
Design Facebook Live Comments
Problem Context
💬 Facebook Live Comments powers the real-time comment stream during live video broadcasts. When a creator goes live, millions of viewers can post and see fast appearingcomments.
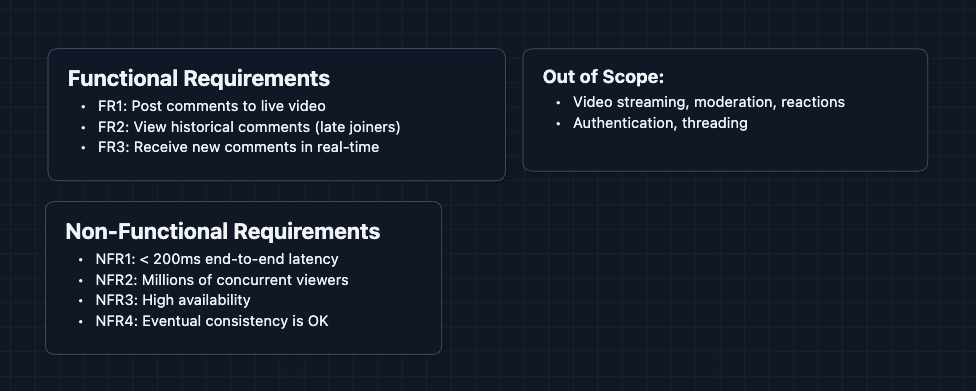
Functional Requirements
The scope of live comments can expand quickly (reactions, replies, moderation). We need to establish boundaries and adjust to what the interviewer wants.
Core Functional Requirements
- FR1: Users can post comments to a live video stream.
- FR2: Users joining late can scroll through historical comments.
- FR3: Users receive new comments in real-time without refreshing.
Out of Scope:
- Video streaming infrastructure (that's a separate system).
- Content moderation and filtering.
- Comment replies and threading.
- User authentication system.
In the design, focus on the core read/write/broadcast paths. Acknowledging other aspects demonstrates your product architecting skill to the interviewer.
Non-Functional Requirements
Core Non-Functional Requirements
- NFR1: End-to-end latency should be < 200ms.
- NFR2: System should scale to millions of concurrent viewers per stream.
- NFR3: System should be highly available even under load.
- NFR4: Eventual consistency is acceptable for comment delivery.
Here's what we have so far:
Let's keep going!
The Set Up
Planning the Approach
Based on our requirements, we have three distinct paths to design:
- Write Path: How a comment gets posted and stored.
- Read Path: How late joiners fetch historical comments.
- Real-time Path: How new comments broadcast to all viewers.
Remember, in the interview you first need to get a working system. Make it clear to your interviewer that you recognize flaws in your design but are trying to get to a prototype.
Defining the Core Entities
For this problem, we have several entities to work with:
- Comment: The actual message (userId, text, timestamp, videoId).
- LiveVideo: The video stream comments are attached to.
- Connection: A persistent connection a viewer holds for real-time updates.
- Channel: A Pub/Sub topic for a specific live video (for fan-out).
API Interface
Our APIs split into three categories matching our paths: Write, Read, and Real-time. Let's define each.
For the interview, you don't have to memorize exact syntax. Focus on the inputs, outputs, and why we use them.
1. Write Path (FR1)
Post a Comment
- Endpoint:
POST /comments/{liveVideoId} - Headers:
Authorization: Bearer <JWT>
Request Body:
{
"message": "This stream is amazing!"
}
Response:
{
"commentId": "cmt_abc123",
"createdAt": "2024-01-15T20:30:00Z"
}
Why is userId not in the body? Security. The userId is extracted from the JWT token in the Authorization header. This prevents users from impersonating others by sending a fake userId.
2. Read Path (FR2)
Fetch Historical Comments
- Endpoint:
GET /comments/{liveVideoId}?cursor=cmt_xyz789&limit=20
Response:
{
"comments": [
{
"commentId": "cmt_xyz788",
"userId": "user_123",
"message": "Hello everyone!",
"createdAt": "2024-01-15T20:29:55Z"
},
...
