
Design Distributed Key-Value Store
Problem Context
🗃️ A distributed key-value store is a database that stores data as simple key-value pairs across multiple machines. Think DynamoDB, Redis Cluster, or Cassandra.
Functional Requirements
Key-value stores have a simple interface, but the complexity lies in distribution. Work with your interviewer to scope what aspects to focus on.
Core Functional Requirements
- FR1: Users should be able to store a value by key (
PUT). - FR2: Users should be able to retrieve a value by key (
GET). - FR3: Users should be able to remove a value by key (
DELETE).
Out of Scope:
- Complex queries (SQL-like joins, aggregations).
- Transactions across multiple keys.
- Secondary indexes.
- TTL (time-to-live) for automatic expiration.
- Authentication and access control.
The simplicity of the interface (just GET, PUT, DELETE) is intentional. This lets us focus on the hard part: distributing data across machines while maintaining consistency and availability.
Non-Functional Requirements
Core Non-Functional Requirements
- NFR1: Read latency should be < 10ms (p99).
- NFR2: System should be highly available (99.99%+), tolerating node failures.
- NFR3: System should scale to billions of keys across petabytes of data.
- NFR4: System should support tunable consistency (strong vs. eventual).
Here's what we have so far:

Let's continue!
The Set Up
Planning the Approach
Based on our requirements, we need to solve two fundamental problems:
- Partitioning: How do we split data across multiple machines?
- Replication: How do we keep copies of data for availability and durability?
The key idea is that a single machine can't hold billions of keys. We need to distribute data across many nodes while making it look like one unified system to clients.
In an interview, we want to build a working system first and then we can address more of the scale requirements.
Defining the Core Entities
For this problem, we have several entities to work with:
- Key: A unique identifier (string or bytes) used to store and retrieve data.
- Value: The data associated with a key (can be any blob of bytes).
- Node: A single machine in our cluster that stores a subset of key-value pairs.
- Partition (Shard): A logical subset of the keyspace assigned to specific nodes.
- Replica: A copy of a partition stored on a different node for fault tolerance.
The terms "partition" and "shard" are often used interchangeably. A partition is a slice of the data and replicas are copies of that slice.
API Interface
Our API is intentionally minimal. The power is in how we distribute and replicate data behind this simple interface.
Data Operations: FR1, FR2, FR3
1. PUT - Store a Value
PUT /keys/{key}
Request:
{
"value": "eyJjYXJ0IjpbeyJpdGVtIjoiaVBob25lIn1dfQ==", // base64 encoded
"consistencyLevel": "quorum" // optional: "one", "quorum", "all"
}
Response:
{
"key": "user:123:cart",
"version": 1705312200, // timestamp-based version
"status": "success"
}
What's the consistency level? This controls how many replicas must acknowledge the write before we return success. "Quorum" means majority. We'll explore this in deep dives.
2. GET - Retrieve a Value
GET /keys/{key}?consistencyLevel=quorum
Response:
{
"key": "user:123:cart",
"value": "eyJjYXJ0IjpbeyJpdGVtIjoiaVBob25lIn1dfQ==",
"version": 1705312200
}
Why return version? Clients can use this for conditional updates ("only update if version matches") to prevent lost updates.
3. DELETE - Remove a Value
DELETE /keys/{key}
Response:
{
"key": "user:123:cart",
"status": "deleted"
}
How is delete implemented? We don't immediately remove data. Instead, we write a "tombstone" marker. This propagates to all replicas, then gets garbage collected later. Immediate deletion would cause deleted keys to "resurrect" if a lagging replica has the old value.
High-Level Design
Let's start off with our functional requirements:
- FR1: PUT(key, value) - store data
- FR2: GET(key) - retrieve data
- FR3: DELETE(key) - remove data
We'll start with the most basic design and incrementally improve it. In an interview, you can start at Diagram 2 or Diagram 3.
1) The Simplest System: FR1, FR2, FR3
Let's start with a single machine running an in-memory hash map.
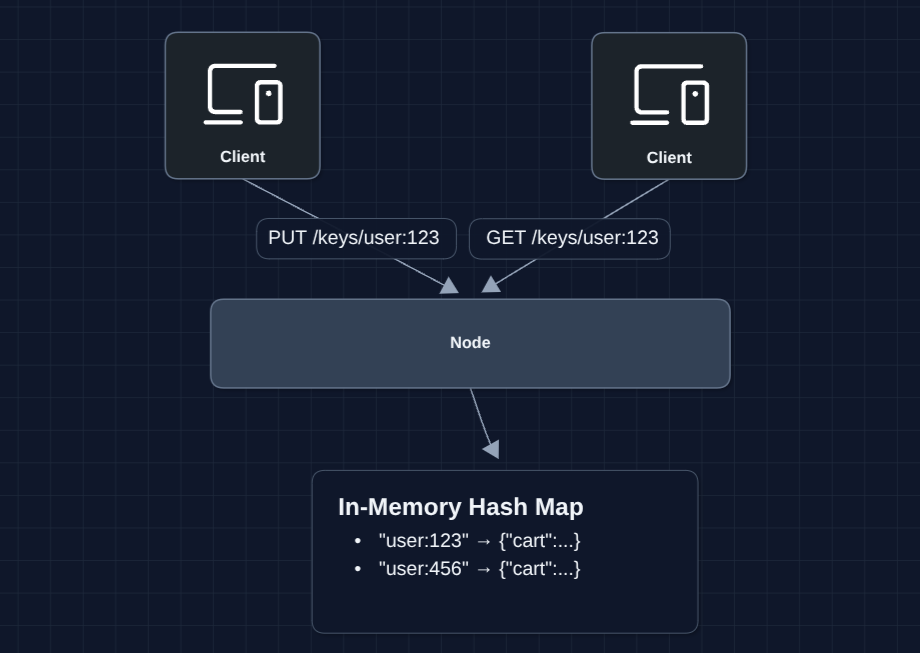
This is just a hash map. PUT inserts, GET looks up, DELETE removes. These are O(1) operations.
