
Design URL Shortener (TinyURL / Bit.ly)
Problem Context
🔗 URL shorteners transform long URLs into compact, shareable links. Short URLs are everywhere, from marketing campaigns to SMS messages, QR codes, and social media posts.
At first glance, we just have a key-value lookup. But at scale, generating unique short codes without collisions and serving fast redirects to millions of concurrent users is when things start to get interesting.
Functional Requirements
Core Functional Requirements
- FR1: Users should be able to create a short URL from a long URL.
- FR2: Users visiting a short URL should be redirected to the original long URL.
- FR3: The system should track basic analytics (click count per URL).
Out of Scope:
- User accounts and authentication.
- Custom domains (e.g., yourbrand.co/abc).
- Link expiration policies.
- Spam and abuse detection.
- QR code generation.
URL shorteners appear simple but touch many interesting distributed systems concepts: ID generation, caching, database sharding, and analytics pipelines. Keeping scope tight lets you go deep on these.
Non-Functional Requirements
Core Non-Functional Requirements
- NFR1: Redirect latency should be < 50ms (P99).
- NFR2: System should be highly available (99.99%+).
- NFR3: System should scale to 100M URLs and 10K redirects/second.
- NFR4: Short URLs should be as compact as possible (≤ 7 characters).
Here's what we have so far:

Let's get to work.
The Set Up
Planning the Approach
This system has a heavily skewed read/write ratio. For every URL created, it gets clicked hundreds or thousands of times. Our design needs to optimize for:
- Writes (URL creation): Generate a unique short code and store the mapping.
- Reads (Redirects): Look up the long URL and redirect as fast as possible.
In the interview, recognize this read-heavy pattern early. It directly informs decisions about caching and database choice later on.
Defining the Core Entities
For this problem, we have a few simple entities:
- Short Code: The unique identifier in the URL (e.g.,
abc123inshort.url/abc123). - URL Mapping: The record linking a short code to its original long URL.
- Click Event: A record of someone visiting a short URL (for analytics).
API Interface
Our API is minimal: create URLs and redirect users. We can define analytics after we have a working system.
URL Creation API: FR1
Create Short URL
POST /urls
Request:
{
"longUrl": "https://example.com/very/long/path?with=params&and=more"
}
Response:
{
"shortCode": "abc123",
"shortUrl": "https://short.url/abc123",
"longUrl": "https://example.com/very/long/path?with=params&and=more",
"createdAt": "2024-01-15T10:30:00Z"
}
Decision:
- Should the same long URL always return the same short code? (We'll discuss this trade-off later)
Redirect API: FR2
Redirect to Original URL
GET /{shortCode}
Example:
GET /abc123
Response:
HTTP 301 Moved Permanently
Location: https://example.com/very/long/path?with=params&and=more
Why 301 vs 302?
- 301 (Permanent): Browsers cache the redirect. Faster for users, but we lose analytics visibility.
- 302 (Temporary): Browser always hits our server. We can track every click.
Most URL shorteners use 302 to ensure accurate click tracking. The slight latency cost is worth the analytics data.
Analytics API: FR3 (Stretch)
Get Click Count
GET /urls/{shortCode}/stats
Response:
{
"shortCode": "abc123",
"clicks": 4521,
"createdAt": "2024-01-15T10:30:00Z"
}
This is read-only and can be eventually consistent. We'll handle the write side (recording clicks) in the deep dives.
High-Level Design
Let's start with our functional requirements:
- FR1: Create short URL from long URL
- FR2: Redirect short URL to long URL
- FR3: Track click analytics
We'll start with the simplest design and rebuild our system as things break.