],
"nextCursor": "cmt_xyz768"
}
Why cursor instead of offset? We'll deep dive into this, but briefly, offset pagination breaks when new comments are constantly being added. Cursor-based pagination is more stable.
3. Real-time Path (FR3)
Subscribe to Live Comments (SSE)
- Endpoint:
GET /comments/{liveVideoId}/stream
Response: (Server-Sent Events stream)
event: comment
data: {"commentId":"cmt_new1","userId":"user_456","message":"Wow!","createdAt":"..."}
event: comment
data: {"commentId":"cmt_new2","userId":"user_789","message":"Amazing!","createdAt":"..."}
... (connection stays open, server pushes new comments)
What is SSE? Server-Sent Events is a standard for one-way server-to-client push over HTTP. The client opens a connection, and the server sends events whenever they occur. We'll discuss why we chose SSE over WebSockets in the deep dive.
High-Level Design
Let's start with our functional requirements:
- FR1: Post comments to live video
- FR2: View historical comments
- FR3: Receive new comments in real-time
For the sake of explanation, we'll start with the simplest possible design and incrementally improve it. In an interview, you can start with Diagram 2.
1) The Simplest System: FR1, FR2
Let's start with the most naive approach. Users poll the database for new comments.
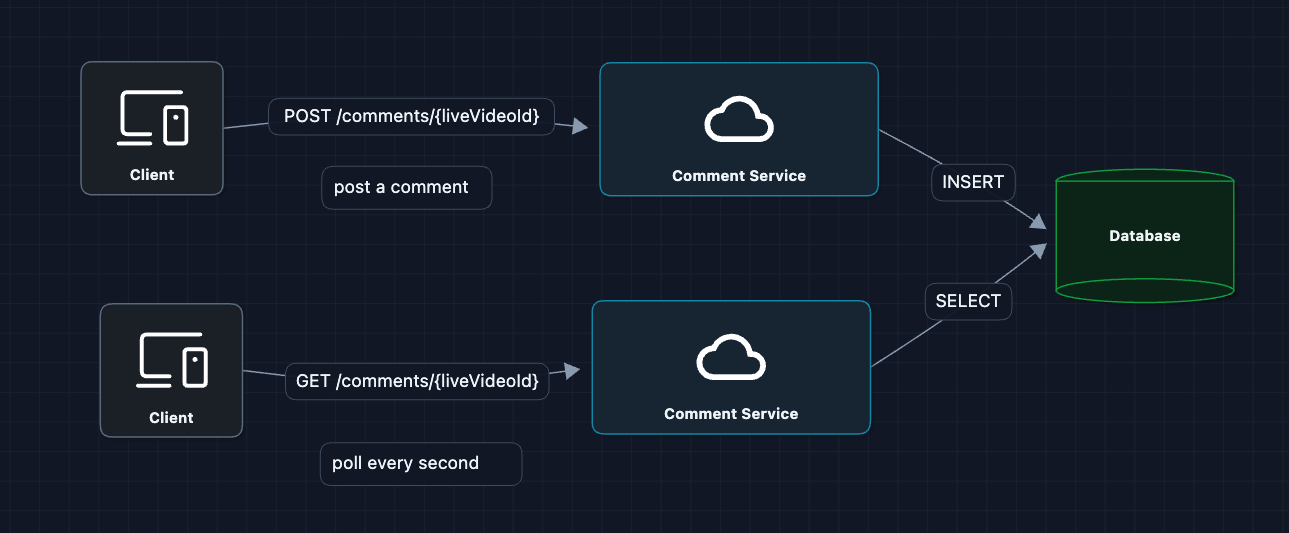
This technically works for a small scale.
But what breaks?
- Latency: Polling every 1 second means up to 1 second delay on average.
- Database load: 1 million viewers * 1 request/second = 1M queries/second!