But what breaks?
- If the node restarts, all data is lost (in-memory only)
- If the node dies, the entire system is unavailable
- One machine has limited memory and disk (can't store billions of keys)
We need to persist data to disk.
2) Add Persistence (WAL + Storage): FR1, FR2, FR3
To survive restarts, we write data to disk. But disk writes are slow, so we use a Write-Ahead Log (WAL).
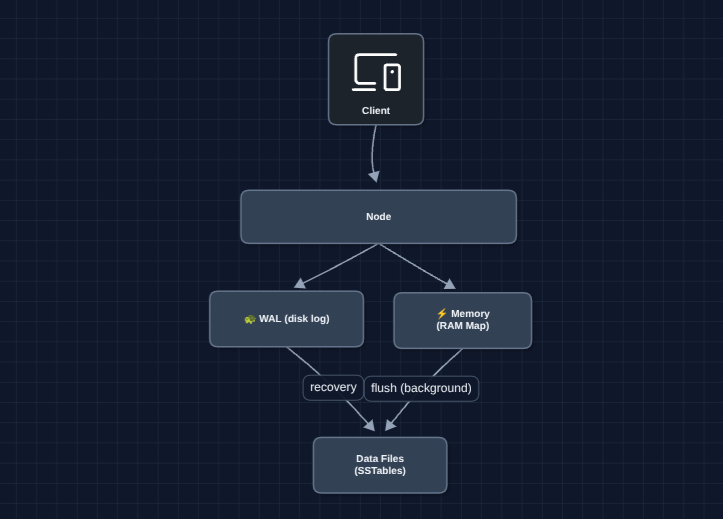
How the WAL helps: Random disk writes are slow because the disk jumps around. The WAL is append-only which is ~100x faster. Writes go to both the WAL (durability) and memory (fast reads). When memory fills up, it's flushed to a sorted file (SSTable) on disk. Sorted files enable binary search, keeping disk reads fast too.
But what breaks?
- One machine still has limited capacity (can't scale to petabytes)
- If this node dies, the system is unavailable
- All requests go to one node (bottleneck)
We need multiple nodes.
3) Partition Data Across Nodes: NFR3 (Scalability)
We're still on FR1, FR2, FR3, but now tackling NFR3 (scale). Let's split the keyspace across multiple nodes.
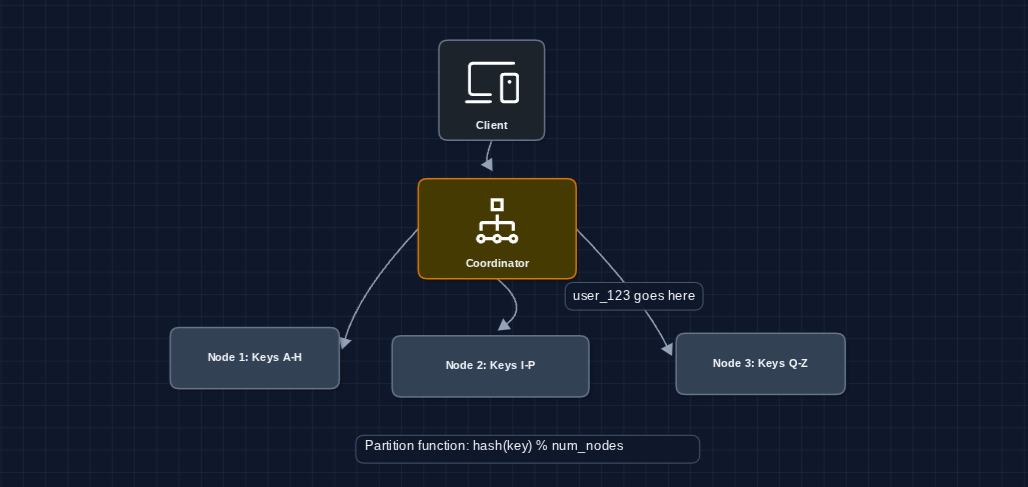
How do we decide which node gets which key? We hash the key and use modulo to pick a node. For example: hash("user:123") % 3 = 1, so it goes to Node 2.
But what breaks?
- Adding a new node changes
hash(key) % Nfor almost every key (massive data migration) - If a node dies, its entire partition is unavailable
- The coordinator is a single point of failure
We need a smarter partitioning scheme.
