
Design Facebook News Feed
Problem Context
📱 Facebook’s News Feed is a constantly updating stream of posts from people and Pages you follow, personalized for over 3 billion monthly users.
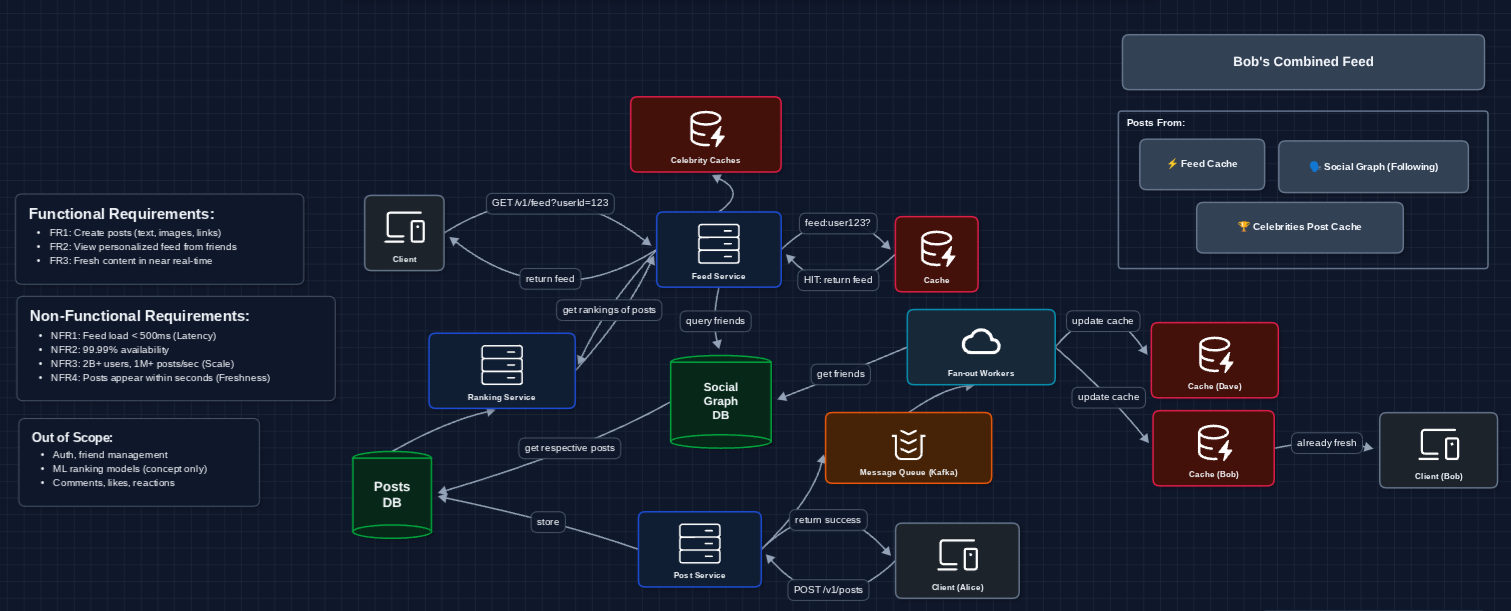
Functional Requirements
The News Feed is a complex problem that can be taken in many directions. We need to establish what parts we're designing with our interviewer.
Core Functional Requirements
- FR1: Users should be able to create posts (text, images, links).
- FR2: Users should be able to view a personalized feed of posts from friends.
- FR3: Feed should show fresh content in near real-time.
Out of Scope:
- User authentication and friend management.
- Detailed ranking ML models (we'll discuss the concept, not implementation).
- Comments, likes, and reactions.
- Stories, Reels, and other content types.
- Ads integration.
Non-Functional Requirements
Core Non-Functional Requirements
- NFR1: Feed load time should be < 500ms.
- NFR2: System should be highly available (99.99%+).
- NFR3: System should scale to 2B+ daily active users and 1M+ posts/second.
- NFR4: New posts should appear in friends' feeds within seconds.