- Wasted work: Most polls return empty (no new comments).
We need a way for the server to push comments to clients.
2) Replace Polling with Push (SSE): FR3
Instead of clients asking repeatedly, we keep a connection open and the server pushes comments when they arrive:
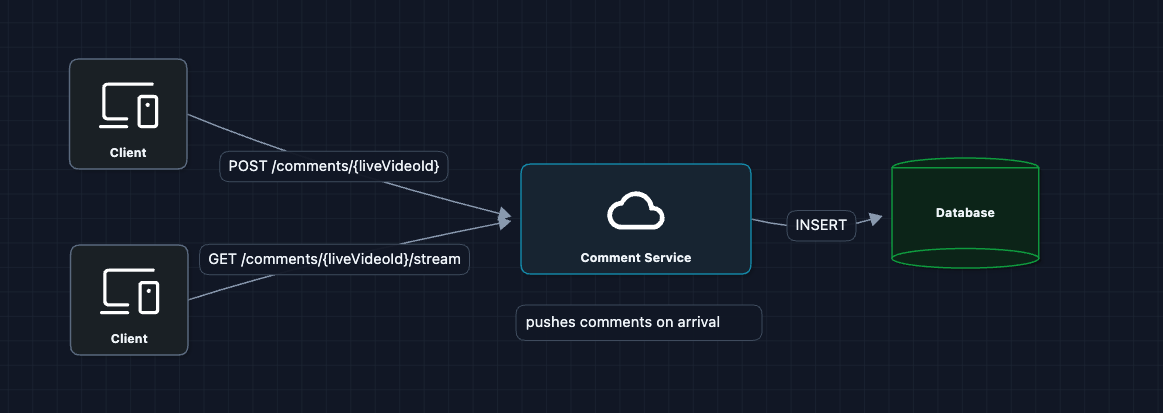
This logic handles the latency problem. Comments are pushed immediately.
But what breaks at scale?
The diagram above treats Comment Service as a black box. That box however is a cluster of hundreds of servers.
- Server A might handle the POST request.
- Server B might hold the connection to the Viewer.
- Since servers don't share memory, Server A enters the comment into the DB, but Server B never knows it happened.
