
Design YouTube
Problem Context
📹 YouTube is the world’s largest video-sharing platform, with 500+ hours of video uploaded every minute and over 1 billion hours watched daily.
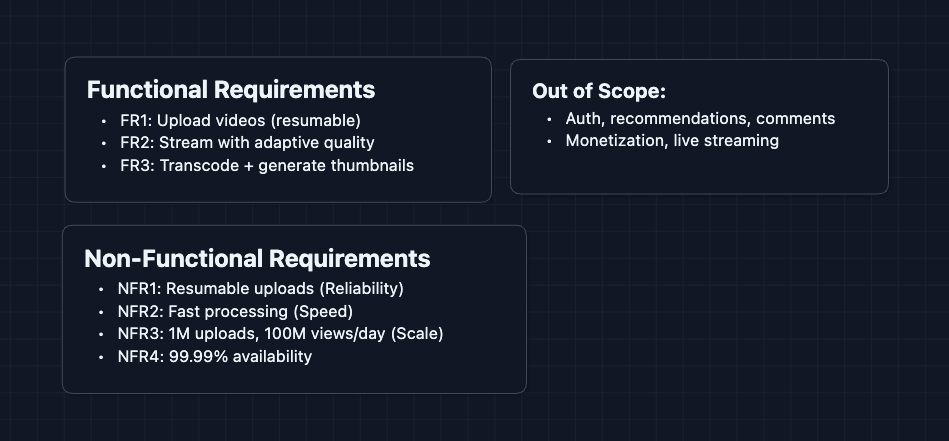
Functional Requirements
YouTube is a creator platform. Anyone can upload, which means we're dealing with untrusted, variable-quality content at massive scale. First of all, clarify the scope with your interviewer.
Core Functional Requirements
- FR1: Creators should be able to upload videos.
- FR2: Viewers should be able to stream videos with adaptive quality.
- FR3: The system should transcode videos and generate thumbnails automatically.
Out of Scope:
- User authentication and channel management.
- Recommendation algorithm (YouTube's ML system is its own beast).
- Comments, likes, and social features.
- Monetization and ads.
- Live streaming.
Listing what's out of scope shows the interviewer you understand the system's breadth without getting lost in it.
Non-Functional Requirements
Core Non-Functional Requirements
- NFR1: Uploads should be resumable (network failures shouldn't break uploading)
- NFR2: Time from upload to playback-ready should be minimized
- NFR3: System should handle 1M+ uploads/day and 100M+ views/day
- NFR4: Videos should remain available (99.99%+ uptime)
Here's what we have so far:
Let's build this system.
The Set Up
Planning the Approach
YouTube a few distinct paths that we need to design:
- The Upload Path: How creators get video files into our system, and how we process them.
- The Watch Path: How viewers retrieve and stream those videos globally.
In an interview, start with basics and acknowledge limitations in your approach to the interviewer. Refinements come later in your deep dive. A working system is more important than a perfect system.
Defining the Core Entities
- Video: Metadata about the video (title, creator, duration).
- Raw File: The original uploaded file before processing.
- Segment: A small chunk of processed video (~4 seconds) that can be fetched independently.
- Manifest: A text file that indexes all segments and available quality levels.
- Chunk: A piece of the raw upload (used for resumable uploads).
API Interface
Our APIs serve two audiences: Creators (uploading) and Viewers (watching).
Focus on the purpose of each endpoint rather than exact syntax. You should jot these down on the whiteboard in an interview.
Upload APIs (Creators): FR1
Handles getting video files into the system safely.
1. Request Upload URL
POST /api/videos/presigned-url
Returns presigned URLs for a multipart upload, allowing the client to upload directly to S3.
// Request
{ "title": "My Travel Vlog", "fileSize": 524288000 }
// Response
{
"videoId": "vid_x7k9m2",
"uploadId": "upl_abc123",
"presignedUrls": ["https://s3.aws.com/.../part1", "https://s3.aws.com/.../part2"]
}
2. Upload Chunks (Direct to S3)
PUT {presigned_url}
The client uploads bytes directly to blob storage (S3). Our servers are bypassed for data transfer.