1) The Simplest System: FR1, FR2 (Persistence)
Let's start with the most basic system. We can upload and fetch the URL from a database
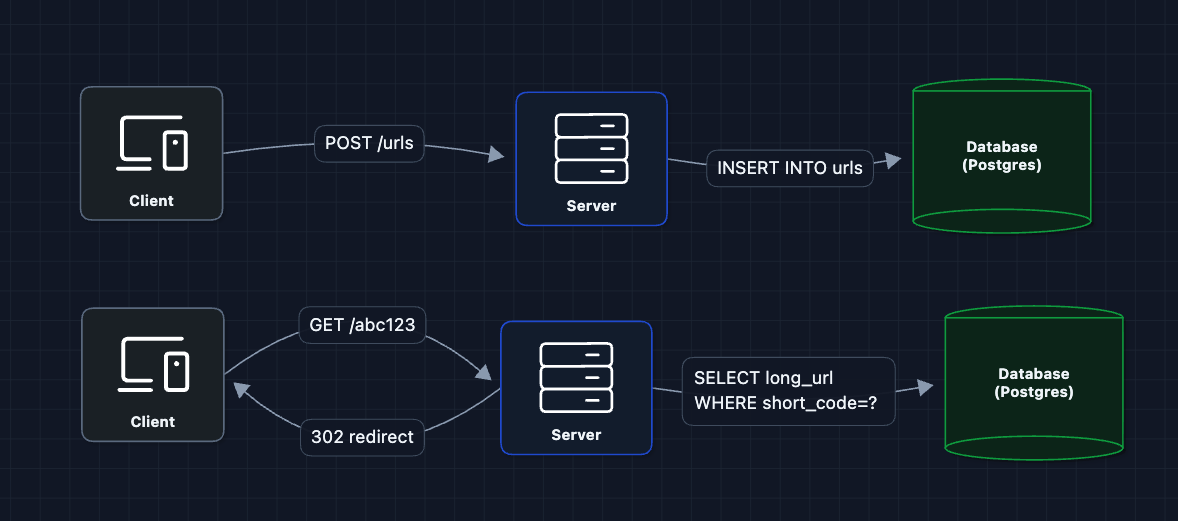
Why PostgreSQL? We need ACID reliability to prevent duplicate short codes. Since our caching layer (in the future) can handle 99% of redirects, Postgres easily manages the durable writes and remaining cache misses.
urls Table
| short_code | long_url | created_at |
|---|---|---|
abc123 | https://example.com/long/path?q=... | 2024-01-15 |
xyz789 | https://another.com/page | 2024-01-15 |
But what breaks?
- How do we generate
abc123? We haven't defined how short codes are created. - Database on every request: At 10K req/sec, we're hammering the database.
Let's solve the generation problem first.
2) Short Code Generation: FR1 (Create URL) ✅
This is the main algorithmic challenge. How do we generate unique, short codes?
Option A: Random Generation
Generate random characters and hope for no collision:

This is simple, but requires a database check on every create.
Option B: Counter-Based with Base62 Encoding
Use an auto-incrementing counter and encode it:

So, no collision checks needed! But now we have a new problem. Where does the counter live?
What breaks?
- If we have multiple servers, they can't share a counter without coordination.
- A single counter becomes a bottleneck.
We'll address distributed ID generation in the deep dives. For now, let's assume we have a working counter.
3) Add Caching for Fast Redirects: NFR1 (Latency)
The vast majority of traffic is redirects, not creates. And URL access follows a power law. A few URLs get most of the clicks (think viral tweets).
