for acceptance.
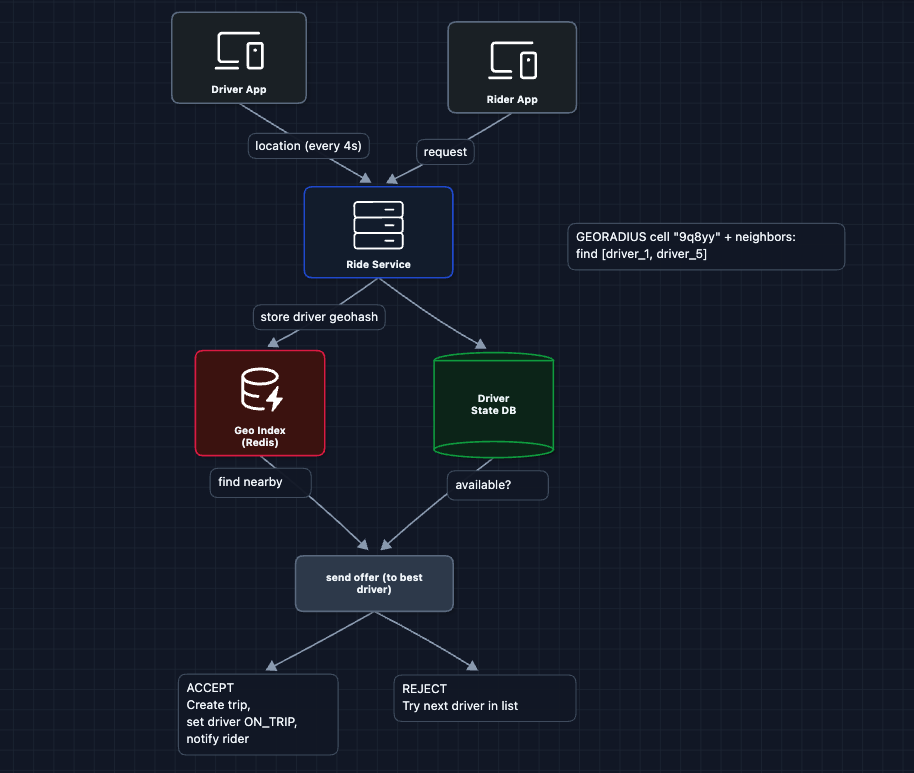
The dispatch flow:
- The rider requests a ride and the Ride Service finds nearby available drivers
- Ride Service picks the best driver and sends them a ride offer
- Driver has ~15 seconds to respond
- If accepted, we create a trip, update driver status to
ON_TRIP, and notify the rider - If rejected or timeout, we try the next best driver
What breaks?
How do we push the ride offer to the driver? And how does the rider get real-time updates of the driver? HTTP polling would be wasteful.
We need real-time communication.
6) Add Real-Time Updates: FR1, FR2, FR3 ✅
Both rider and driver apps need real-time updates. WebSockets provide persistent, bidirectional connections.