We need a way for Server A to broadcast the message to Server B (and C, D, E...).
3) Add Pub/Sub for Cross-Server Communication: FR3 ✅
We introduce a Pub/Sub system. Every server subscribes to channels for the videos its viewers are watching:
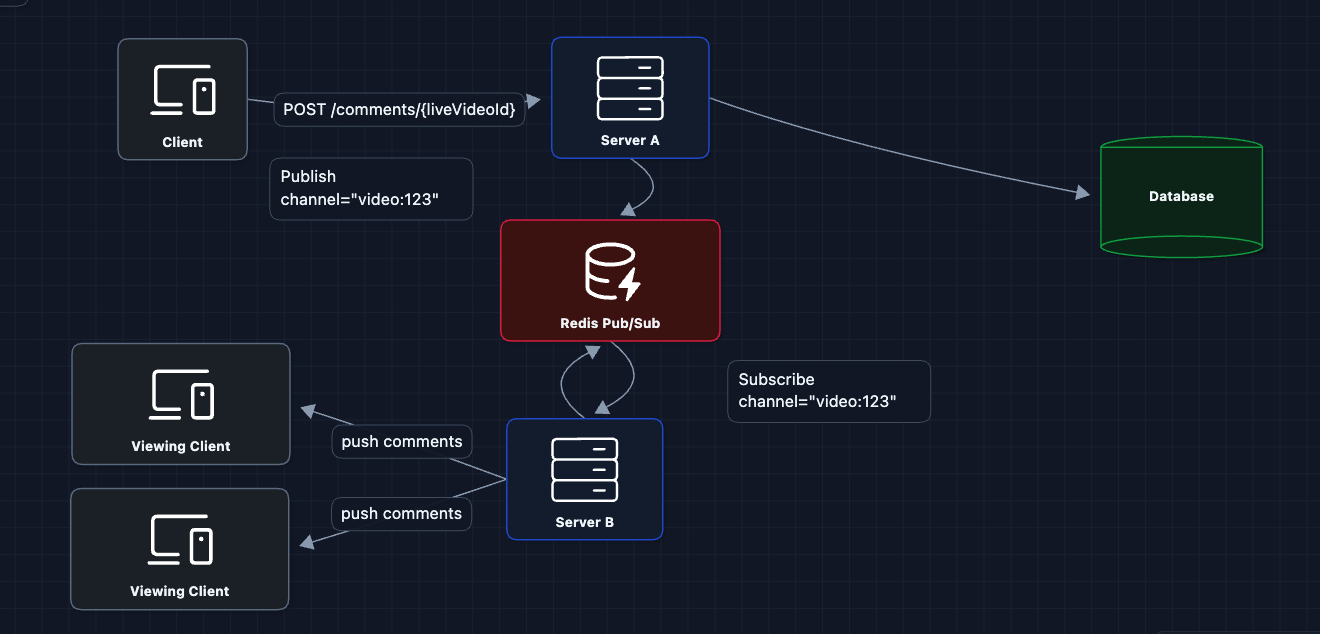
Now we have real-time fan-out across servers!
Let's consider the read path for late joiners.
4) Add Historical Read Path: FR2 ✅
They call GET /comments/{liveVideoId} to fetch past comments, then open an SSE connection for new ones:
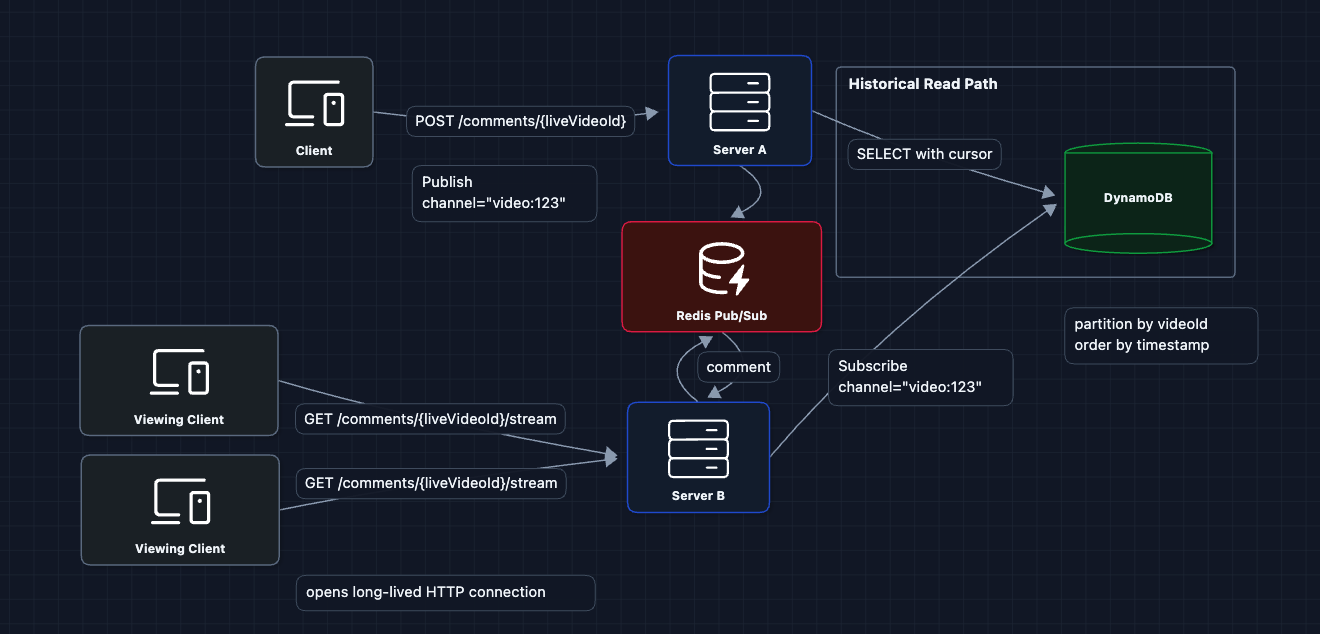
Why DynamoDB? Briefly, it offers high availability and scales horizontally. For comments (simple key-value data), we prioritize availability over strong consistency.