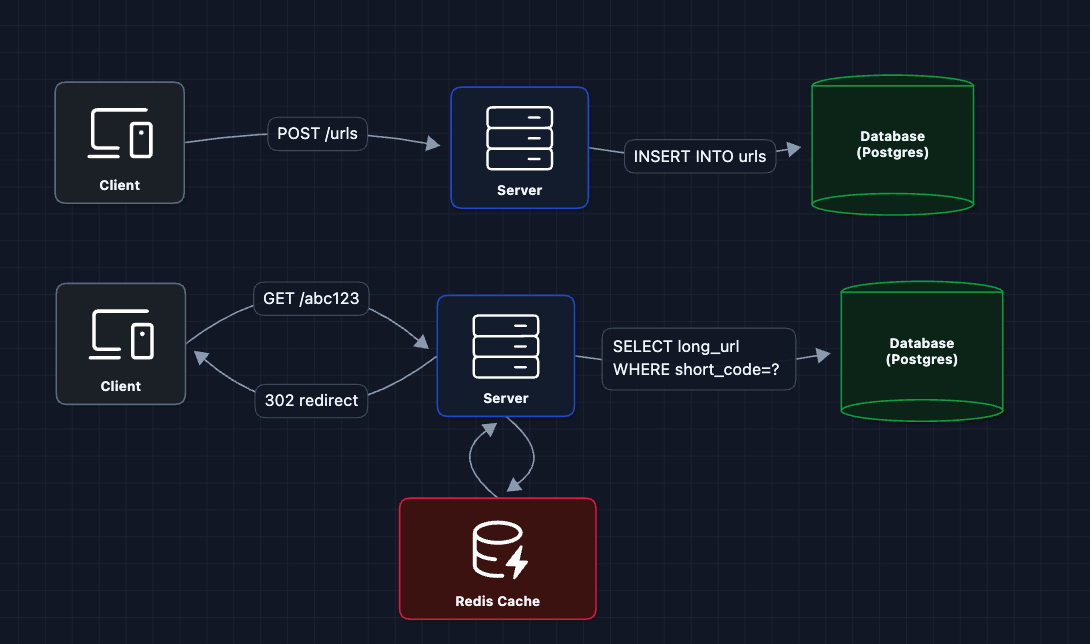
With caching, hot URLs (viral content) are served from memory in < 1ms. The database only handles cache misses.
What breaks?
- A single server still can't handle 10K requests/second.
- What if the server dies?
4) Scale Horizontally with Load Balancer: NFR3 (Scale)
To handle high traffic and provide redundancy, we add multiple servers behind a load balancer:
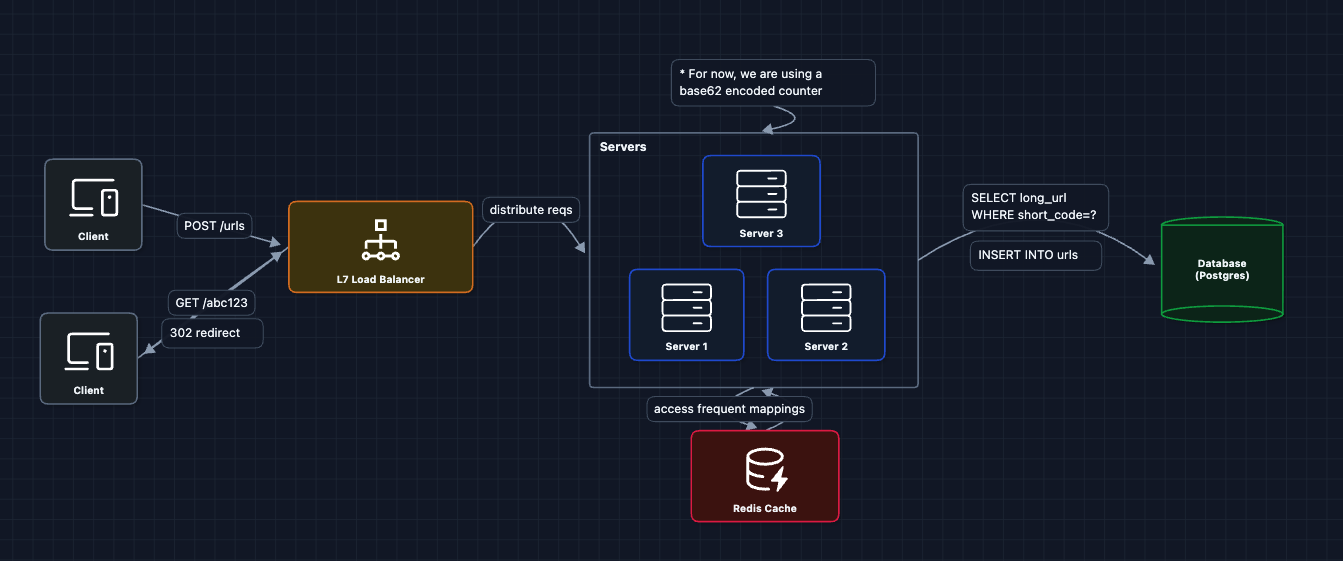
Now we can handle 10K+ requests/second by adding more servers.