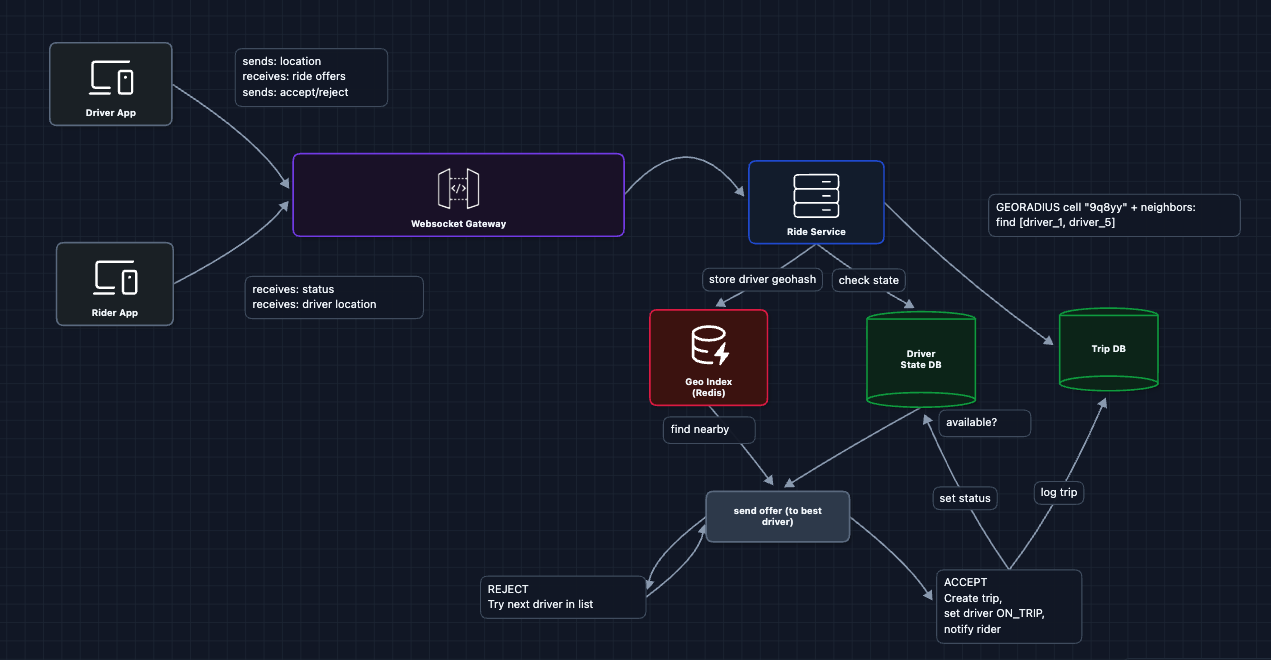
WebSocket Gateway responsibilities:
- Maintains persistent connections with all online drivers and active riders
- Routes ride offers TO drivers
- Pushes status updates TO riders (driver assigned, driver arriving)
- Streams driver location TO riders (for the moving car on the map)
The complete flow now:
- Rider opens app, and the WebSocket connection is established
- Driver goes online, establishing a WebSocket connection with status AVAILABLE
- Rider requests a ride, and the Ride Service finds the best driver
- Ride Service sends a ride offer to the driver via WebSocket Gateway
- Driver accepts, and Ride Service creates the trip and updates status
- Ride Service pushes driver assigned to the rider via WebSocket Gateway
- Driver location updates are streamed to the rider via WebSocket
Now we have a complete working system that satisfies all functional requirements:
- FR1 ✅ Request ride (Diagrams 1-2)
- FR2 ✅ Match with nearby driver (Diagrams 3-5)
- FR3 ✅ Accept/reject rides (Diagrams 5-6)
Now we can address our non-functional requirements and more in the deep dives:
- NFR1 (< 10s match): How do we find the best driver quickly?
- NFR2 (Scale): How do we handle millions of location updates?
- NFR4 (Freshness): How do we ensure location data isn't stale?
- NFR3 (Availability): What happens when things fail?
Potential Deep Dives
1) How do we find nearby drivers efficiently?: NFR1 (< 10s Match)
In the HLD, we introduced geospatial indexing. Let's go deeper.
The problem with simple queries:
SELECT * FROM drivers
WHERE distance(lat, lng, 37.77, -122.41) < 5
This calculates distance to every driver (which would be O(n) complexity). With 1M drivers and 1000 ride requests/second, that's 1 billion distance calculations per second.
The solution: Geohash
Geohash encodes a latitude/longitude pair into a string. Nearby locations share prefixes. For example, San Francisco (37.7749, -122.4194) encodes to 9q8yyk. The prefix length determines precision: 9q8 covers a city (~150 km), 9q8yy covers blocks (~5 km), and 9q8yyk covers a street (~1 km).

Alternative: Quadtrees or S2 Cells. Google Maps uses S2, which handles edge cases at cell boundaries better. Either way, we partition space into cells for fast queries.
2) How do we pick the best driver?: FR2
Finding nearby drivers is step one. But which one should we pick?
The approach we used in the HLD was to pick the closest driver by distance. That's simple, but distance doesn't equal arrival time. A driver 2km away on an empty road might arrive faster than a driver 0.5km away stuck in traffic.
The better approach: ETA-based ranking

In production systems: Real matching uses multi-factor scoring that considers ETA (primary), driver acceptance rate, driver rating, current heading direction, and time since last ride. The final score determines the best match.
