
Design Twitter
Problem Context
🐦 Twitter (now X) is a real-time microblogging platform where users post short messages called tweets, with 400M+ monthly active users posting 500M+ tweets daily.
Functional Requirements
Twitter has many features, but the timeline is the heart of the product. Adjust scope with your interviewer, but we will focus on the read/write paths.
Core Functional Requirements
- FR1: Users should be able to post tweets (text up to 280 characters, optional media).
- FR2: Users should be able to view their home timeline (tweets from accounts they follow).
- FR3: Users should be able to view any user's profile (their tweets in chronological order).
Out of Scope:
- User authentication and account management.
- Direct messages.
- Notifications and mentions.
- Search and trending topics.
- Retweets, quotes, and replies (treat as regular tweets for simplicity).
- Ads and promoted content.
Non-Functional Requirements
Core Non-Functional Requirements
- NFR1: Home timeline should load in < 300ms.
- NFR2: New tweets should appear in followers' timelines within 5 seconds.
- NFR3: System should be highly available (99.99%+).
- NFR4: System should handle 500M tweets/day writes and 100K+ timeline reads/second.
Here's what we have so far:

Let's build this!
The Set Up
The Main Challenge
When you open Twitter, you see tweets from everyone you follow, sorted by relevance or recency. We need to make this scale to 400M+ users.
The asymmetric follow model creates a unique problem. Celebrities like Elon Musk have 150M+ followers. When he tweets, how do we get that tweet into 150 million timelines within seconds?
Core Entities
Understanding what we're storing helps us reason about data flow. You can jot these down on the whiteboard in your interview.
User
{
userId: "user_123",
username: "elonmusk",
followerCount: 150000000, // useful for fan-out decisions
followingCount: 500
}
Tweet
{
tweetId: "twt_abc789",
authorId: "user_123",
content: "Breaking news: The US has decided to annex Canada 🇨🇦",
mediaIds: ["img_456"], // optional references to media storage
createdAt: "2025-01-09T10:30:00Z"
}
Follow Relationship (asymmetric!)
{
followerId: "user_456", // who is following
followeeId: "user_123" // who is being followed
}
Timeline Cache Entry
{
ownerId: "user_456",
tweetIds: ["twt_abc", "twt_def", "twt_ghi", ...] // ordered list
}
APIs
Let's define what endpoints our clients will call.
Tweet APIs: FR1
1. Post Tweet
POST /api/v1/tweets
Request:
{
"userId": "user_123",
"content": "Hello Twitter!",
"mediaIds": ["img_456"] // optional
}
Response:
{
"tweetId": "twt_abc789",
"createdAt": "2025-01-09T10:30:00Z",
"status": "published"
}
What happens after this? The tweet needs to appear in all followers' home timelines. This is the fan-out problem we'll solve.
Timeline APIs: FR2, FR3
1. Get Home Timeline
GET /api/v1/timeline/home?userId={userId}&limit=20&cursor={cursor}
Response:
{
"tweets": [
{
"tweetId": "twt_xyz",
"authorId": "user_456",
"authorUsername": "naval",
"content": "Specific knowledge is found by pursuing your curiosity",
"createdAt": "2025-01-09T10:25:00Z"
},
// ... more tweets
],
"nextCursor": "cursor_next_page"
}
What's happening? The Timeline Service fetches pre-computed tweet IDs from the user's timeline cache, hydrates them with full tweet data, and returns paginated results.
2. Get User Profile Timeline
GET /api/v1/users/{userId}/tweets?limit=20&cursor={cursor}
Response:
{
"tweets": [...],
"nextCursor": "cursor_next_page"
}
Profile timelines are simpler than home timelines. We just query the Tweets DB filtered by authorId.
High-Level Design
We'll tackle this in two paths: the write path (posting a tweet) and the read path (viewing your timeline). We'll start simple and address problems as they arise.
In your interview, tell the interviewer upfront that you're building a working prototype first before optimizing. That can be done in the deep dive.