What breaks?
- ID generation: With multiple servers, how do we ensure unique short codes?
- Analytics: We haven't tracked clicks yet.
5) Add Analytics Tracking: FR3 (Click Analytics)
Every redirect should record a click event. But we can't slow down redirects to write to a database.
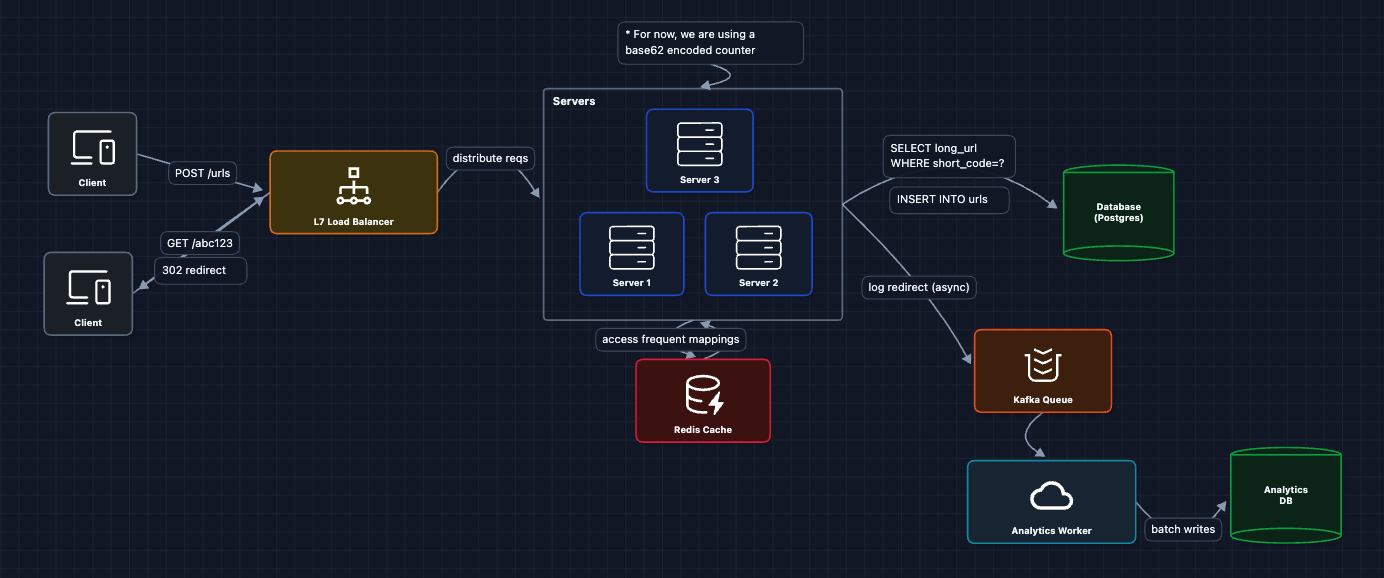
The redirect happens immediately. Analytics are recorded asynchronously through a message queue. The user never waits for analytics to be saved.
6) Complete HLD
Now we have a complete working system that satisfies all functional requirements:
- FR1 ✅ Create short URLs (Diagram 2: ID generation)
- FR2 ✅ Redirect to long URLs (Diagrams 3-4: cache and scale)
- FR3 ✅ Track analytics (Diagram 5: async pipeline)
Now we can address our non-functional requirements and more in the deep dives:
- NFR1 (Latency): How do we optimize cache hit rates?
- NFR3 (Scale): How do we shard the database for 100M+ URLs?
- NFR2 (Availability): What happens when components fail?