ETA calculations require calling a routing service, which adds latency. Calculate ETA only for the top 5-10 candidates by distance, not all nearby drivers.
3) How do we handle millions of location updates?: NFR2 (Scale)
This is the highest-throughput part of the system. With 1 million active drivers sending location updates every 4 seconds, that's 250,000 writes per second. Each write must update the driver's location in the geo index, update their last_seen timestamp, and potentially notify any rider tracking this driver. A single database can't handle this load.
Solution: Shard by region
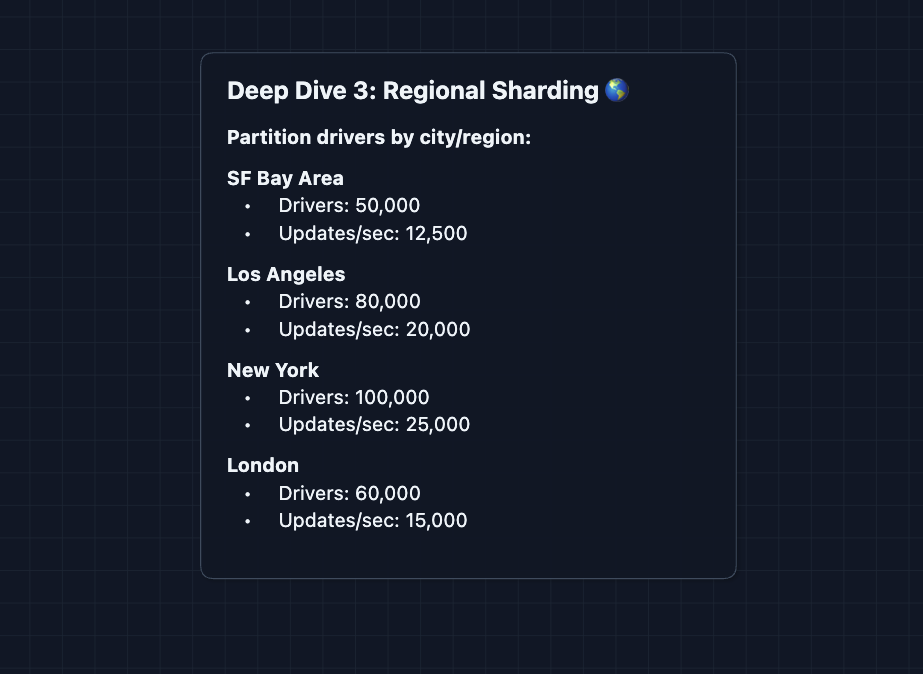
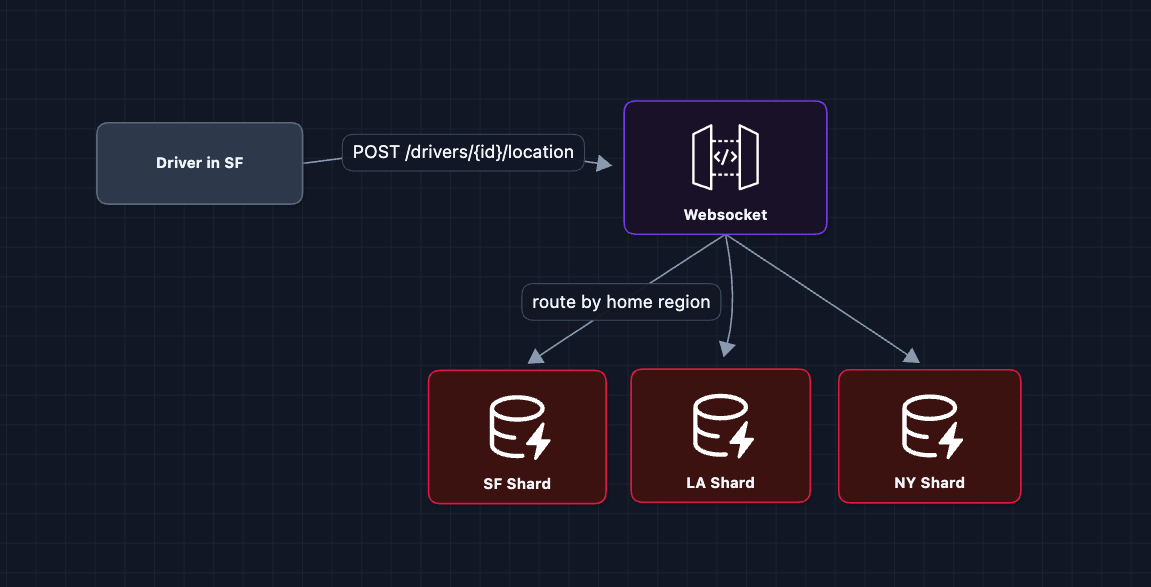
Rides are local. A rider in SF will never be matched with a driver in NYC. This makes regional sharding natural.