4) Consistent Hashing: NFR3 (Scalability)
If we use hash(key) % numberOfNodes to decide which database stores a key:
hash("user:123") % 3 = 1: Node 1hash("user:123") % 4 = 3: Node 3 (we added one node)
When we add or remove a node, almost every key's data moves to a different database. This is expensive and disruptive.
The Fix: Consistent Hashing
Instead of dividing by the number of nodes, we imagine a ring of hash values.
- Hash each database to a position on the ring
- Hash each key (ex. user:123) to a position on the ring
- Walk clockwise from the key's position until you hit a database for the data
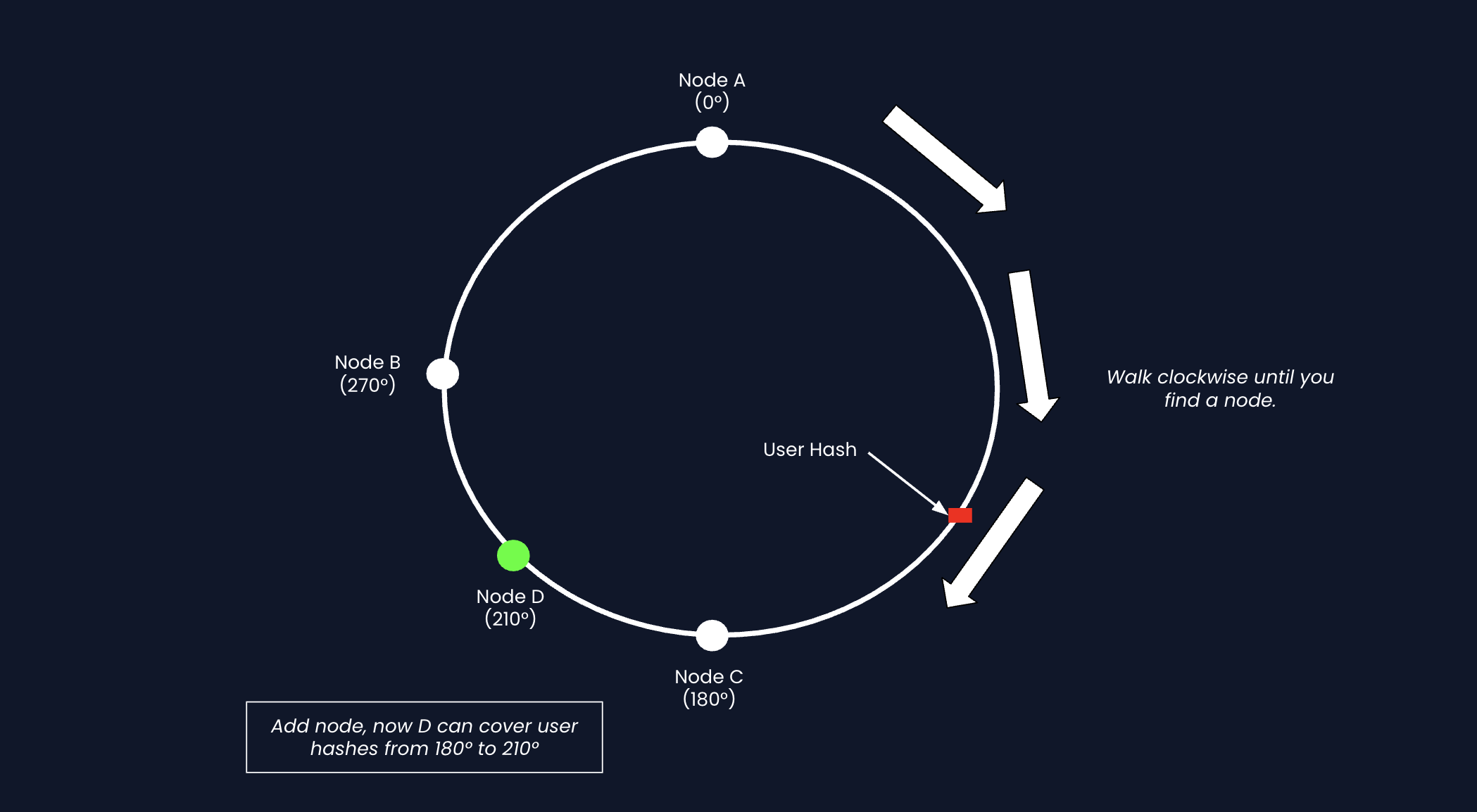
When you add a new database, it only takes over a small arc of the ring. Keys outside that arc are unaffected.
- Simple hashing: Add 1 node and 75% of data moves
- Consistent hashing: Add 1 node and 25% of data moves (only what's in the new node's arc)
How does data migration work? When Node D joins, Node C streams any keys in Node D's new range over to it.
The ring doesn't physically exist. It's just a mathematical representation that is written in code.
But what breaks?
- If Node B dies, all keys in its range are unavailable
- Hot keys might all land on one node (uneven distribution)
- Still no redundancy
We need replication.
5) Add Replication: NFR2 (Availability)
To survive node failures, we store each key on N nodes (replicas). Each key goes to its primary node on the ring AND the next N-1 nodes clockwise.