Potential Deep Dives
1) Distributed ID Generation
In Diagram 2, we mentioned counter-based ID generation. But with multiple servers, a shared counter creates contention. Here are some solutions:
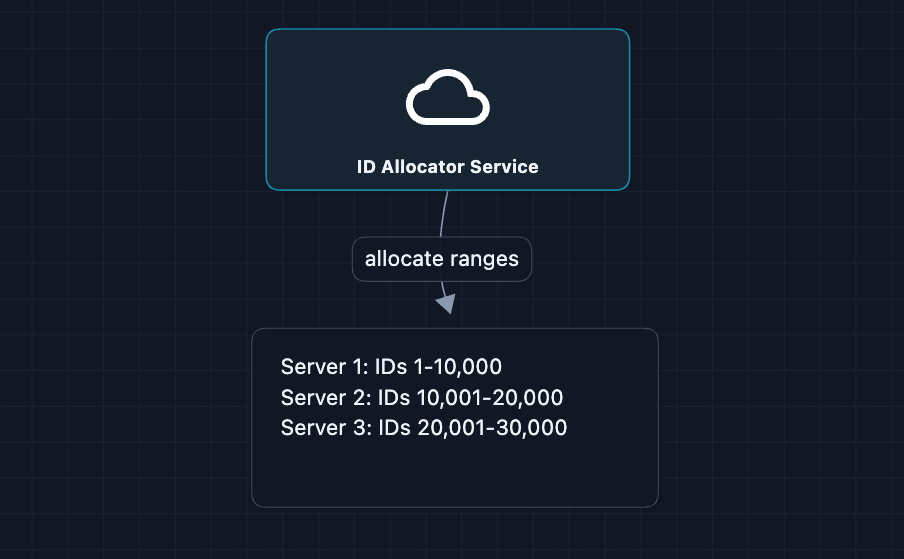
Option A: Range-Based Allocation
Each server gets a pre-allocated range (stored in a SQL database with ACID properties). The server generates IDs locally but wastes unused IDs if it crashes.
Option B: Snowflake-Style IDs
Each ID is 64 bits: [41-bit timestamp | 10-bit machine ID | 12-bit sequence]. There is no coordination needed, but IDs are longer.
Why are they longer? Encoding a 64-bit number into Base62 requires 11 characters. Because Snowflake IDs include a timestamp, they are always large numbers and will always result in 11-character codes. In contrast, sequential IDs start at 1 character and only reach 7 characters after 3.5 trillion URLs are created.
For maximum compactness (≤ 7 chars), use range allocation. For simplicity and high-scale independence, use Snowflake IDs (11 chars). For instance, Twitter uses Snowflake for tweets.
2) Optimizing Cache Hit Rate: NFR1 (Latency)
In the HLD, we have Redis. But cache efficiency matters enormously. Let's explore strategies:
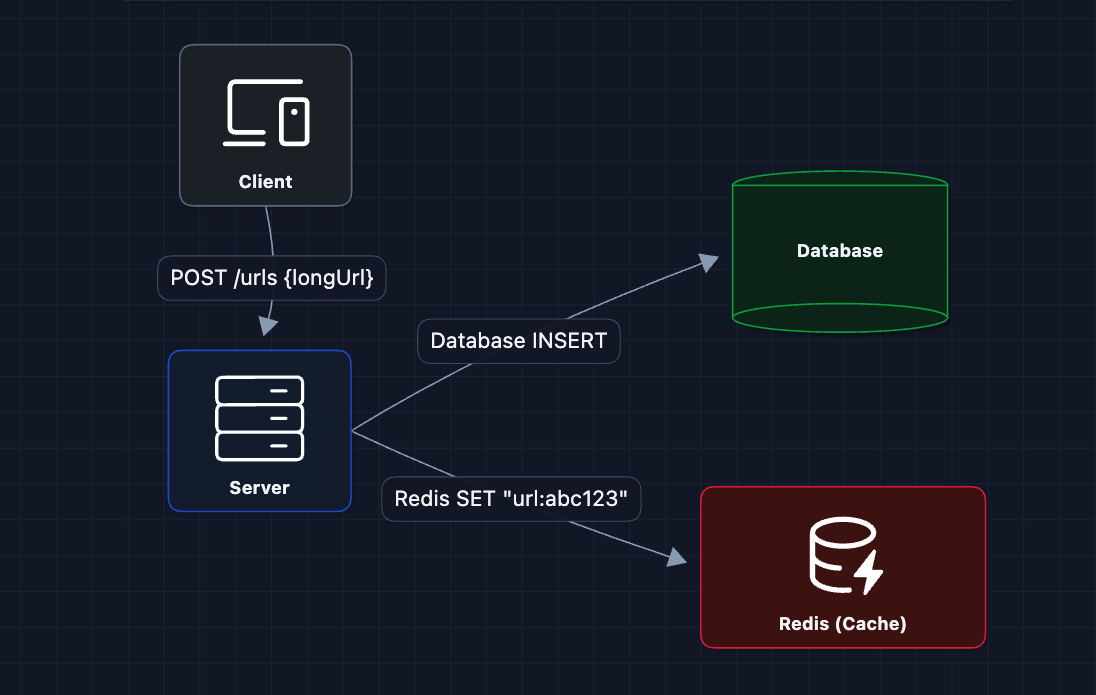
The Impact
Cache hit: < 1ms
Cache miss: 5-10ms (database query)
At 10K req/sec:
90% hit rate = 1,000 DB queries/sec
99% hit rate = 100 DB queries/sec ← 10x less load
Strategy 1: Write-Through Cache
When creating a URL, write to both database and Redis immediately.
Strategy 2: Tiered TTLs