4) What if a driver doesn't respond?: FR3
After sending a ride offer, the driver has a limited time to respond. What if they don't?
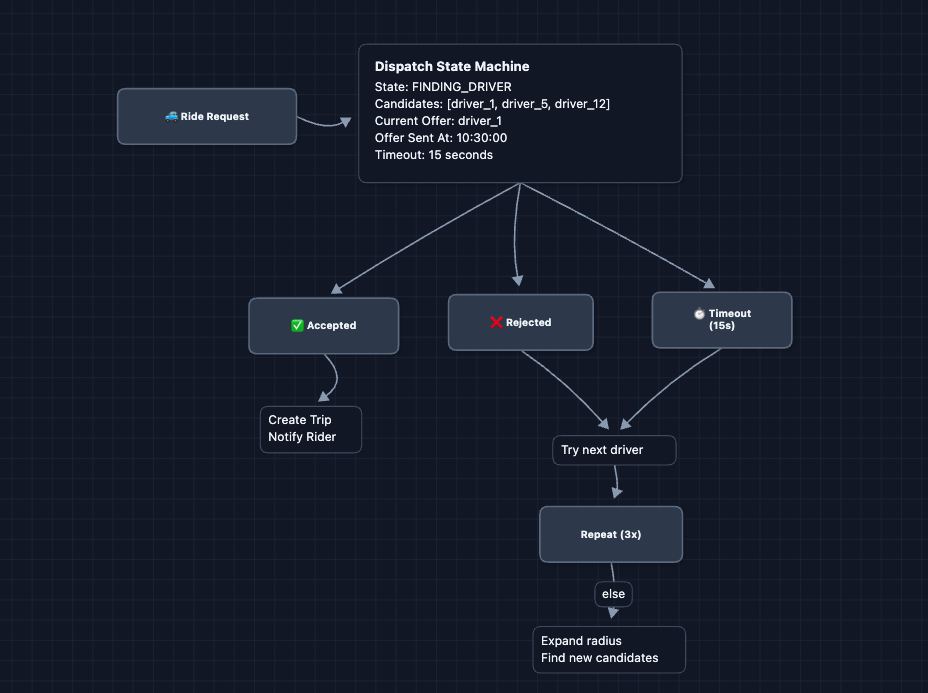
Key design decisions:
- 15-second timeout: It's long enough for driver to notice, but short enough not to frustrate rider
- Max 3 attempts per radius: Don't keep trying the same pool
- Expanding radius: If no one accepts nearby, look further
- Notify rider: Still looking for a driver... keeps them informed
5) What happens when things fail?: NFR3 (Availability)
A critical system needs to handle failures gracefully. Let's examine the most important failure scenarios:
1) WebSocket Gateway failure: We run multiple gateway servers behind a load balancer. If one crashes and clients disconnect, the driver/rider apps automatically reconnect and the load balancer routes them to a healthy gateway.