Here's what we have so far:

Let's continue with our design.
The Set Up
The Main Challenge
When Alice opens Facebook, she expects a personalized feed in milliseconds (posts from her 500 friends, ranked by relevance).
Behind the scenes, we need to gather candidates from all her connections, score them, and return the top 20. Multiply that by 2 billion daily users, and we understand the scale of the problem.
Let's start with what we're storing and build up the solution from there.
Core Entities
User
{
userId: "user_123",
name: "Alice Smith",
followerCount: 847, // important for fan-out decisions
isActive: true // used for cache warming decisions
}
Post (our primary write entity)
{
postId: "post_abc789",
authorId: "user_123",
content: "Just got promoted! 🎉",
mediaIds: ["img_456", "img_789"], // references to CDN
visibility: "friends", // friends | public | private
createdAt: "2025-01-05T10:30:00Z"
}
Social Graph (stored in NoSQL, not a graph DB. For our current problem, this will work)
{
userId: "user_123",
friends: ["user_456", "user_789", ...], // bidirectional for Facebook
following: ["page_nike", "celeb_oprah"] // unidirectional follows
}
Feed Cache Entry (candidate list per user)
{
feedOwnerId: "user_456", // whose feed is this
postIds: ["post_abc", "post_def", "post_ghi", ...] // candidate postIds
}
APIs
1. Post Creation APIs (FR1)
Create Post
- Endpoint:
POST /v1/posts
Request Body:
{
"userId": "user_123",
"content": "Just had the best coffee! ☕️",
"mediaIds": ["img_456"],
"visibility": "friends"
}
Response:
{
"postId": "post_abc789",
"status": "published"
}
Note: This triggers the fan-out process to populate friends' feeds.
2. Feed Retrieval APIs (FR2, FR3)
Get Feed
- Endpoint:
GET /v1/feed?userId={userId}&limit=20&cursor={cursor}
Response:
{
"posts": [
{
"postId": "post_xyz",
"authorId": "user_456",
"content": "Check out this sunset!",
"score": 0.95
}
],
"nextCursor": "cursor_next_page"
}
What happens: The Feed Service fetches candidates from the cache, ranks them by relevance, and returns a paginated list.
Get Feed Updates
- Endpoint:
GET /v1/feed/updates?userId={userId}&since={timestamp}
Response:
{
"newPostCount": 3,
"hasUpdates": true
}
Why: Checks for new posts since the last visit to show a notification without reloading the full feed.
High-Level Design
We'll build this up piece by piece. First, we'll handle the read path (how users see their feed), then we'll tackle the write path (how posts fan out to friends).
It's helpful to tell the interviewer that the HLD you're building is not the optimized design. You are just trying to get something working before going into more detail and optimization in the deep dive.
1) The Simplest System: FR2 (View Feed)
Let's start with the most simple approach: query everyone's posts on every feed request.
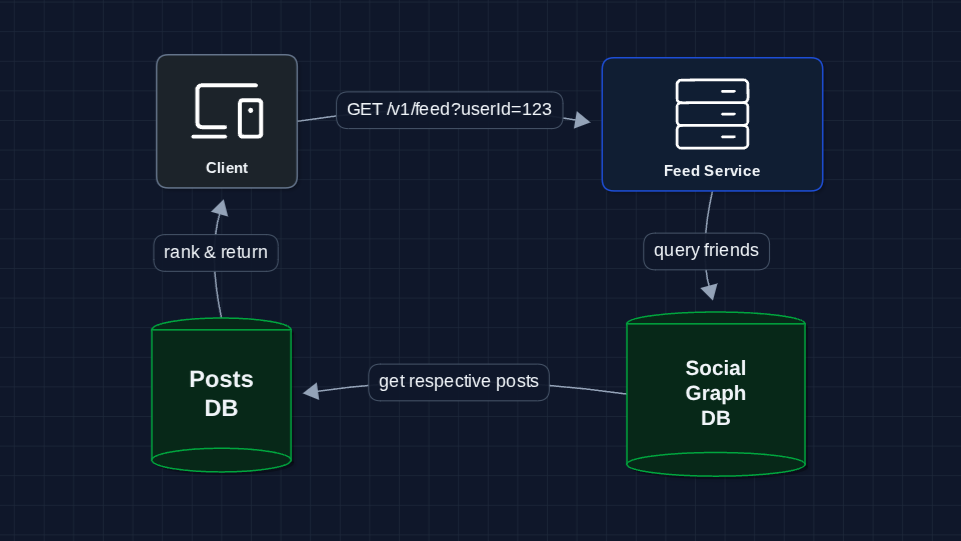
The user requests their feed, we query friends, query their posts, sort, return. Simple!