3. Complete Upload
POST /api/videos/{videoId}/complete
Triggers the processing pipeline (transcoding DAG) after all chunks are successfully uploaded.
// Request
{ "uploadId": "upl_abc123", "parts": [{"part": 1, "etag": "abc..."}] }
Playback APIs (Viewers): FR2
Called by the YouTube player on devices.
1. Get Video Metadata & Manifest
GET /api/videos/{videoId}
Returns video details and the master manifest URL.
// Response
{
"title": "My Travel Vlog",
"manifestUrl": "https://cdn.youtube.com/vid_x7k9m2/manifest.m3u8"
}
2. Fetch Segments (CDN)
GET https://cdn.youtube.com/.../segment_042.ts
The player requests these ~4s chunks repeatedly. These requests hit the CDN edge, not our origin servers.
High-Level Design
Let's build toward our functional requirements:
- FR1: Upload videos
- FR2: Stream with adaptive quality
- FR3: Transcode + generate thumbnails
We'll start simple and incrementally add complexity for the sake of explaining. In an interview, you could begin at Diagram 2 or 3.
1) Starting Simple: A Server with Storage
The most basic system is users upload to a server, and viewers download from it.
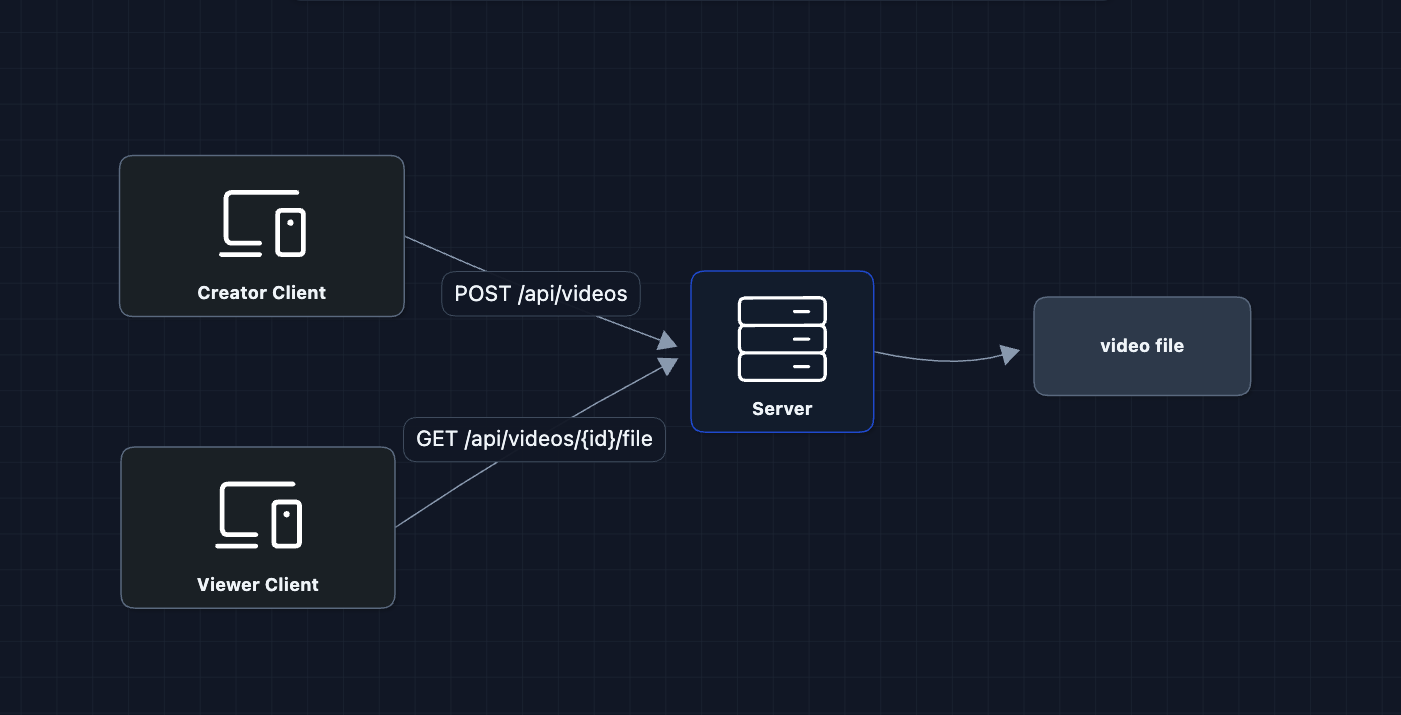
This works for a few users
But what breaks?