2) Geo Index (Redis) failure:
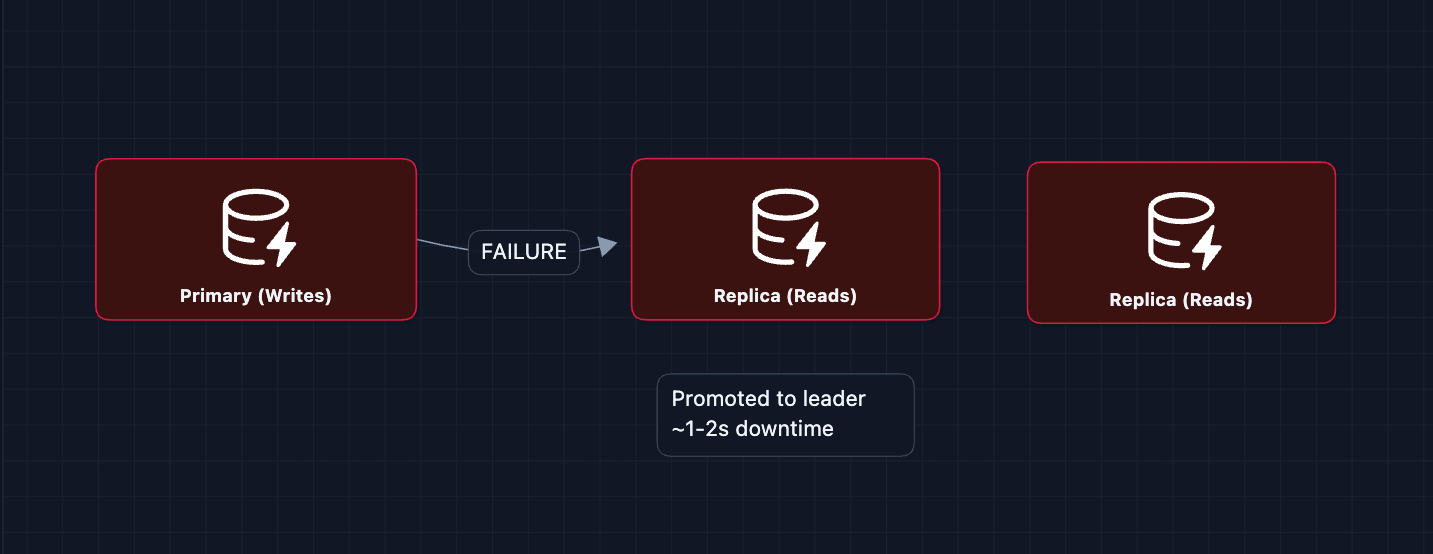
3) Ride Service failure: The service tracks the state of each ride offer (Waiting for Driver 1). It saves this temporary state to a cache (Redis) so that if the service crashes, it can reboot and remember who it was waiting for. This prevents sending duplicate offers to the same driver.
What to Expect?
That was a lot! Here's what matters at each level.
Mid-level
-
Breadth over Depth (80/20). Get the system working: the rider requests, we find nearby drivers, dispatch, and the driver accepts.
-
Expect Basic Probing. How do you find nearby drivers? What happens if the driver rejects? Be ready to explain rebuttals.
-
Assisted Driving. The interviewer will guide you toward the interesting parts. They may push you on scale or real-time updates.
-
The Uber Bar. Complete the basic dispatch flow (the HLD). Understand why location lookups need special indexing. Understand how to scale and what exactly would fail.
Senior
- Balanced Breadth & Depth (60/40): You should naturally identify that find nearby needs geospatial indexing and proactively explain options (Geohash, Quadtree, S2).
- Proactive Problem-Solving: Before the interviewer asks, you lead into What if the driver doesn't respond? How do we handle 250K location updates/second?
- Articulate Trade-offs: Distance-based matching is simple but ETA-based is more accurate. The tradeoff is latency. ETA requires calling a routing service.
- The Uber Bar: Complete the HLD plus 2-3 deep dives: geospatial indexing (Deep Dive 1), matching algorithm (Deep Dive 2), or scale (Deep Dive 3).
Staff
- Depth over Breadth (40/60): Breeze through the high-level flow quickly (~10-15 min to the HLD). Most of the complex problem is in the deep dives.
- Experience-Backed Decisions: You know Redis Geo from real usage. You've dealt with sharding strategies. You can discuss operational concerns (monitoring location freshness, debugging dispatch failures).
- Full Proactivity: You drive the conversation. You identify that regional sharding is natural for ride-hailing before being asked.
- The Uber Bar: Address all deep dives: geospatial indexing, matching algorithms, scale, dispatch retry, and fault tolerance. Discuss how these pieces interact and where the most likely failure points are.
Do a mock interview of this question with AI & pass your real interview. Good luck! 🚗