Why doesn't this work at scale?
- Latency: User has 500 friends * 100 posts each = query 50,000 rows per request
- Database load: 2B users * multiple refreshes/day = billions of expensive queries
- No personalization: Just sorting by time, not relevance
We need to pre-compute feeds, not compute on every request.
2) Add a Cache: FR2 (View Feed)
Instead of computing the feed on every request, let's cache results:
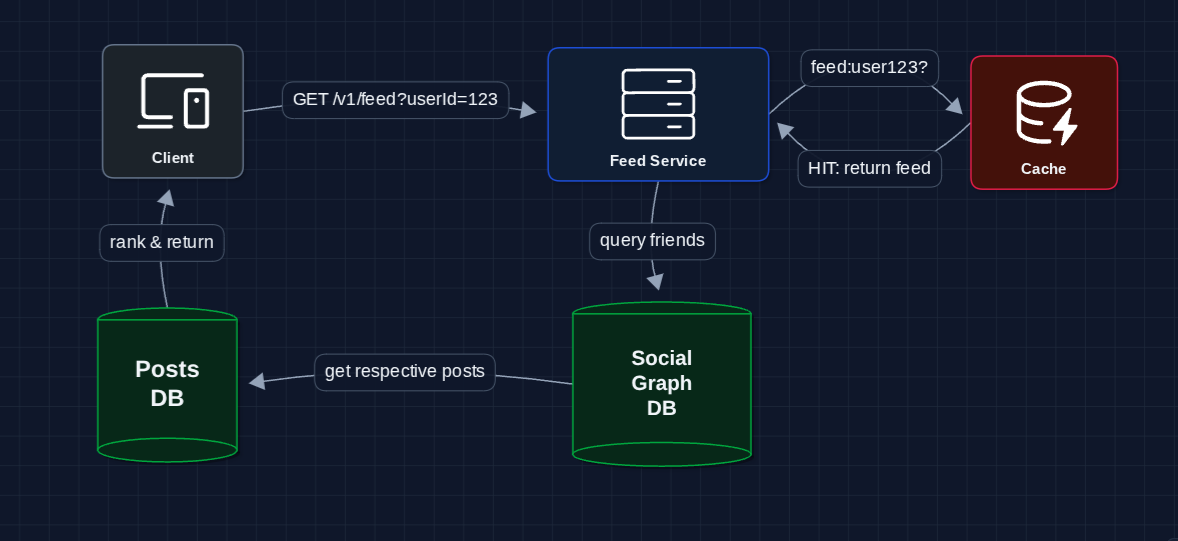
This is better. Repeat requests are fast.
The problem? Stale data.
- Cache invalidation: When a friend posts, when does the cached feed update?
- Cold cache: First request after cache expires is still slow
- Staleness: Cached feed doesn't show new posts (violates FR3!)
We need a way to keep feeds fresh.
3) Fan-out on Write: FR3 (Freshness)
Here's an idea: instead of computing feeds on read, push posts to feeds on write.