| URL Age | Cache TTL |
|---|---|
| < 1 hour | 1 hour |
| < 1 day | 6 hours |
| < 1 week | 24 hours |
| > 1 week | 1 hour |
New URLs (viral content) stay cached longer. Old URLs evict faster.
Strategy 3: Negative Caching
Cache NOT_FOUND for invalid codes (TTL: 5 min). This prevents repeated DB queries for non-existent URLs.
3) Database Sharding: NFR3 (Scale)
A single database can hold ~100M rows, but becomes a bottleneck for writes. Here's how to shard:
Consistent Hashing (Recommended)
Instead of simple modulo math (hash % N), which requires massive data migration when adding shards, we use Consistent Hashing.
The router treats the entire range of possible hashes as a ring. Each database shard is responsible for a segment of that ring.
How it works:
- We hash the
short_codeto a number on the ring. - We move clockwise to find the first available database shard.
- To add a new shard, we just "insert" it into the ring. Only the URLs that fall into that new segment need to move.
Consistent hashing is the gold standard for distributed storage. It minimizes data movement during scaling. See the Distributed KV Store article for a deep dive on how the hash ring works.
Each shard can have read replicas for additional read scale. Write traffic is distributed across shards, so no single database becomes a bottleneck.
4) High Availability: NFR2 (99.99% Uptime)
What happens when components fail?
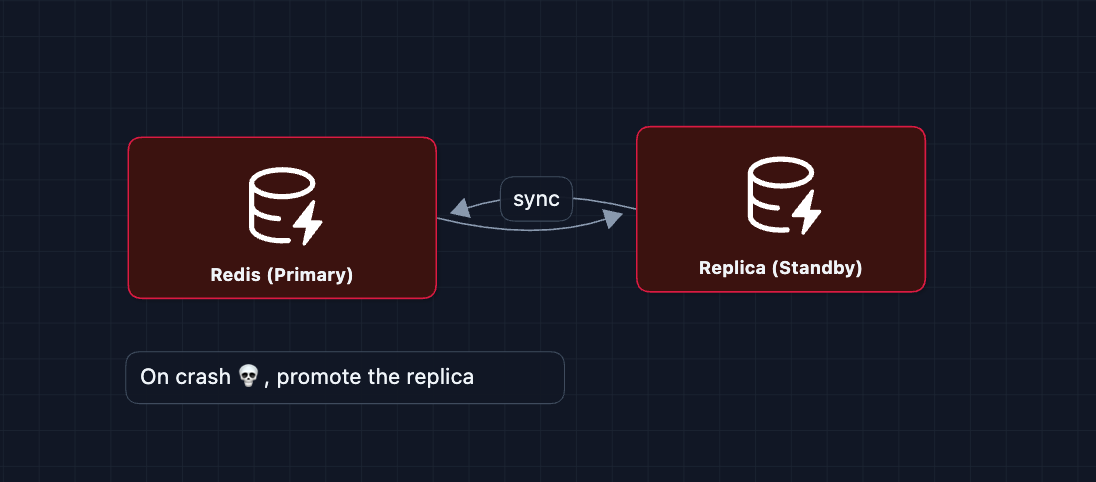
Cache Failure (Redis Down)
Servers fall back to the database. There is a higher load, but the system stays up.