1) Starting from Scratch: FR2 (Home Timeline)
When a user opens their timeline, let's just query everything on the fly:
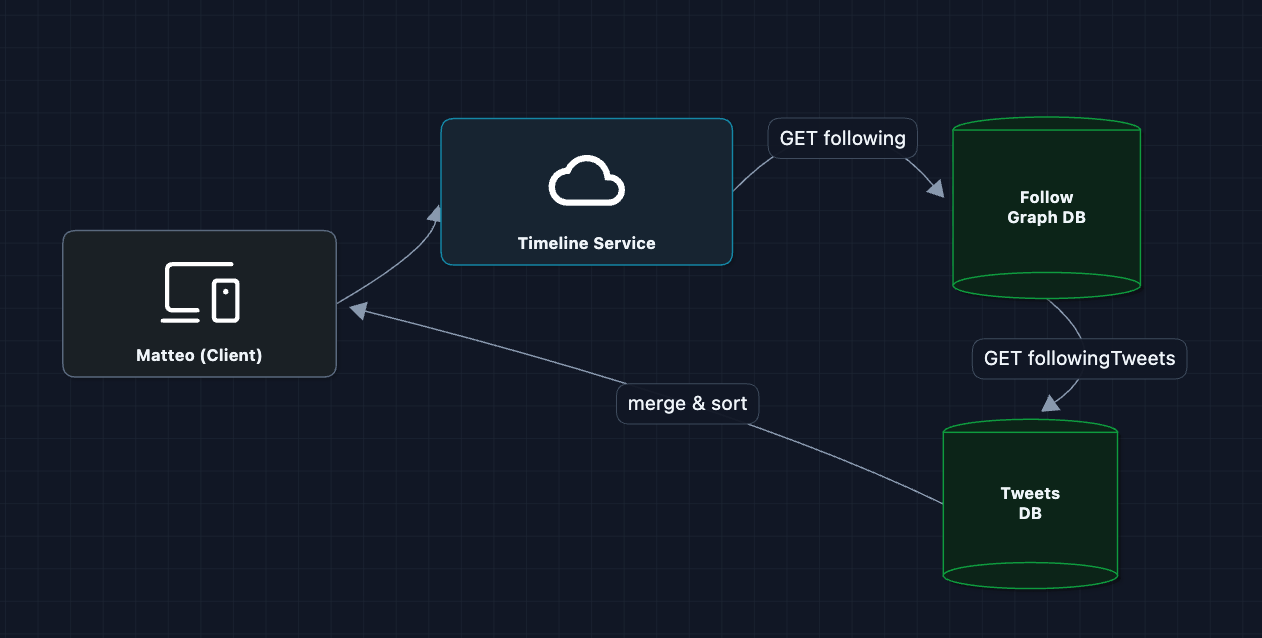
User asks for timeline, we fetch who they follow, grab all those tweets, merge, sort, return. Simple!
Why does this break?
- Latency problem: Matteo follows 400 accounts * 50 recent tweets each = 20,000 rows to fetch and sort per request
- Database hammering: 100K timeline requests/second * 20K rows = 2 billion row reads per second
- Uneven load: Popular times (morning, lunch) spike read load 10x
We can't afford to compute timelines on every request.
2) Cache the Timeline: FR2 (Home Timeline)
Let's store pre-computed timelines in a cache:
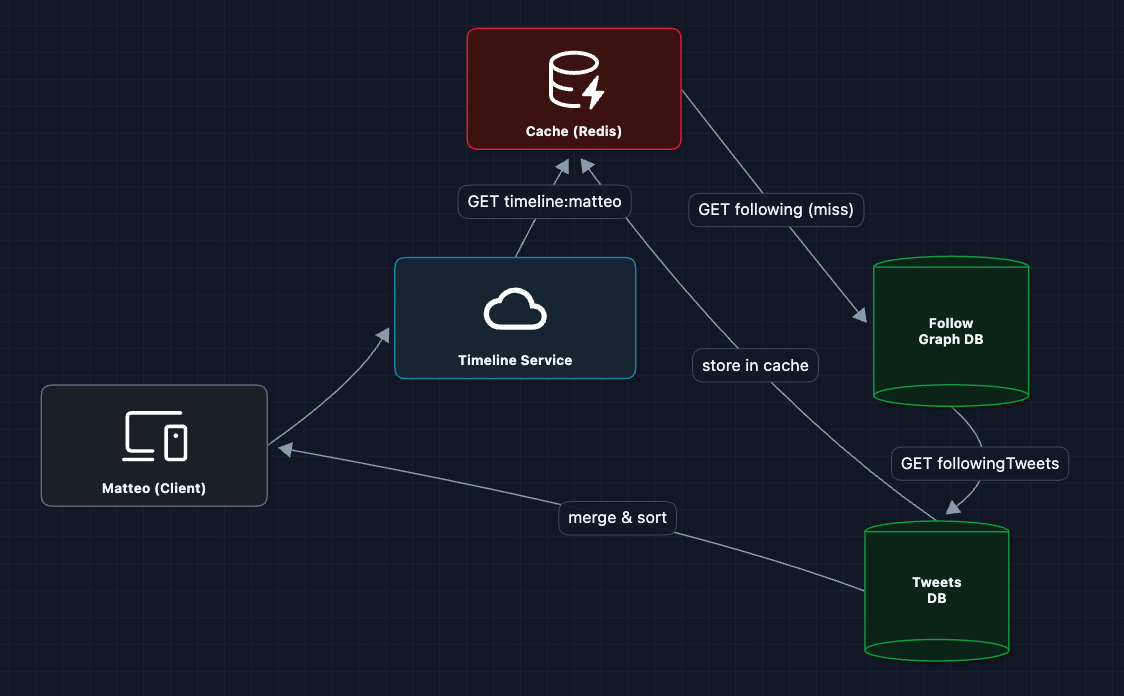
Repeat requests are instant now. Great improvement!