When Alice posts, we immediately update all her friends' cached feeds:
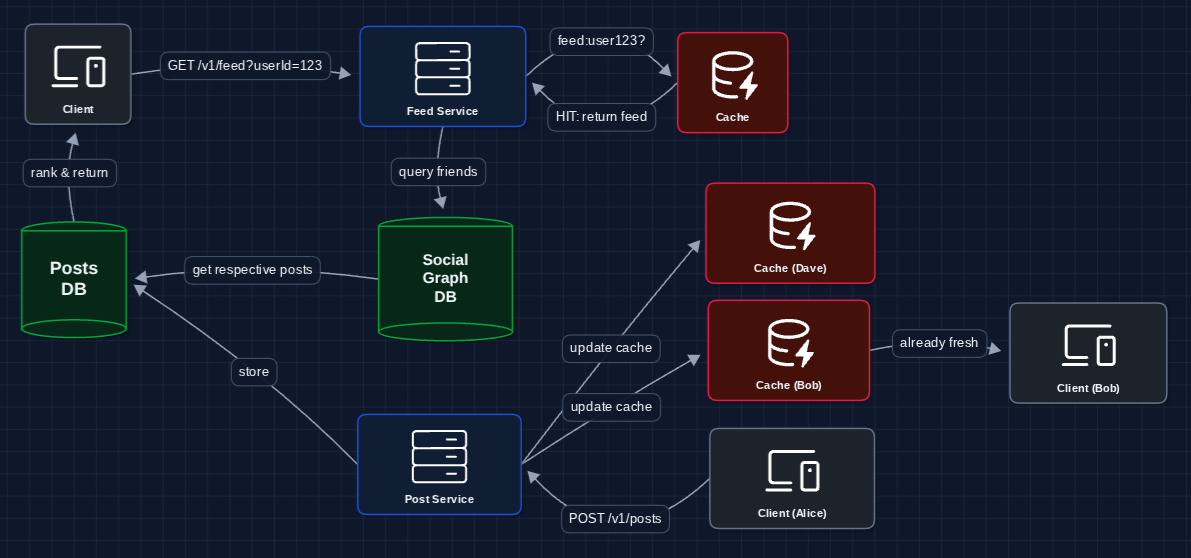
Now when Bob opens his app, Alice's post is already in his feed cache.
One massive problem remains.
- Celebrity problem: What if a celebrity with 100M followers posts?
- We need to update 100M feed caches instantly
- This could take hours and overwhelm the system
We need a hybrid approach for high-follower accounts.
4) Hybrid Fan-out: Handling Celebrities
Lady Gaga has 100M followers. We can't update 100M feed caches every time she posts.
Solution: Fan-out on write for normal users, fan-out on read for high-follower accounts.

How Bob's feed is assembled:
- Feed Cache: Pre-computed posts from normal friends (pushed via fan-out on write).
- Social Graph: Tells us which celebrities Bob follows.
- Celebrities Post Cache: Fetched at read time for posts from high-follower accounts.
The Feed Service merges all three, ranks, and returns the combined feed.
In reality, the threshold should be configurable, not hardcoded. A hard if (followers > 10000) is brittle becase a user with 500 followers can have a viral post.