- Server disk fills up (videos are huge)
- One server can't handle many concurrent uploads/downloads
- If the server dies, all videos are lost
We need to separate storage from compute.
2) Add Object Storage: FR1, FR2
Move video files to dedicated blob storage (like S3):
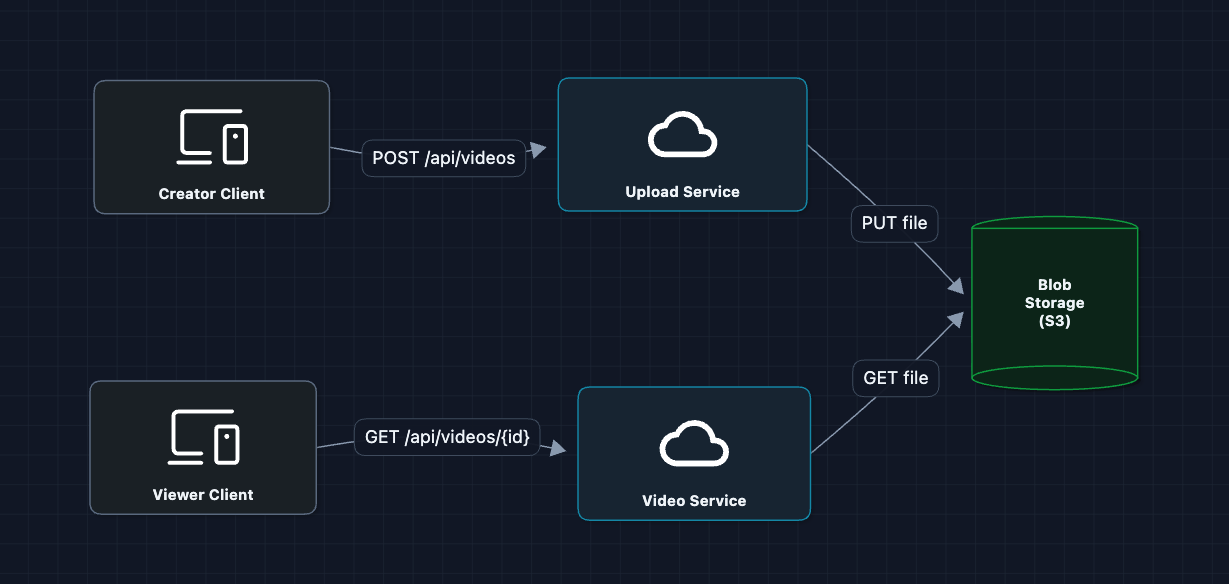
This is better! S3 can store petabytes and handles durability.
But what breaks?
- Uploads still go through our server (bottleneck for large files)
- No metadata storage (how do we know what videos to fetch?)