What breaks?
- Stale data: Timeline is cached but new tweets don't appear (violates FR2/NFR2)
- Cache invalidation: When do we update the cache? Every time any followee tweets?
- Cold start: First request after cache expires is still painfully slow
We need tweets to flow INTO timelines proactively.
3) Fan-out on Write: FR1 + FR2 (Tweet Delivery)
Here's the idea: instead of computing timelines when users read, push tweets to timelines when users write.
When Jessica tweets, we immediately add it to all her followers' cached timelines:
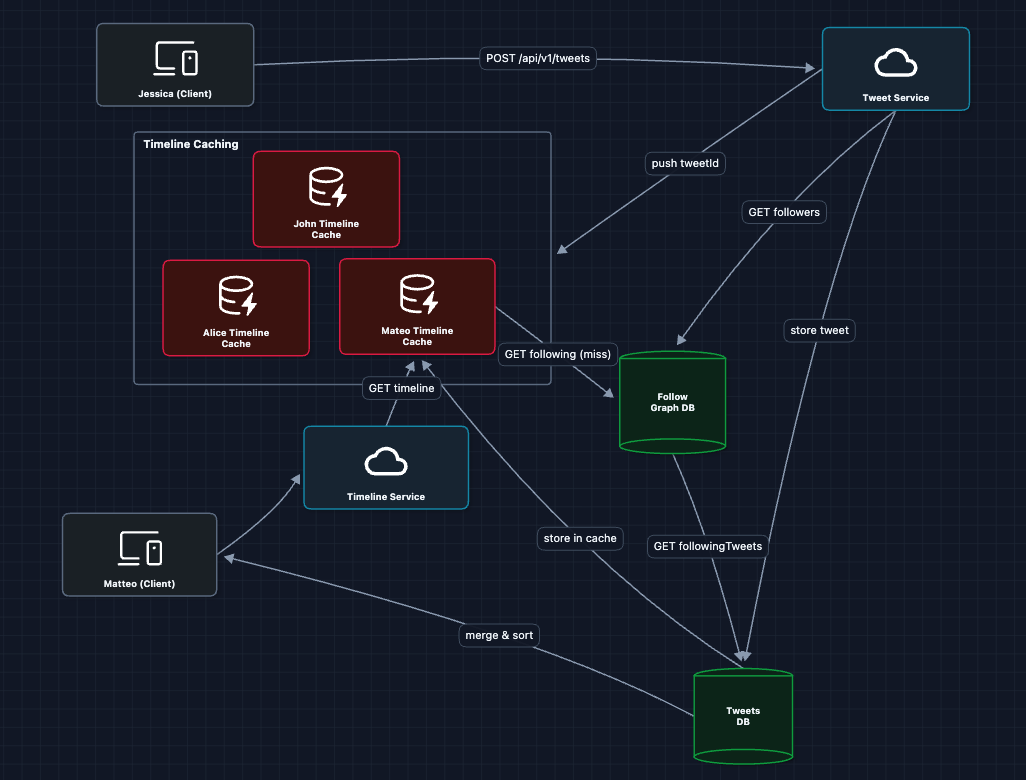
Now when Matteo opens Twitter, Jessica's tweet reference is already waiting in his cached timeline.
There's one massive problem left.
- The celebrity problem: Elon has millions followers. One tweet updates many million timeline caches. That could take hours and consume enormous resources.
This is THE problem that makes Twitter interesting in system design interviews.
4) Hybrid Fan-out: Solving the Celebrity Problem
We can't push to that many timelines every time Elon tweets. But we still want fast delivery for normal users.
The solution: Use different strategies based on follower count.