5) Async Fan-out with Message Queue: FR1 + FR3
Let's make fan-out asynchronous so post creation happens immediately:
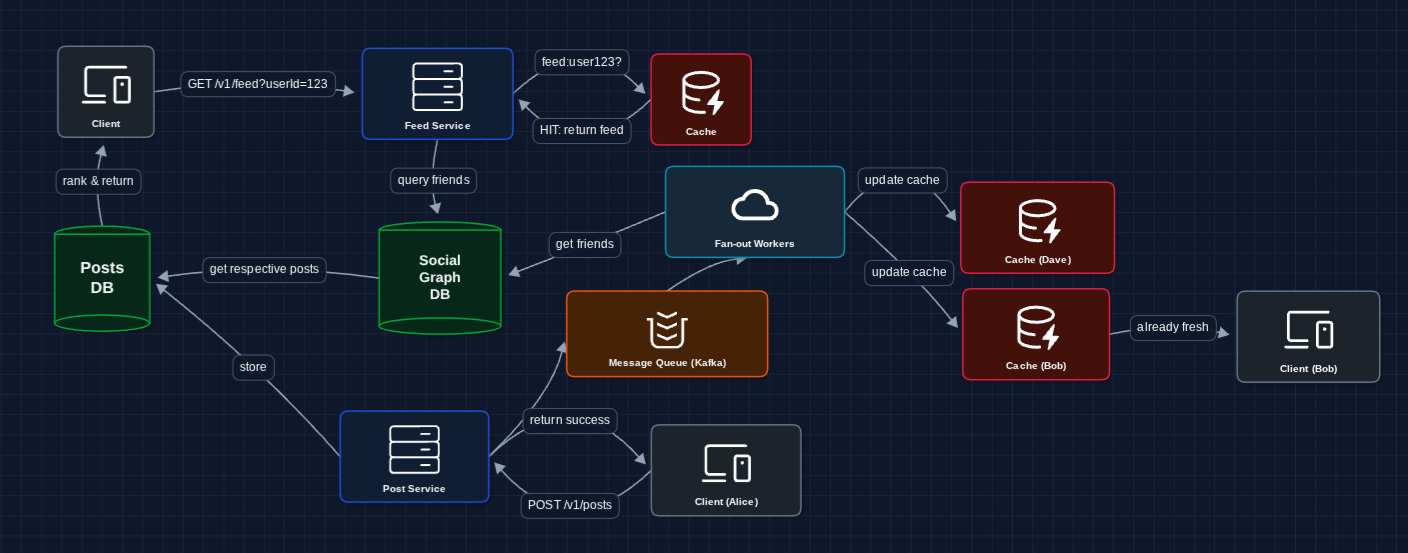
What we added:
- Message Queue (Kafka) for async processing
- Fan-out Workers to handle the heavy lifting
- Alice doesn't wait for fan-out to complete
6) Add Ranking Service: FR2 (Personalization)
Right now we're just sorting by time. Let's add relevance ranking:
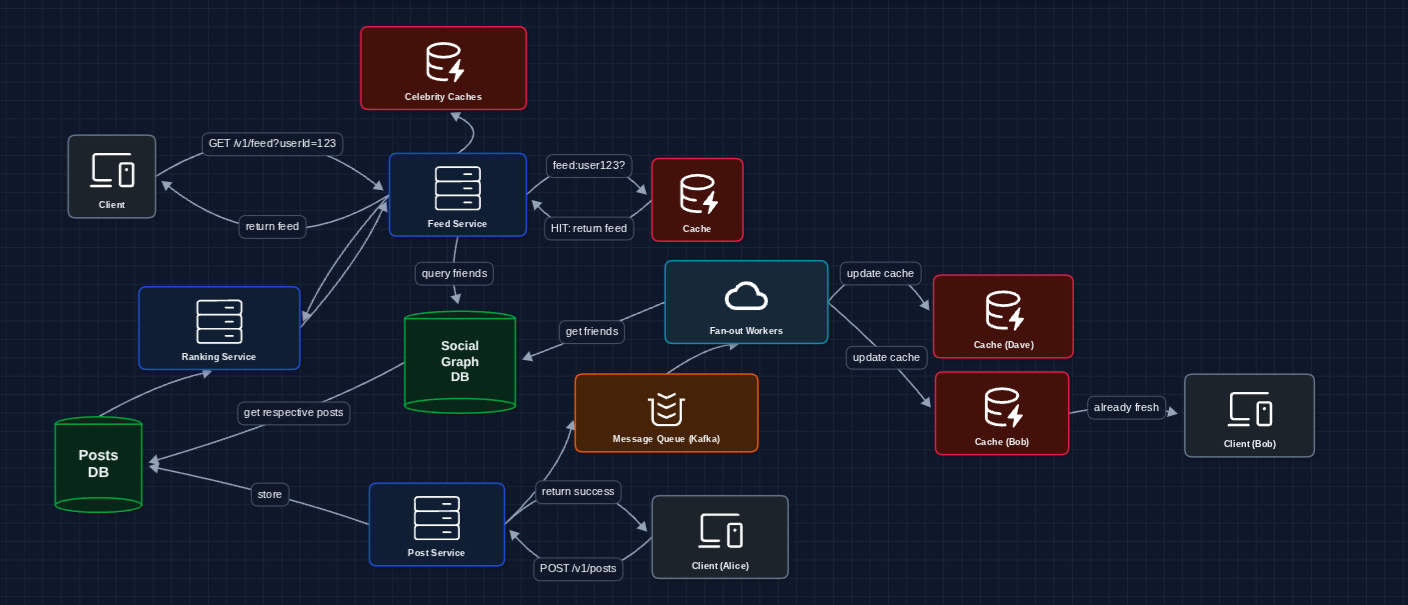
We won't go into depth on how rankings actually work, as recommendations are out of scope. However, we can acknowledge how it fits in.