5) Complete System
This is our baseline architecture. It satisfies all functional requirements:
- FR1 ✅ Post comments (Write Path)
- FR2 ✅ Historical comments (Read Path)
- FR3 ✅ Real-time delivery (Pub/Sub and SSE)
Now we can address our non-functional requirements and more in the deep dives:
- NFR1 (Latency < 200ms): Why SSE? Why cursor pagination?
- NFR2 (Scale): How do we handle millions of viewers?
- NFR3 (Availability): Why DynamoDB? CAP trade-offs?
- NFR4 (Consistency): What about message ordering?
Potential Deep Dives
1) Why SSE over WebSockets or Polling?: NFR1 (Latency)
In Diagram 2, we switched from polling to SSE. But why SSE specifically? Let's compare the options:
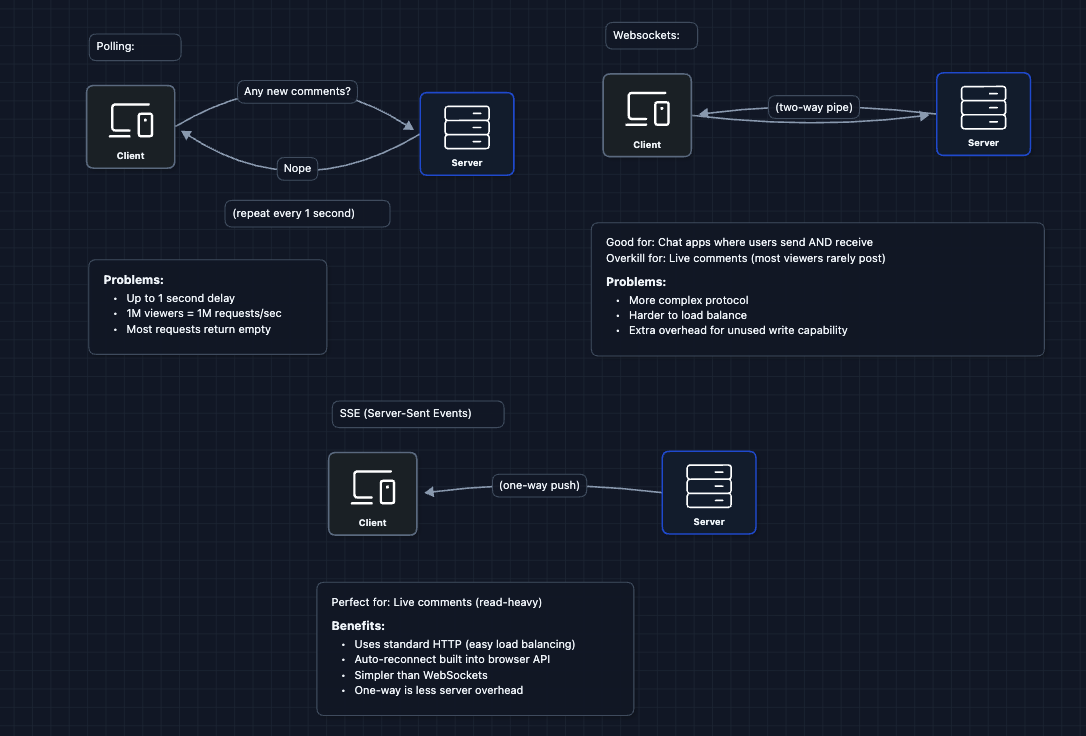
Live comments are read-heavy. For every person posting, thousands are just watching. SSE is optimized for this pattern.