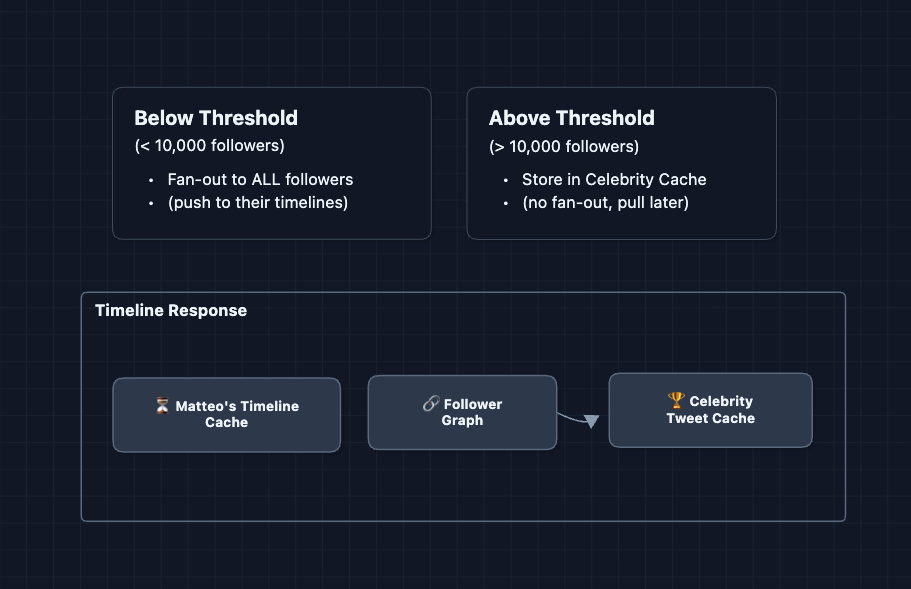
The math:
- Fan-out for normal user (500 followers): ~5ms
- Fan-out for Elon (150M followers): hours, millions of writes
- Pull for 20 celebrities at read time: ~20ms extra
The hybrid approach keeps writes fast while read overhead is minimal.
5) Async Processing with Message Queue: FR1 (Reliability)
Right now, Jessica's tweet isn't confirmed until ALL her followers' timelines are updated.
Let's make fan-out asynchronous:
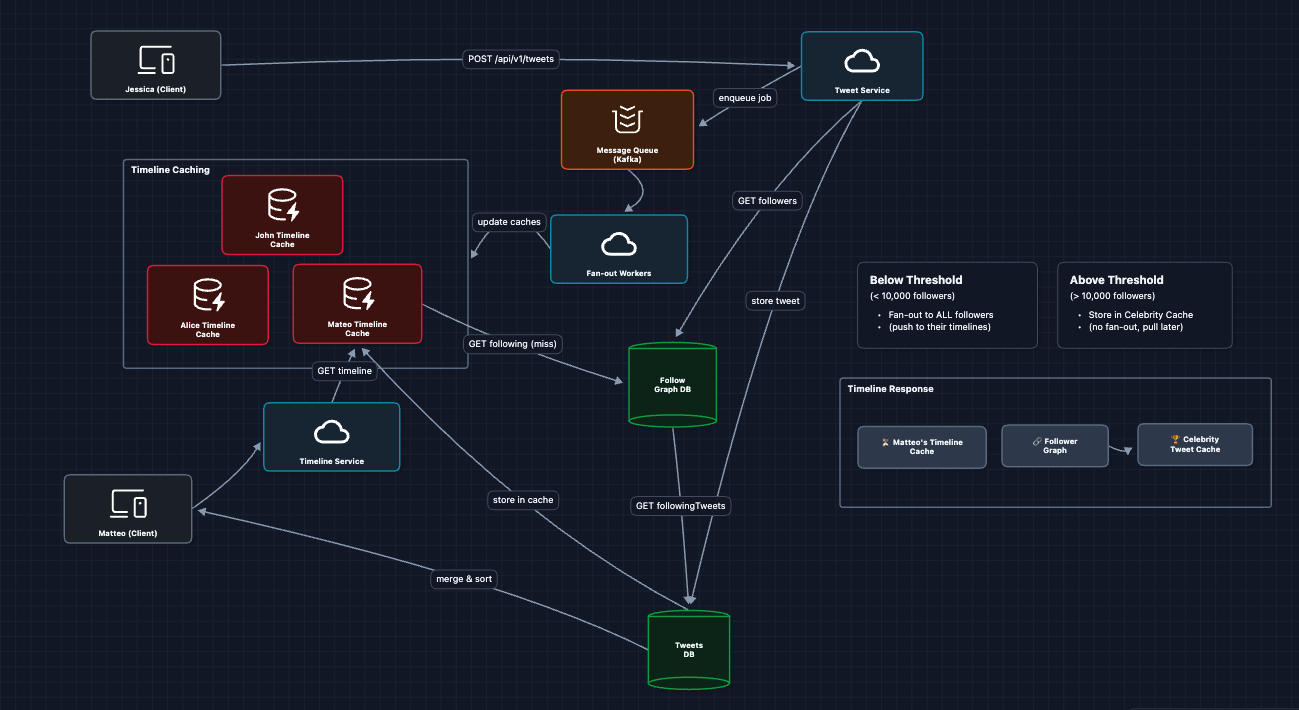
What we added:
- Kafka for durable, partitioned message delivery (partition by
userIdfor ordering, consumer groups for parallel workers) - Fan-out Workers that scale horizontally across partitions
- Decoupling: Jessica gets instant response, and fan-out happens asynchronously
Complete System
This is our baseline architecture!