Complete System: Diagram 7
Now we have a complete working system that satisfies all functional requirements. Let's put it together:
This is our baseline architecture!
Why these technology choices?
-
DynamoDB for Posts DB: At 1M+ writes/second, SQL becomes a bottleneck. Posts are key-value lookups (
GET post by postId). We don't need complex joins. If the cache fails, we query DynamoDB directly. Partition key:postId. Sort key:createdAtfor range queries. -
DynamoDB for Social Graph: DynamoDB with
PK: userId, SK: friendIdworks for 1-hop queries (Who does Bob follow?). However, it fails at multi-hop queries like friends of friends or mutual friends. For that, Facebook built TAO.
Now we can address our non-functional requirements in the deep dives:
- NFR1 (Latency < 500ms): How do we ensure fast feed loads?
- NFR3 (Scale): How do we handle billions of users?
- NFR4 (Freshness): Real-time updates and notifications
- NFR2 (Availability): What happens when things fail?
Potential Deep Dives
Fan-out trade-offs (covered in HLD Diagram 4) is THE core concept for News Feed. You must articulate push vs pull and the hybrid solution. If you can't explain why celebrities break fan-out on write, you're not ready.
1) How do we ensure sub-500ms feed loads?: NFR1 (Latency)
Two techniques: tiered caching and read-time ranking.
Hot Data Caching: RAM is expensive. Only cache what users actually view.
- Cache (Redis): Top 50 postIds for active users (~<5ms latency)
- Database (DynamoDB/Cassandra): All feed data, queried on cache miss (~<50ms latency)