2) Cursor vs Offset Pagination: NFR1 (Latency)
We use cursor pagination for fetching comment history when a late joiner scrolls back UP to see older messages. Here is why:
-
Offset is slow and unstable:
- Saying
OFFSET 10000forces the database to count through 10,000 requests just to discard them. This isO(N)and gets slower the more you scroll. - If a new comment arrives while you are reading, the offset shifts, causing you to see duplicate comments.
- Saying
-
Cursor is fast (
O(1)):- We say "Give me 10 comments after comment
cmt_123". - The database jumps directly to
cmt_123using an index and reads the next 10 items. This is instant, no matter how many comments exist.
- We say "Give me 10 comments after comment
DynamoDB naturally uses cursors (called LastEvaluatedKey). It doesn't even support efficient offset pagination.
3) Why DynamoDB?: NFR3, NFR4 (Database Choice)
The CAP Trade-off:
- We prioritize Availability (A) over strict Consistency (C). It is better for a user to see a comment 500ms late (Eventual Consistency) than to see an error message.
Why DynamoDB:
- Horizontal Scale: Handles bursty write traffic (viral live streams) better than SQL.
- Schema Fit: Comments are simple Key-Value data (
VideoIDto get the List of Comments). - Built-in features: TTL (auto-delete old comments), Streams (triggers), and Global Tables.
Table Schema:
- Partition Key:
videoId(Groups all comments for one stream together). - Sort Key:
timestamp(Keeps them chronologically ordered).
To understand how NoSQL databases like DynamoDB distribute data across nodes using Consistent Hashing, check out the deep dive in the Distributed KV Store article.
4) Pub/Sub at Scale: NFR2 (Millions of Viewers)
In Diagram 3, we use Redis Pub/Sub. But how does it perform at scale?
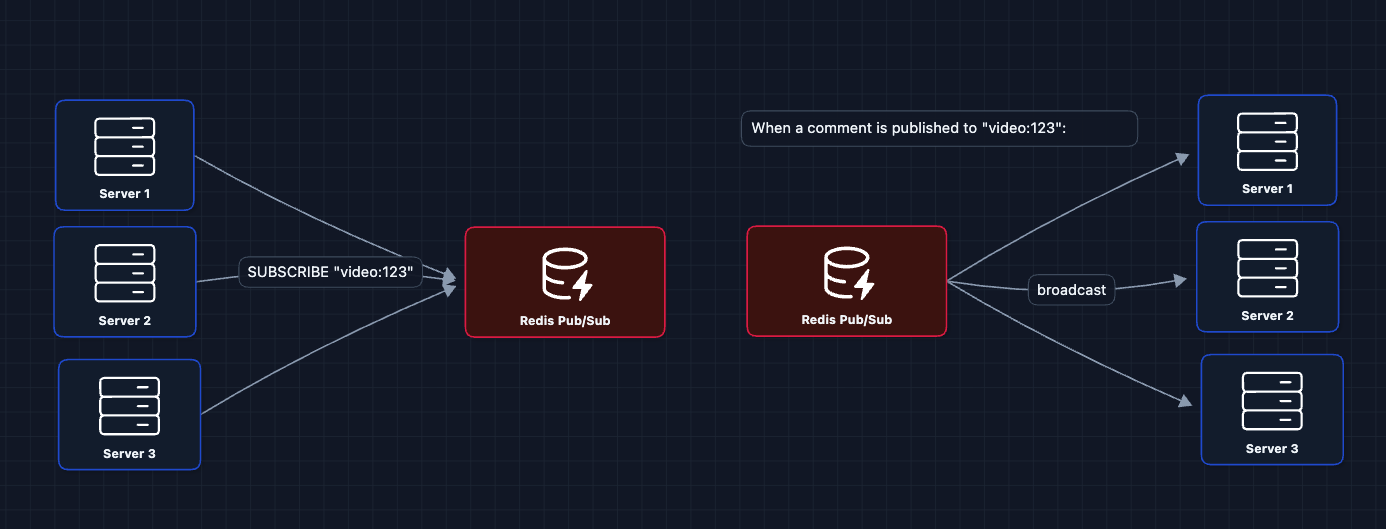
Why Redis Pub/Sub is fast:
- In-memory (no disk writes)
- Fire-and-forget (no acknowledgments required)
- Simple protocol (just string messages)

5) Handling Celebrity Streams: NFR3, NFR2
When a celebrity goes live, millions watch. How do we handle this?