We now satisfy all functional requirements:
- FR1 ✅ Post tweets (write path)
- FR2 ✅ View home timeline (read path with hybrid fan-out)
- FR3 ✅ View profile timeline (simple query by authorId)
Now we can address our non-functional requirements in the deep dives:
- NFR2 (Freshness): How do we deliver tweets within 5 seconds?
- NFR1 (Latency): How do we serve timelines in < 300ms?
- NFR4 (Scale): How do we handle 500M tweets/day?
- NFR3 (Availability): What happens when components fail?
Potential Deep Dives
1) How do we deliver tweets within 5 seconds?: NFR2 (Freshness)
In the HLD, we use Kafka and fan-out workers. But can we actually hit 5-second delivery?
Let's trace the path:
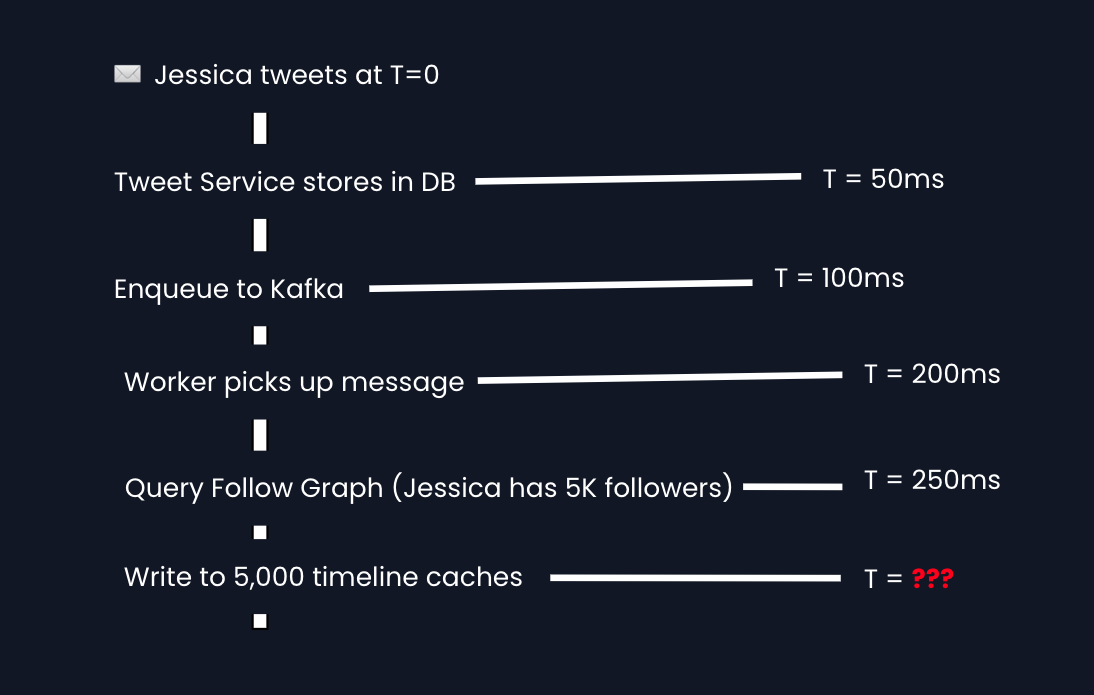
The bottleneck is fan-out writes. If one write takes 1ms, 5,000 writes is 5 seconds just for one user!
Fix: Batch writes and Pipeline commands
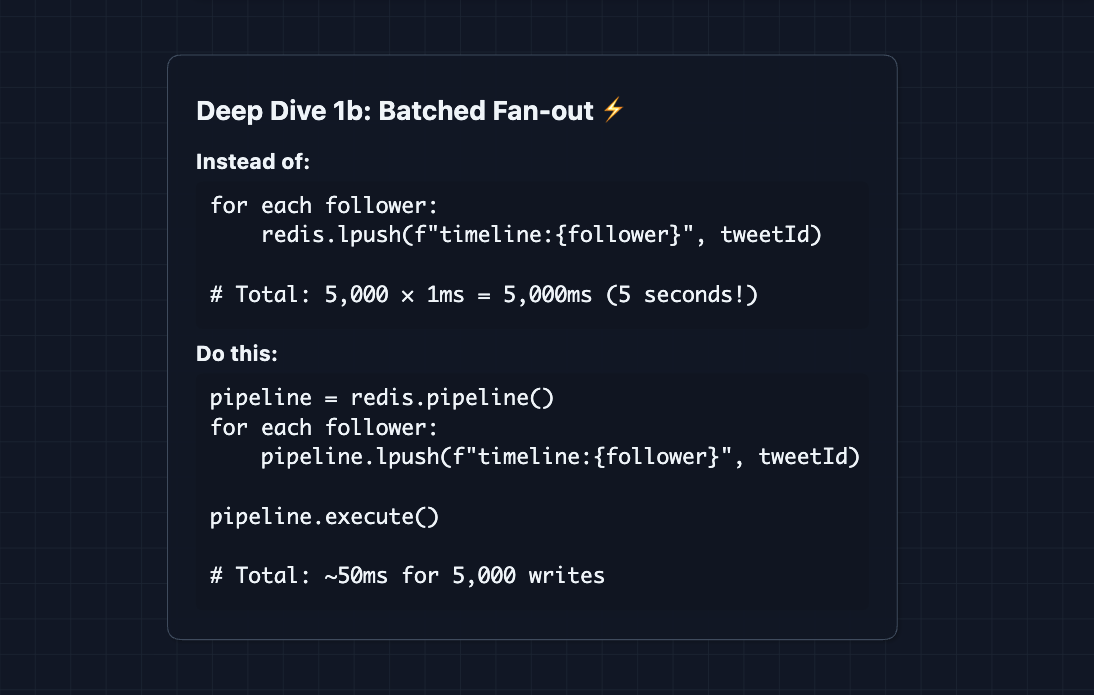
What's pipelining? Instead of sending commands one by one (waiting for response each time), batch them into a single network request. Redis processes all commands and returns all responses at once.