For example, with 10 total nodes and N=3, each key lives on 3 out of 10 nodes. You can add more nodes to scale.
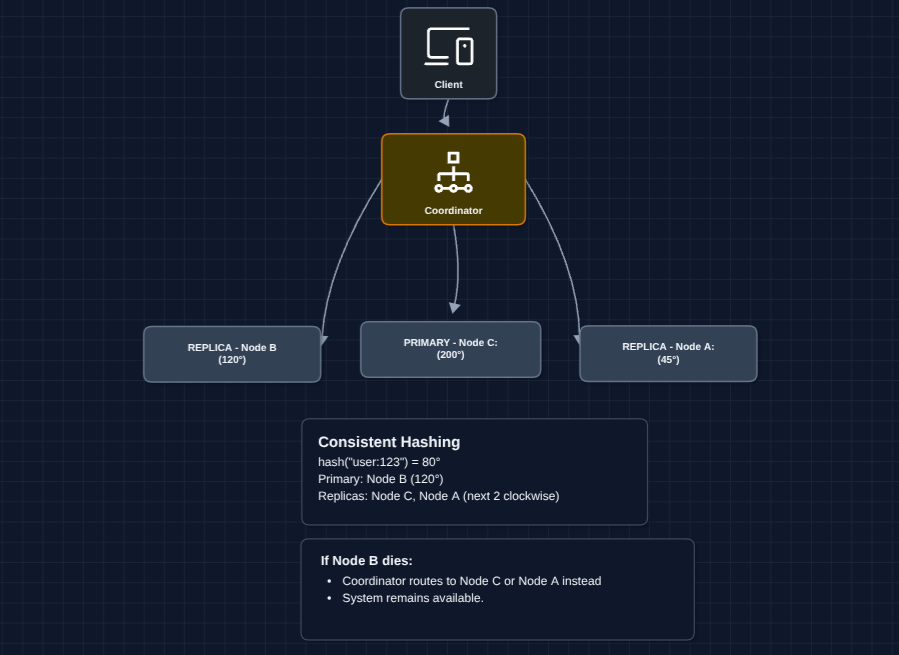
How does write work? The coordinator sends the write to all N replicas. We'll discuss how many must respond before returning to the client (quorum) in deep dives.
But what breaks?
- What if replicas have different values? (consistency vs. availability trade-off)
- How many replicas must acknowledge a write before we return success?
6) Complete System: FR1, FR2, FR3 ✅
Now let's put it all together.
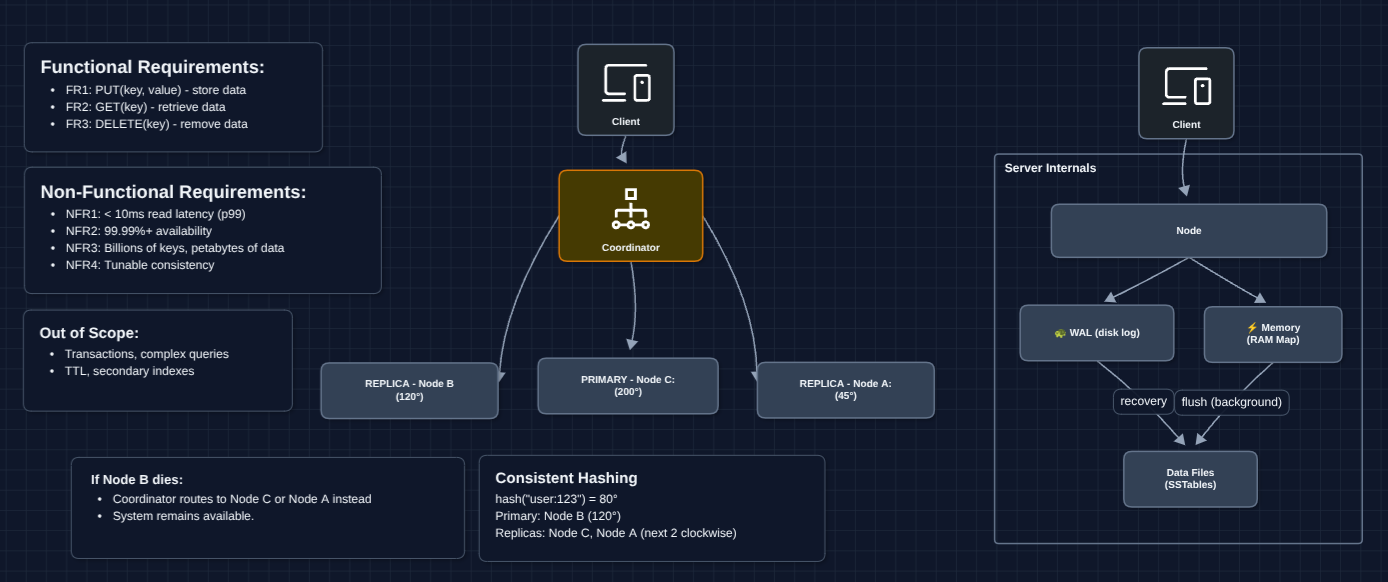
This is our baseline architecture. We now have:
- FR1 ✅ PUT works via coordinator
- FR2 ✅ GET works via coordinator
- FR3 ✅ DELETE works via tombstones
- NFR2 ✅ Node failures don't cause unavailability (replicas take over)
- NFR3 ✅ Add nodes to scale horizontally
Now we address remaining concerns in deep dives:
- NFR1 (Latency): How fast are reads and writes?