90% of users never scroll past post #20. Inactive users have no cache, falling back to database queries.
Read-time Ranking: Don't pre-compute scores during fan-out (they go stale).
- Write path: Store
[postId, postId, ...]only (no scores) - Read path: Score ~500 candidates in <50ms in real time, based on what the user has recently engaged with.
2) Real-time Feed Updates: NFR4 (Freshness)
There are three ways to push updates to clients. Facebook uses all three depending on context:
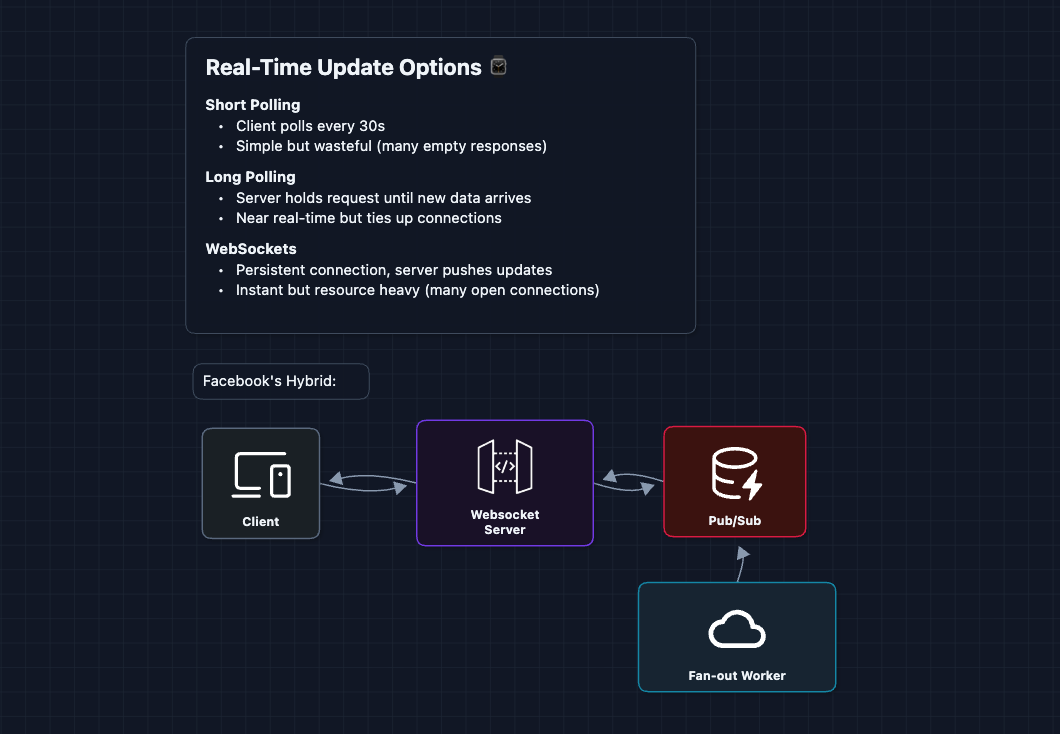
How it works:
- Fan-out worker updates Bob's feed cache, then publishes the new content event to Pub/Sub
- WebSocket server is subscribed to Bob's channel
- WebSocket pushes notification to Bob's open app
What's Pub/Sub? A messaging pattern where publishers send to channels, subscribers listen to channels. Redis Pub/Sub is lightweight and fast. When Bob opens the app, the WebSocket server subscribes to user:bob. When a worker publishes to that channel, the message instantly reaches Bob.
Fallback strategy:
- Active tab/app: WebSocket for instant in-app counter
- Background/offline: Fall back to short polling on next open
- Mobile: Push notifications (iOS/Android) for close friends only
3) Scaling to Billions: NFR3 (Scale)
One machine can't handle all of Facebook's feed data. We need to shard.
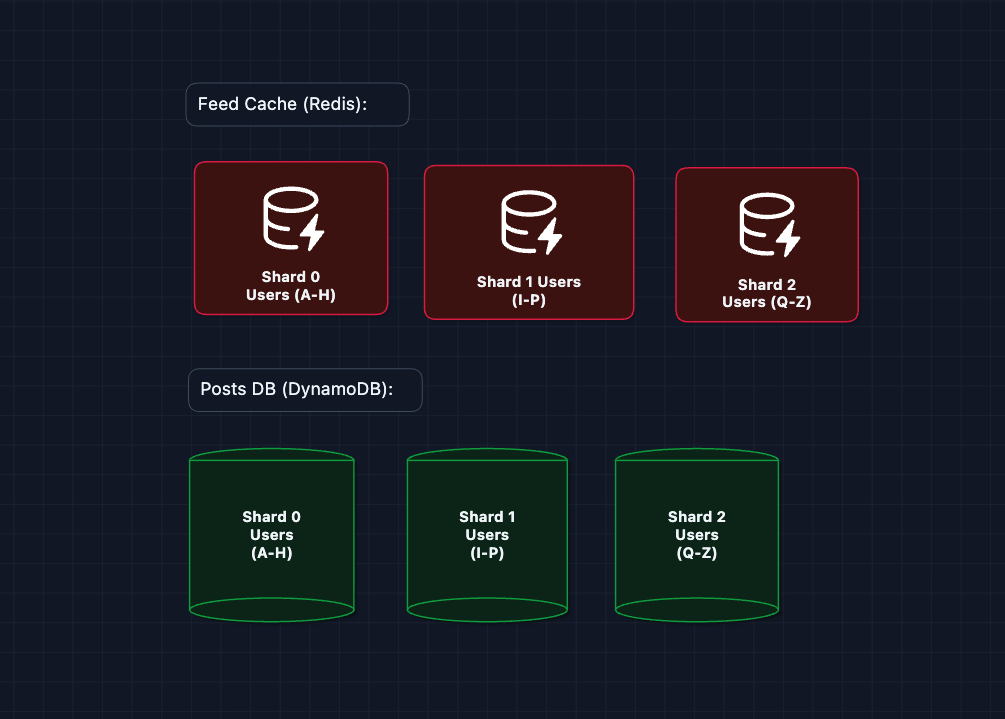
What is sharding? Splitting your data across multiple machines. Each machine holds a portion of users. This way, no single machine gets overwhelmed.