- Viewers far from the S3 region experience high latency
3) Direct Upload with Presigned URLs: FR1
Let creators upload directly to S3, bypassing our servers:
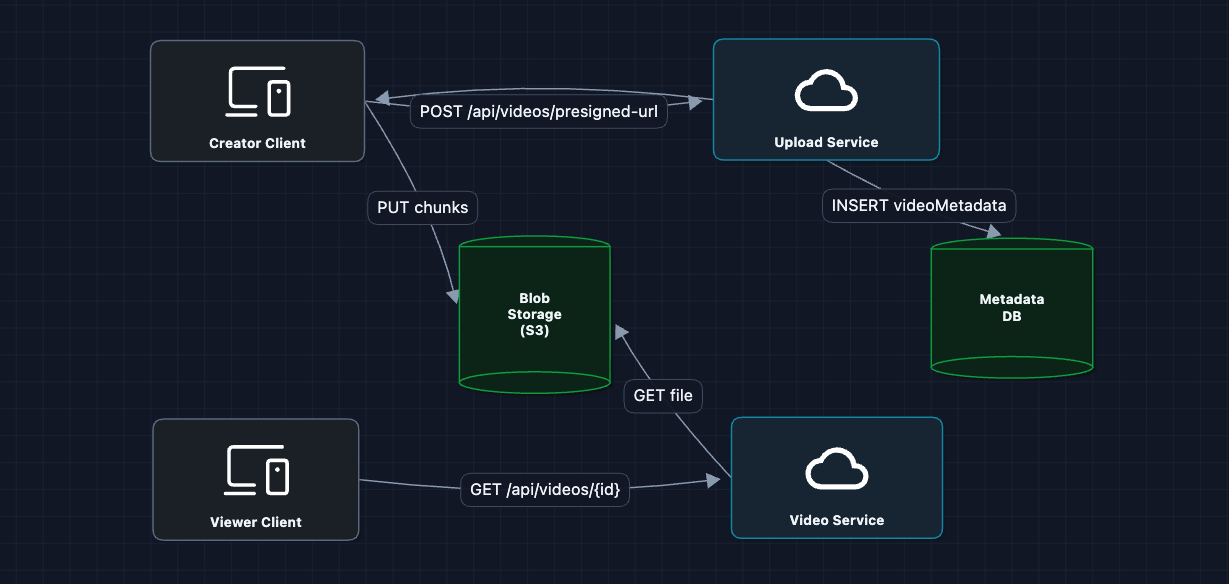
Chunks here are for resumable upload (split by bytes), and S3 merges them into one raw file. Processing later splits by time because video must be cut at keyframes for valid playback.
The video bytes never touch our API servers. A 2GB upload goes straight to S3. Our servers just coordinate.
But what breaks?
- We store raw files, but viewers need processed formats (different resolutions, codecs)
- We need thumbnails for the UI
- The raw file format might not be playable on all devices
We need a processing pipeline.
4) Add the Processing Pipeline: FR3
When a video is uploaded, we need to transcode it into multiple formats:
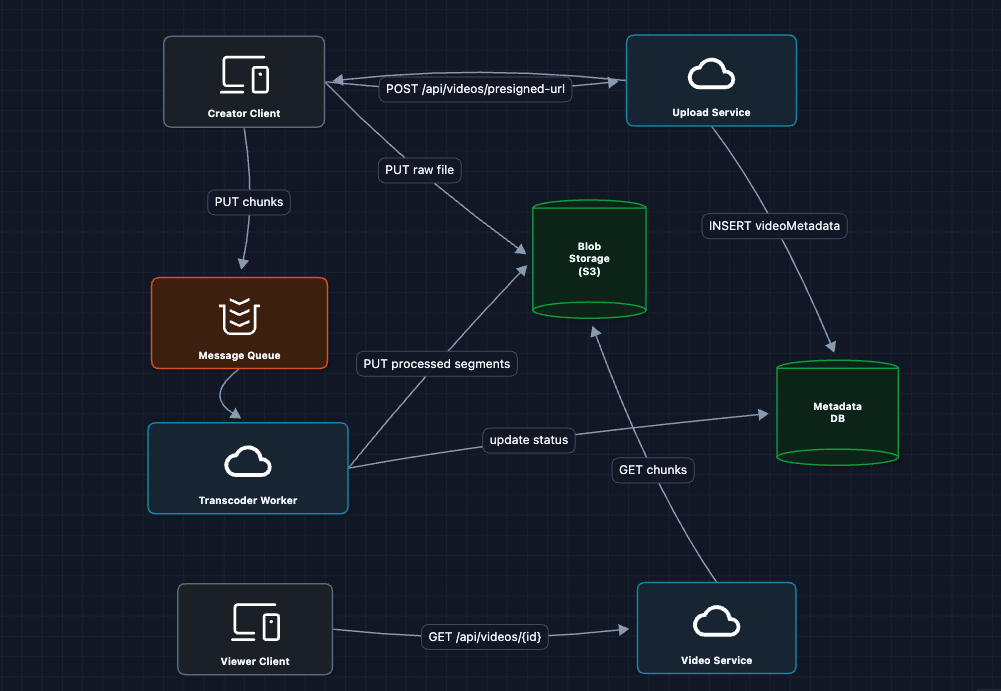
The processing flow:
- S3 emits
ObjectCreatedevent when upload completes - Event goes to a message queue
- Transcode workers pick up jobs and process the video
- Workers output: multiple resolutions, manifest file, thumbnail
- Workers update DB:
{status: "ready", qualities: [...]}
We upload the raw file to S3, and the processing workers fetch just the timestamps they need for their chunk and save those.