- NFR4 (Consistency): How do we handle conflicts between replicas?
- Failure detection: How do nodes know when a peer is down?
Potential Deep Dives
1) How does consistent hashing distribute keys evenly?: NFR3 (Scalability)
In Diagram 4, we showed a hash ring. But if nodes are placed randomly, one node might own a huge range while another owns a tiny range.
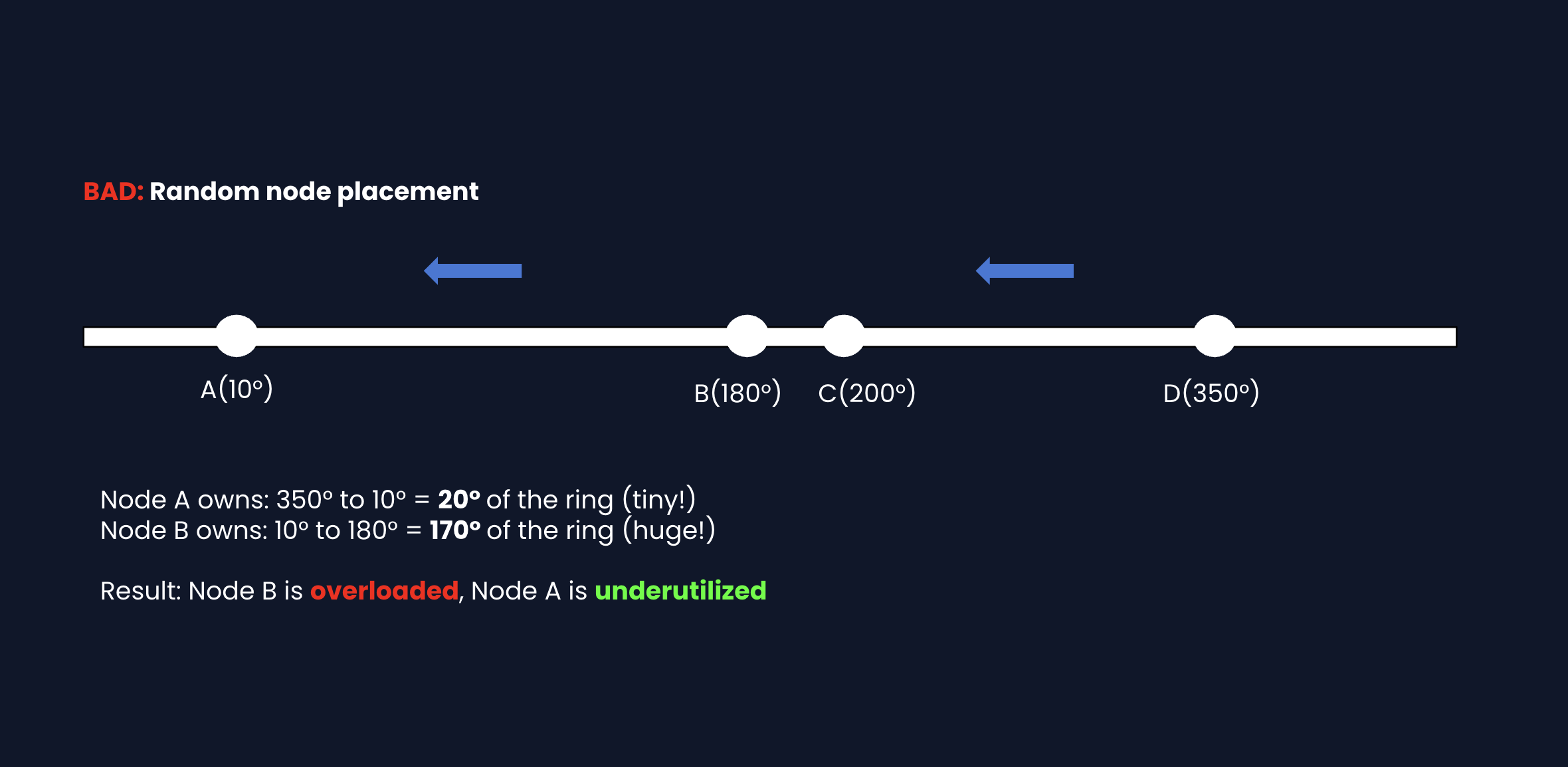
Fix: Virtual nodes. Each physical node gets multiple positions on the ring.