Additional techniques for < 5s delivery:
- Partition followers across workers: Worker 1 handles followers A-M, Worker 2 handles N-Z
- Priority lanes: High-engagement users get fan-out priority
- Geographic sharding: Fans closer to the author's region get updated first
2) What happens during viral moments?: NFR4 (Scale)
Let's say Ronaldo wins the World Cup in 2026 (or Messi again?) ⚽🏆
Millions of users refresh their timelines simultaneously. This is the thundering herd problem.

How do we handle this?
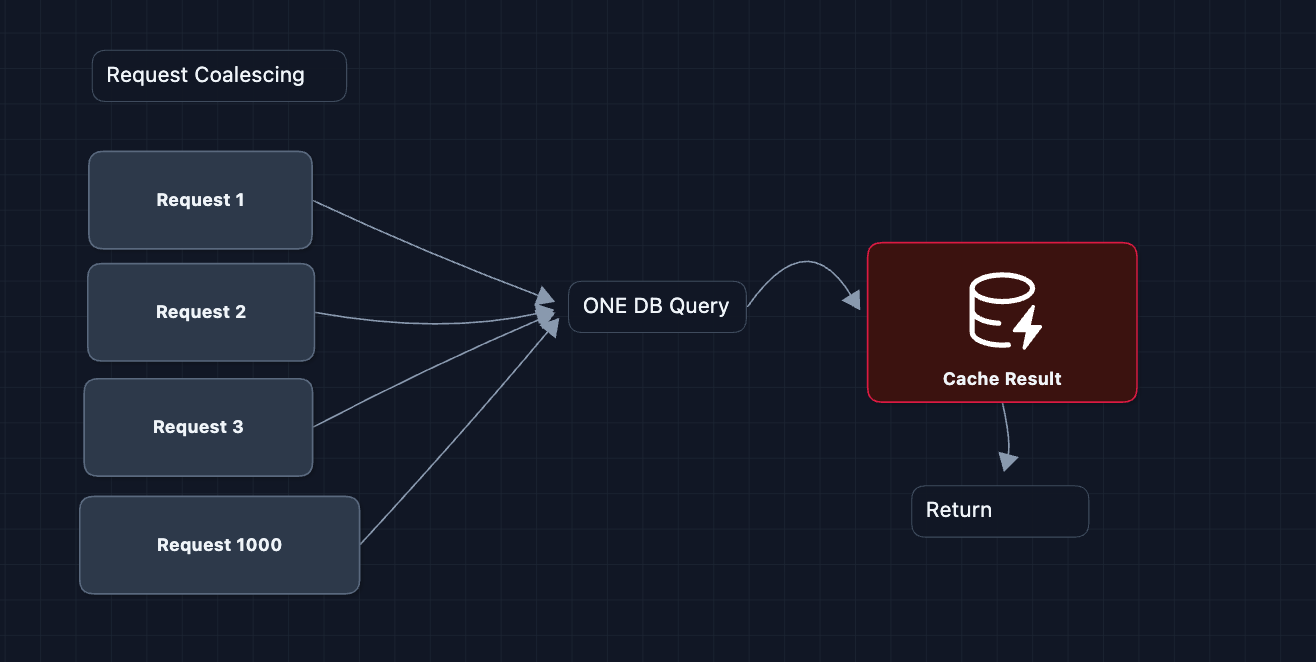
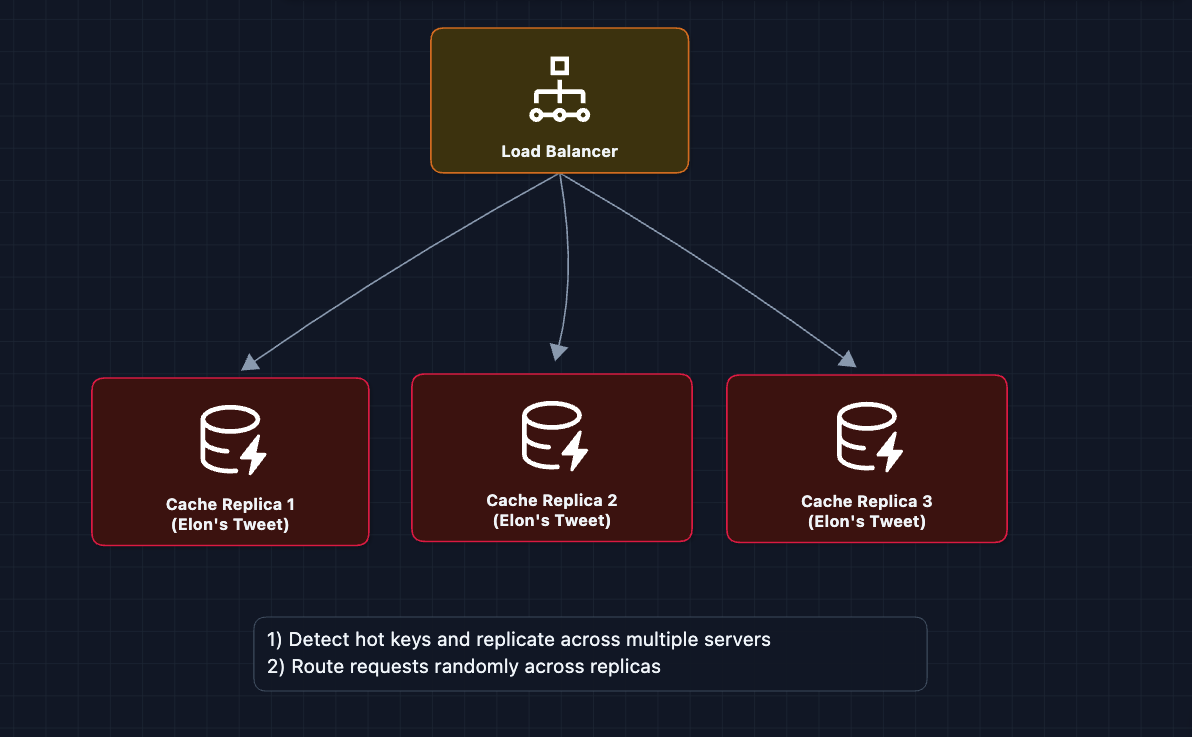
3) How do we handle 500M tweets per day?: NFR4 (Write Scale)
500M tweets/day means around 6,000 tweets/second sustained, with peaks 10x higher during events.
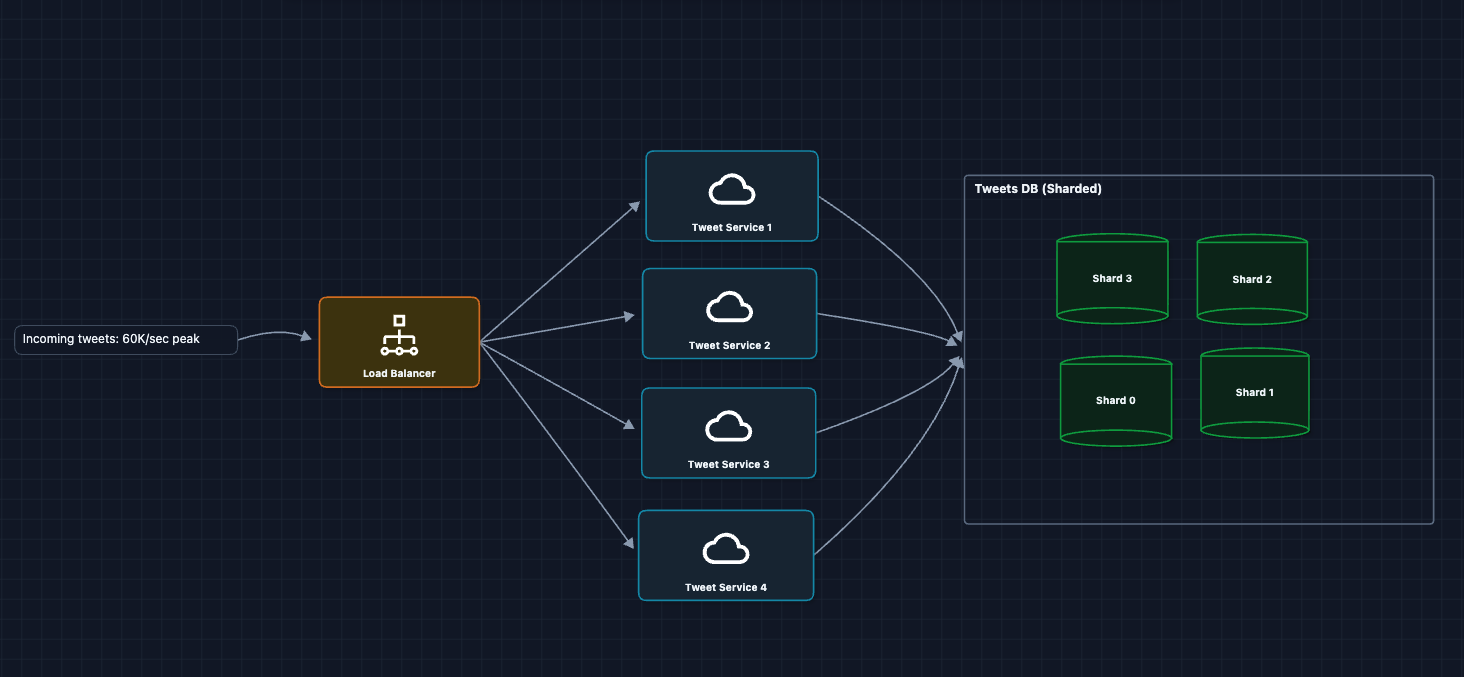
Database Partitioning Strategy:
Option A: Partition by tweetId
- Even write distribution (random IDs spread evenly).
- Profile timeline means query ALL shards.
Option B: Partition by userId
- Profile timeline means query ONE shard.
- Hot users (Elon) means hot shards.
Twitter's Approach:
- Primary: Partition by
tweetIdfor even writes. - Secondary: Add a GSI on
(userId, createdAt)for profile queries.
For details on how consistent hashing minimizes data movement when shards are added/removed, see the Distributed KV Store article.
4) What happens when things fail?: NFR3 (Availability)
Every component can fail. We need graceful degradation.