What breaks?
- A single worker processing a 2-hour video takes forever
- Viewers still fetch from origin S3 (latency issues globally)
5) Parallelize Transcoding with DAG: FR3 ✅
Instead of one worker processing the whole video, we split the work:
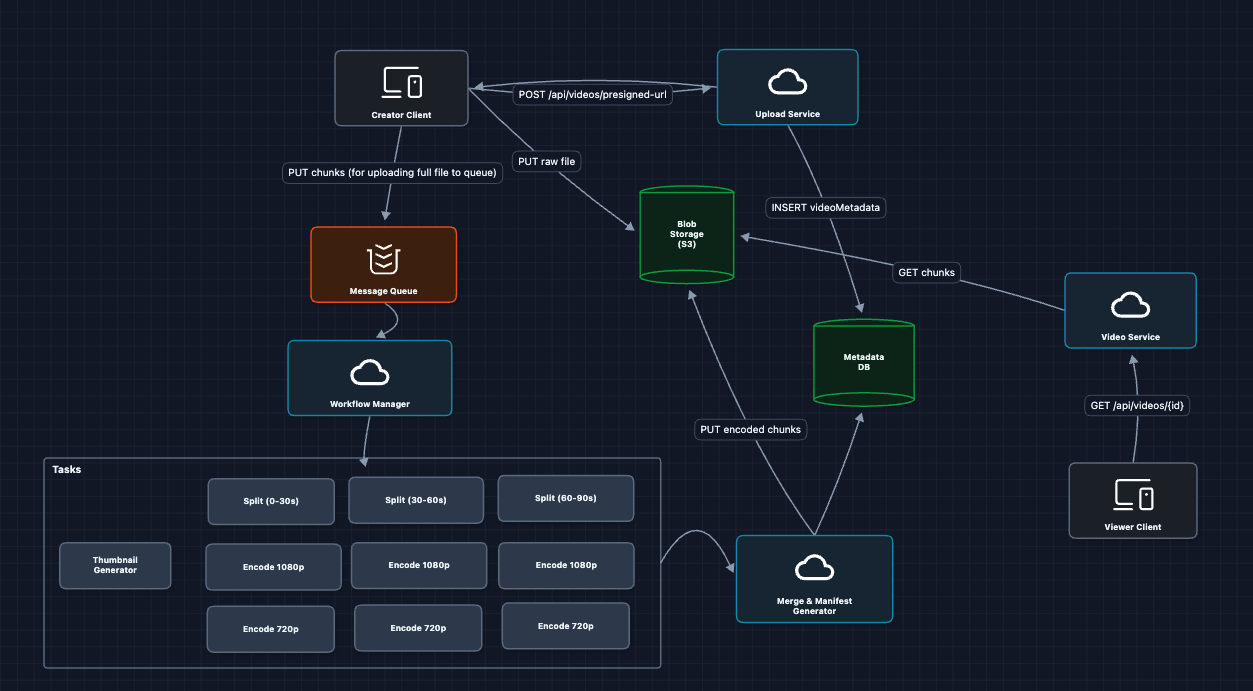
DAG (Directed Acyclic Graph) Explained:
- Split: Chop the raw video into small time ranges
- Encode: Convert each chunk into multiple resolutions (runs in parallel)
- Merge: Combine outputs and generate the manifest file
A tool like Temporal or AWS Step Functions orchestrates this DAG. It handles retries, parallelism, and tracks which tasks completed.