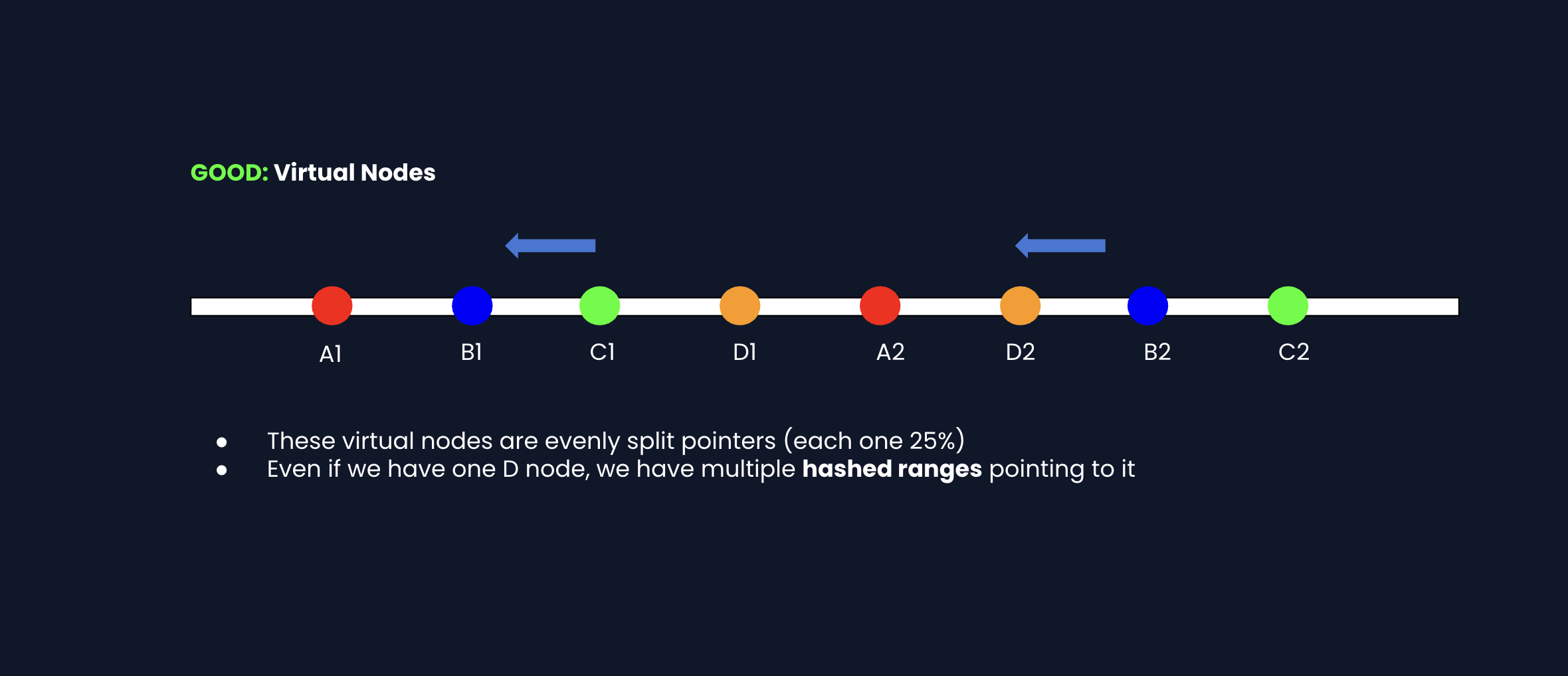
When a node is added/removed: Only the virtual nodes for that physical machine change. Other nodes' ranges stay mostly the same.
DynamoDB and Cassandra both use this approach. More virtual nodes is better balance, but more metadata to track.
2) How do replication and quorum provide tunable consistency?: NFR4 (Consistency)
In Diagram 5, we replicate data to N nodes, since we are designing a distributed key-value store. But how many must acknowledge before we respond to the client?

Why W + R > N works: If W replicas have the write, and we read from R replicas, at least one replica will be in both sets. We pick the value with the highest version.