Every component should have a fallback. A slower or less complete timeline is always better than an error page.
5) How do timeline deletes work?: Data Consistency
When a user deletes their tweet, we need to remove it from potentially millions of timelines.

What's soft delete? Instead of removing the row from the database, set a deleted: true flag. If they want to restore it, they can before the TTL expires.
What to Expect?
That was quite a bit of information! Here's what you should focus on based on level.
Mid-level
- Understand push vs pull. If you can't explain why we pre-compute timelines (Push) instead of querying on every read (Pull), you're not ready. Use the math to explain why.
- Know the basic pipeline. Tweet Service to Kafka to Fan-out Workers and Timeline Caches. Know what each piece does and what they do.
- Be ready for "why Kafka?" It's for durability, decoupling, and async processing. The user doesn't wait for fan-out to complete.
- Minimum bar: Draw a working system that handles normal users. Acknowledge the celebrity problem exists even if you don't fully solve it immediately.
Senior
- Balanced Breadth & Depth (60/40): You should go deeper into areas you have hands-on experience with. Don't just name-drop technologies, but explain how Redis pipelines work and why you chose a specific partitioning key.
- Proactive Problem-Solving: Lead with the Celebrity Problem. Don't wait for the interviewer to ask "what if a celebrity tweets?" Bring it up yourself and propose Hybrid Fan-out (push for normal, pull for celebrities).