What previously took hours now takes minutes because hundreds of workers process chunks simultaneously.
6) Add CDN for Global Delivery: FR2
Viewers need fast access regardless of location:
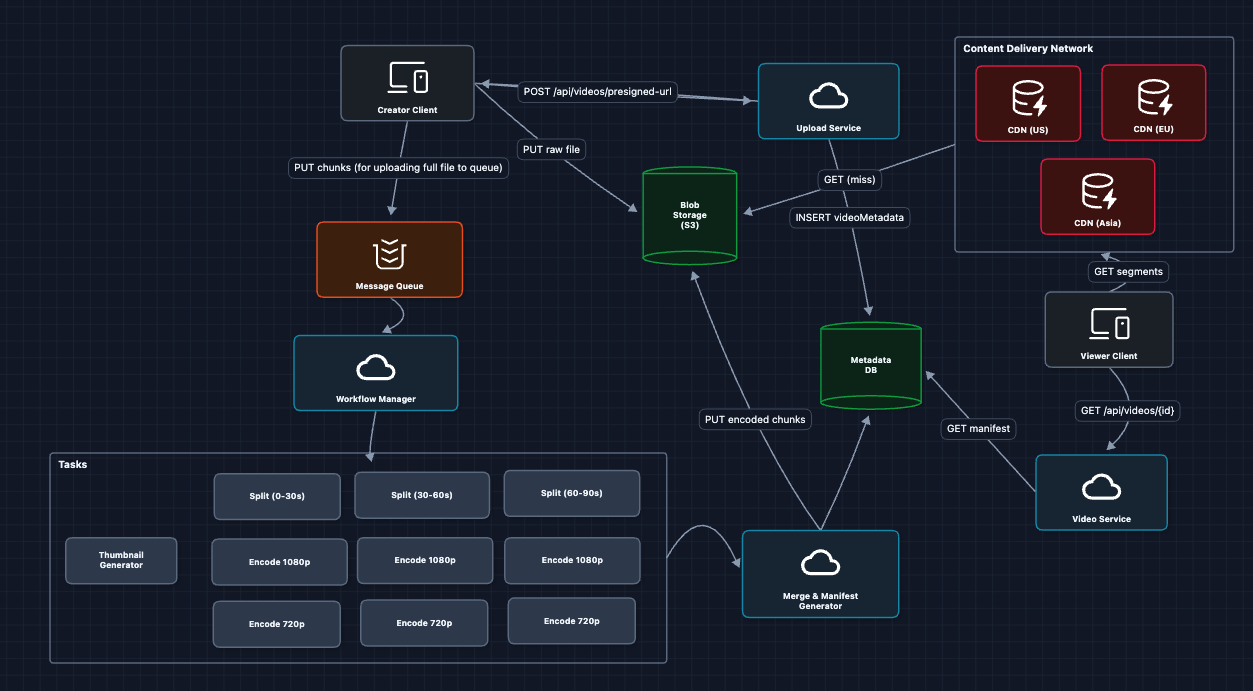
How the CDN helps:
- Viewer requests a segment
- If the nearest CDN has it, we have a cache hit.
- If not, the CDN fetches from origin, returns to viewer, caches for next request
7) Complete System: All FRs ✅
This baseline satisfies all functional requirements:
- FR1 ✅ Resumable uploads via presigned URLs + multipart
- FR2 ✅ Adaptive streaming via manifests + CDN
- FR3 ✅ Parallel transcoding via DAG workflow
Now we dive deeper into the non-functional requirements:
- NFR1: How do we make uploads truly resumable?