Why shard by userId?
- Predictable routing: Given a userId, you instantly know which shard to query
- Even distribution: Random user IDs spread evenly across shards
- Independent scaling: Add more shards as you grow
In real systems, Consistent Hashing is used to distribute data across shards. Check out the deep dive in the Distributed KV Store article.
The Hot Key Problem
What happens when a celebrity post goes viral? Millions of users request the same postId simultaneously (all routed to the same cache shard)
Solution: Redundant Post Caching
- Detect hot posts (>10K requests/second)
- Replicate that post's data across multiple cache servers
- Route requests randomly across replicas:
hash(postId + randomSuffix)
This is a thundering herd problem. Try to identify this clearly in your interview.
4) Handling Failures: NFR2 (Availability)

How the fallbacks work:
- Redis down: Feed Service detects the cache miss/timeout and falls back to querying the Posts DB directly. It fetches recent posts from friends and returns them sorted by time (no ML ranking).
- Kafka down: The Post Service still writes the post to the Posts DB (so it's not lost). A background job periodically retries pushing to Kafka. Once Kafka recovers, fan-out resumes.
- Ranking down: Feed Service catches the timeout and applies a simple formula like
score = 1 / (hours_since_post + 1)to sort by recency instead.
Graceful degradation over failure: Every component should have a fallback. A slower or less personalized feed is always better than an error page.
What to Expect?
News Feed is one of the most common system design questions because it touches on so many core concepts: caching, message queues, data modeling, and trade-offs between read and write performance. Here's what to focus on at each level.
Mid-level
- Breadth over Depth (80/20). Get through the full HLD. Show you understand why fan-out exists and how the parts interact.
- Expect Basic Probing. "Why can't we just query on every read?" You should explain that aggregating posts from hundreds of friends on every request doesn't scale. Be able to answer "Why Kafka instead of writing directly to Redis?"
- Assisted Driving. You lead the design, but the interviewer may guide you toward the fan-out problem and caching layer.
- The News Feed Bar. Explain push vs. pull fan-out, draw a working system, and articulate why caching is used. Understand what each component does and why.
Senior
- Balanced Breadth & Depth (60/40). Complete the full system and proactively raise the celebrity problem. Bring it up yourself and propose the hybrid solution.
- Proactive Problem-Solving. Justify your design choices with reasoning: "We set a follower threshold for hybrid fan-out because most users have few followers, so push works for them. Only celebrities need pull."
- Articulate Trade-offs. Pick 2-3 areas to go deep: hybrid fan-out trade-offs, cache warming strategies, real-time delivery with WebSockets.
- The News Feed Bar. Full system design plus deep dives into fan-out strategies and cache warming.
Staff
- Depth over Breadth (40/60). The interviewer already knows you can design a feed. Breeze through the HLD (~10-15 mins). Spend the rest on interesting problems.
- Experience-Backed Decisions. Discuss cross-region consistency: if Alice in NYC posts, when does Bob in Tokyo see it? What's acceptable? Bring operational experience: cache eviction policies, Kafka partition strategies, handling backpressure during viral events.
- Full Proactivity. Talk about what could go wrong. The interviewer wants to see your experience.
- The News Feed Bar. Address all deep dives unprompted. Discuss operational concerns like monitoring queues, alerting on fan-out lag, and handling hot keys.
Do a mock interview of this question with AI & pass your real interview. Good luck! 📱