- Articulate Trade-offs: You can thoroughly explain pros/cons of architectural choices ("Pull is cheaper for writes but expensive for reads. Push is fast for reads but expensive for writes. We use hybrid to balance this").
- The Twitter Bar: Complete the system for normal users and proactively dive into 2-3 deep dives: Hybrid fan-out math, thundering herd mitigation (cache stampede), or partition strategy trade-offs. You explain how we achieve < 5s delivery using Redis pipelines.
Staff
- Depth over Breadth (40/60): The interviewer assumes you know the basics. Breeze through the high-level design quickly (~15 min) so you have time for what's interesting.
- Experience-Backed Decisions: Talk about operational concerns. How do you detect hot keys in real-time? What is the playbook for Super Bowl traffic? How do you safely roll out a new fan-out strategy without downtime?
- Full Proactivity: You drive the entire conversation. You bring up concerns like consistency across regions, cache warming strategies, and backpressure handling when Kafka backs up.
- The Twitter Bar: Address ALL deep dives without prompting: Hybrid fan-out optimization, Cache warming (rebuilding timelines), Cross-DC replication, and Cost Optimization (storage vs compute). The bread and butter is not just building the base system but explaining the intricacies of scaling the fan-out service.
Do a mock interview of this question with AI & pass your real interview. Good luck! 🐦