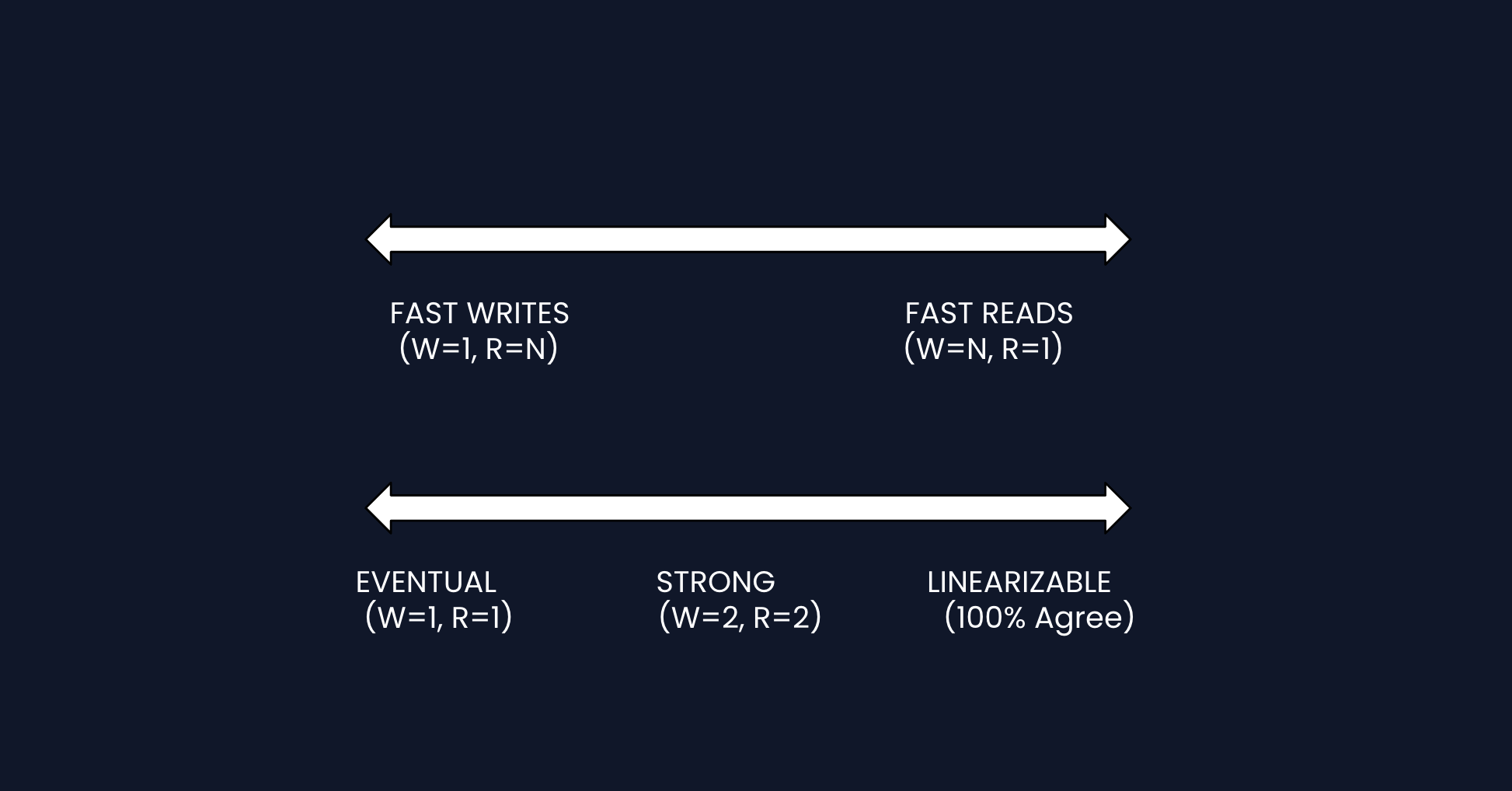
Most systems require majority confirmation for both reads and writes.
DynamoDB lets you choose consistency per-request. For example, shopping cart reads can use eventual consistency for speed, while financial data would use strong or linearizable consistency for correctness.
3) What happens when replicas have different values?: NFR4 (Consistency)
With eventual consistency, replicas can temporarily disagree. How do we resolve conflicts?

Strategy 1: Last-Write-Wins (LWW)

Strategy 2: Vector Clocks

Vector clocks detect conflicts but don't solve them. The application must decide how to merge (e.g., union of shopping cart items). For simple values, LWW is often good enough.
4) How do nodes detect failures?: NFR2 (Availability)
In Diagram 5, we said "if Node B dies, route to replicas." But how do nodes know when a peer is down?

Fix: Gossip Protocol
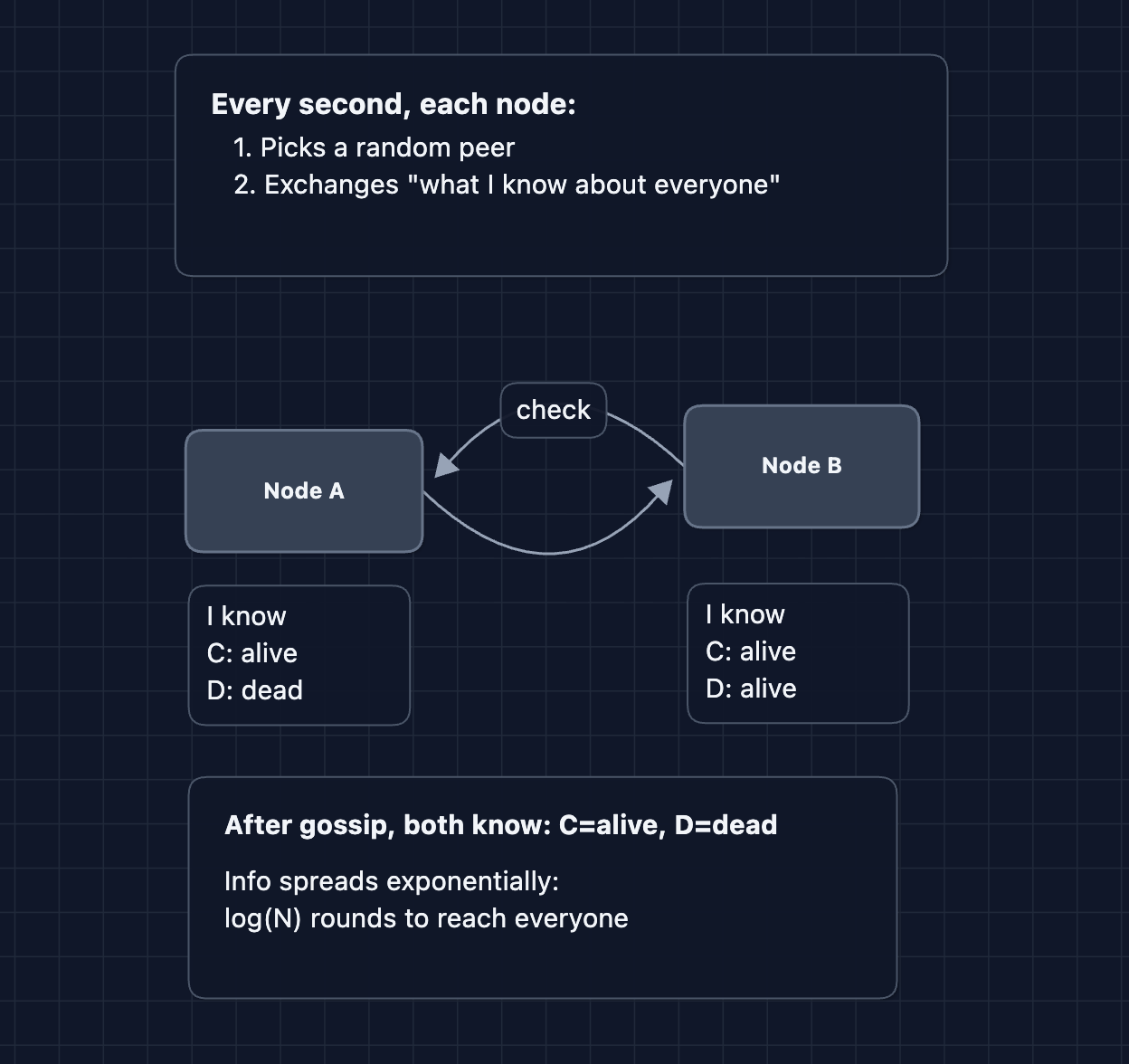
Failure detection logic:
- Each node maintains a "heartbeat counter" for every peer
- Gossip shares heartbeat counters
- If a node's counter doesn't increase for X seconds, mark it as "suspected"
- After Y more seconds, mark it as "dead"
This is how Cassandra and DynamoDB detect failures. It's eventually consistent (there's a delay), but it scales to thousands of nodes.
5) How do reads achieve < 10ms latency?: NFR1 (Latency)
First, let's understand the three components that store data on each node:
- MemTable: An in-memory sorted structure holding recent writes. Fast because it's in RAM.
- SSTable (Sorted String Table): Immutable files on disk with keys sorted alphabetically. Enables binary search.
- Bloom Filter: A small structure per SSTable that answers "Is this key possibly here?" It can say definitely not (skip the file) or maybe (search the file).

Why is this fast? MemTable serves hot keys instantly. Bloom filters skip irrelevant disk files. Sorted SSTables allow O(log N) binary search instead of O(N) scanning.
This pattern is called an LSM Tree (Log-Structured Merge Tree). Used by Cassandra, LevelDB, and RocksDB.
What to Expect?
That was a complete distributed key-value store! Here's what you need to cover at each level.
Mid-level