- Mitigation: Redis Cluster with replication
- Circuit breaker: stop trying if errors spike
Database Failure (Primary Down)
Automatic failover promotes replica to primary. Downtime is 10-30 seconds.
Server Failure (Application Crashes)
Load balancer health checks detect failure. Traffic routes to remaining servers. No user impact with 3+ servers.
5) Handling Duplicate Long URLs
Should the same long URL always return the same short code?

Option A: Always Create New
Every request generates a new short code, even if the same long URL was shortened before. This is simple: just generate ID, store the mapping, and return.
-
Benefit: Each short URL has independent analytics. If a marketer shares
abc123on Twitter anddef456in an email, they can track which channel drove more clicks. -
Tradeoff: With millions of users shortening popular URLs (like
youtube.com/watch?v=dQw4w9WgXcQ), you create thousands of duplicate mappings.
Option B: Return Existing Short Code
Before creating a new short code, check if this long URL already exists. If yes, return the existing short code.
Implementation for Option B
CREATE INDEX idx_long_url_hash ON urls(hash(long_url));
ON POST /urls:
existing = SELECT short_code WHERE hash(long_url) = hash(?)
if existing: return existing
else: create new
-
Benefit: Saves short code space. One popular URL gets one short code, not thousands.
-
Tradeoff: All users who shortened the same URL share analytics. You can't distinguish who created which link. Also, indexing long URLs (up to 2,048 chars) is expensive.
Most production systems use Option A (always new) because analytics isolation is valuable.
What to Expect?
That covered a lot! Here's what you need at different levels.
Mid-level
- Breadth over Depth (80/20): Cover the complete flow from URL creation to redirect. Understand why caching matters.
- Expect Basic Probing: "How does Base62 encoding work?" or "Why use Redis here instead of directly querying the database?"
- The Bar: Complete the HLD. Explain the caching layer, and acknowledge the ID generation challenge and solve that as it is the main part of a short URL service.
Senior
- Balanced Breadth & Depth (60/40): You should explain ID generation trade-offs (random vs. sequential vs. Snowflake) from experience.
- Proactive Problem-Solving: Identify the read-heavy nature early and propose caching before being asked.
- Articulate Trade-offs: "Range-based IDs are more compact but waste IDs on server crashes. Snowflake IDs are longer but fully distributed."
- The Bar: Complete the full HLD and focus on 2-3 deep dives: ID generation (Deep Dive 1), caching strategies (Deep Dive 2), or sharding (Deep Dive 3).
Staff
- Depth over Breadth (40/60): Breeze through the HLD in ~10 minutes and spend time on the interesting challenges.
- Experience-Backed Decisions: Draw from real systems you've built. Explain why you'd choose PostgreSQL for its ACID reliability versus NoSQL (like Cassandra).
- Full Proactivity: Drive the entire conversation. Bring up failure modes, sharding strategies, and analytics pipelines without prompting.
- The Bar: Address all deep dives proactively. Discuss consistency guarantees, cache invalidation, and situations for failure in operation.
Practice this problem with AI and good luck on your interview! 🔗