Batching trade-off: Batching adds up to 100ms latency but dramatically reduces server load. For celebrity streams where comments fly by anyway, users won't notice.
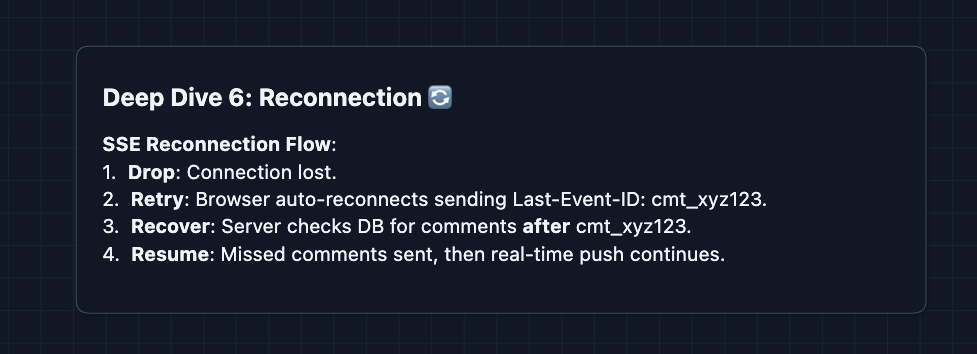
6) Connection Management: NFR3
What happens when SSE connections drop?
What to Expect?
That was a whole lot! Let's break down what you really need to cover in an interview.
Mid-level
- Breadth over Depth (80/20): Focus on connecting the main components: write path, read path, and real-time path. Know that Pub/Sub enables cross-server communication, even if you can't explain Redis internals.
- Expect Basic Probing: The interviewer won't assume you know everything. Expect questions like "Why not just poll?" or "What is Pub/Sub doing here?"
- Assisted Driving: You lead the initial design, but the interviewer will guide you through bottlenecks you might miss.
- The Bar: Complete the HLD with all three paths working. Explain why polling is bad and why SSE is better. Understand cursor pagination and what happens if someone has to reconnect.
Senior
- Balanced Breadth & Depth (60/40): Go deeper into areas you know. Explain how Redis Pub/Sub works and its limitations.
- Proactive Problem-Solving: Identify bottlenecks before asked. "This works, but at celebrity scale we'd need batching..."
- Articulate Trade-offs: You can explain pros/cons intelligently. "Redis is fast but not durable. Kafka is durable but adds latency. For comments, I'd pick Redis because..."
- The Bar: Complete the full system and proactively dive into 2-3 deep dives: SSE vs WebSockets, cursor vs offset, Pub/Sub at scale. Discuss DynamoDB table design.
Staff
- Depth over Breadth (40/60): Move quickly through the basics (~10 min for the HLD). Spend time on what's interesting: fan-out patterns, connection management, hot partition handling.
- Experience-Backed Decisions: Draw on real experience. "I've seen Redis Pub/Sub work up to 100K msg/sec, beyond that we'd shard..."
- Full Proactivity: You drive the entire conversation. The interviewer intervenes only to focus or redirect, not to steer.
- The Bar: Address ALL deep dives as you go. Discuss edge cases: What if Redis dies mid-stream? What if a celebrity stream fails a single partition of DynamoDB? The bread and butter is not just building the system but stress-testing it mentally.
Do a mock interview of this question with AI & pass your real interview. Good luck! 💬