- Breadth over Depth (80/20): Cover partitioning (why we need to split data), replication (why we need copies), and the basic ring structure.
- Expect Basic Probing: Be ready for "Why not just use a single database?" or "What happens if a server dies?"
- Assisted Driving: You propose the initial single-node architecture, but the interviewer will guide you toward distribution and replication.
- The KV Store Bar: You must successfully explain why we partition (scale), why we replicate (availability), and show a working request flow through the system.
Senior
- Balanced Breadth & Depth (60/40): You should proactively mention consistent hashing (not just "we hash the key"), explain quorum math (W + R > N), and discuss trade-offs between consistency and availability.
- Proactive Problem-Solving: You identify the rebalancing problem before the interviewer asks: "If we use hash % N, adding a node reshuffles everything. Let me use consistent hashing instead."
- Articulate Trade-offs: You can explain "Strong consistency requires majority quorum, which is slower. Eventual consistency is faster but can return stale data. Shopping carts might be fine with eventual; bank balances need strong."
- The KV Store Bar: Complete system with virtual nodes and replication with quorum consensus. Dive into 2-3 deep dives: consistent hashing, quorum trade-offs, or conflict resolution. Discuss trade-offs clearly.
Staff
- Depth over Breadth (40/60): Speed through the HLD in ~15 minutes. Interviewers assume you know replication and partitioning. Spend more time on the nuances of the design.
- Experience-Backed Decisions: You draw from real systems: "DynamoDB uses virtual nodes for balance. Cassandra's gossip protocol handles failure detection. Here's why..."
- Full Proactivity: You anticipate every deep dive before being asked. You discuss clock synchronization challenges, tombstone garbage collection, hinted handoff for temporary failures.
- The KV Store Bar: Address ALL deep dives without prompting: virtual nodes, quorum math, vector clocks vs LWW, gossip protocol, and read/write paths. You explain how production systems like DynamoDB or Cassandra actually work.
Go try a mock interview on this question with AI and good luck! 🗃️