- NFR2: How do we speed up processing?
- NFR3: How do we scale the database for 1M+ uploads/day?
- NFR4: How do we ensure videos are always available?
Potential Deep Dives
1) How Does Resumable Upload Actually Work?: NFR1
In Diagram 3, we mentioned presigned URLs for chunks. But what happens when a connection drops mid-upload?

The fix: Track each chunk's status

Each chunk gets a hash/fingerprint. If a creator uploads the same video twice, we can detect duplicate chunks and skip them.
2) How Does the Processing DAG Work in Detail?: NFR2
In Diagram 5, we showed a DAG. Let's see how Temporal (or similar) orchestrates this:

ffmpeg is the tool workers use to actually encode video. Each worker can run a line such as: ffmpeg -i input.mp4 -vf scale=1280:720 -c:v h264 output.ts
3) Why Cassandra for Metadata?: NFR3
With 1M uploads/day and 100M views/day, we need a database that handles:
- High write throughput (uploads)
- Even higher read throughput (views)
- Point lookups by videoId (most common query)

Cassandra Trade-off: We gain massive scale, but lose the detailed querying of SQL.
Unlike a standard database, Cassandra doesn't support complex joins or arbitrary sorting. It is strictly optimized for fast, simple lookups.
To understand how Cassandra distributes data across nodes using Consistent Hashing, check out the deep dive in the Distributed KV Store article.
4) How Does Adaptive Streaming Work?: FR2
The viewer's player adapts in real-time:

This is called Adaptive Bitrate Streaming (ABR). The server just serves whatever quality the client requests.
5) What About CDN Cache Optimization?: NFR4
Popular videos (a new music video, a MrBeast video) create massive spikes in traffic. We solve this with two layers of caching.

1. Metadata Caching (Redis): We use an LRU (Least Recently Used) cache policy. Viral video metadata stays in fast RAM, prohibiting hot partitions from taking down the Cassandra cluster.
2. CDN Warming: Normally, CDNs pull content only when a user requests it. For predictable viral events, we proactively push the video files to CDN edge servers globally before the release time.
This prevents the thundering herd problem.
What to Expect?
Here's how to calibrate your response based on experience level:
Mid-level
- Focus on the complete flow (80/20): Get from upload to playback working. In the heat of the moment, you may mess up a few places, but just focus on getting a working system done before optimizing.
- Know the why behind each component: Why presigned URLs? Why CDN? Why not just one big file?
- Expect guided exploration: The interviewer will ask probing questions. "What if a user's connection drops during upload?"
- The Bar: You need to build the complete HLD with an understanding of why each part exists. At least one deep dive on either resumable uploads or adaptive streaming is expected.
Senior
- Balance breadth and depth (60/40): Complete the system efficiently, then demonstrate expertise in areas you've worked with firsthand.
- Identify bottlenecks proactively: Before the interviewer asks, mention "transcoding is the bottleneck here, let's parallelize."
- Discuss trade-offs with nuance: "We chose Cassandra for availability, but that means we accept eventual consistency. Here's why that's okay for video metadata..."
- The Bar: Full HLD plus 2-3 deep dives with real-world depth. Explain DAG orchestration, and discuss why S3 multipart works the way it does.
Staff
- Depth over breadth (40/60): Breeze through the high-level design in ~15 minutes. The interesting conversation is in the deep dives.
- Draw from experience: "At my previous company, we had this exact problem with transcoding latency. Here's what we tried and what worked..."
- Drive the conversation: The interviewer is there to observe, not steer. You identify problems and propose solutions before being asked.
- The Bar: Address ALL deep dives without prompting. Discuss codec choices, manifest format trade-offs, CDN tiering strategies, and failures. The base HLD is just the starting point for your interview.
Do a mock interview of this question with AI & crush your real interview. Good luck! 📹