
Design Twitter Search
Problem Context
🔍 Twitter Search handles billions of search queries across 500M+ tweets posted daily. Twitter must make new tweets searchable within seconds of posting.
Functional Requirements
Twitter Search could mean many things: searching tweets, searching users, searching hashtags, searching with filters. Clarify scope early with your interviewer. We'll focus on the tweet search.
Core Functional Requirements
- FR1: Users should be able to search tweets by keywords or hashtags.
- FR2: Search results should be ranked by relevance (recency, engagement, author credibility).
- FR3: New tweets should be searchable within 10 seconds of posting.
Out of Scope:
- User/account search (different index, different ranking).
- Advanced filters (media-only, verified-only, date ranges).
- Typeahead/autocomplete suggestions.
- Trending topics computation.
- Saved searches and search history.
Tweet search is an interesting problem because it involves full-text indexing at a very large scale.
Non-Functional Requirements
Core Non-Functional Requirements
- NFR1: Search latency should be < 200ms (p99).
- NFR2: System should be highly available (99.99%+).
- NFR3: System should handle 20K+ search queries per second.
- NFR4: Index should stay within 10 seconds of the write path.
Here's what we have so far:

Let's get going!
The Set Up
The Main Challenge
When someone searches "Super bowl," we need to find all tweets containing those words among 500 billion+ total tweets. We can't just scan every tweet. We need a way to instantly jump to the right tweets.
This is where inverted indexes come in. Instead of asking "which words are in this tweet?", we flip the question to "which tweets contain this word?". Pre-compute that mapping, and search becomes a lookup instead of a scan.
Core Entities
These entities help us reason about data flow. The inverted index is our main entity.
Tweet (the document we're searching)
{
tweetId: "twt_abc123",
authorId: "user_456",
content: "Just watched the world cup final! Amazing game",
createdAt: "2026-01-10T14:30:00Z",
engagementScore: 4520 // likes + retweets + replies
}
Inverted Index Entry
{
term: "Super",
postingList: [
{tweetId: "twt_abc123", score: 0.82, positions: [3]},
{tweetId: "twt_def456", score: 0.65, positions: [0, 7]},
...
]
}
Think of this like the index at the back of a textbook. Instead of reading the whole book to find "Super", you go to the index, find "Super", and it lists every tweet where it appears.
positions: This tells us where the word appears in the tweet. We need this to tell the difference between "Super Bowl" and "Bowl Super".score: This measures how well this tweet matches this specific word. It combines things we know at creation time: Term Frequency and Tweet Popularity (is the author verified?). We perform this math now to save time later.
Search Query
{
query: "Super bowl",
limit: 20,
cursor: "cursor_xyz"
}
API Interface
We have one main endpoint for search:
Search Tweets
GET /api/v1/search?q={query}&limit=20&cursor={cursor}
Example:
GET /api/v1/search?q=world%20cup%20final&limit=20
Response:
{
"results": [
{
"tweetId": "twt_abc123",
"authorId": "user_456",
"authorUsername": "soccerfan",
"content": "Just watched the world cup final! Amazing game",
"createdAt": "2026-01-10T14:30:00Z",
"relevanceScore": 0.92
},
// ... more results
],
"nextCursor": "cursor_next_page",
"totalEstimate": 145000
}
What happens behind the scenes?
- Parse query into individual terms: ["world", "cup", "final"]
- Look up each term in the inverted index
- Find tweets that match ALL terms (intersection)
- Rank by relevance (engagement, recency, author authority)
- Return top results with pagination cursor
Deep pagination is expensive. To get results 1000 to 1020, each shard must return its top 1020, not just 20, because Shard 1's #21 might beat Shard 3's #1 globally. The fix is to cap max results or use search_after cursors that let shards skip ahead.
High-Level Design
We'll start with The simplest solution and fix problems as they arise. Our goal is to satisfy FR1 (search), FR2 (ranking), and FR3 (freshness).
In an interview, acknowledge you're starting simple. Try and build the working system first, then optimize (you can note possible issues with your interviewer but you will address them in the deep dives).
1) Starting from the Simplest Point: Database Query
When someone searches "world cup," just query the database:
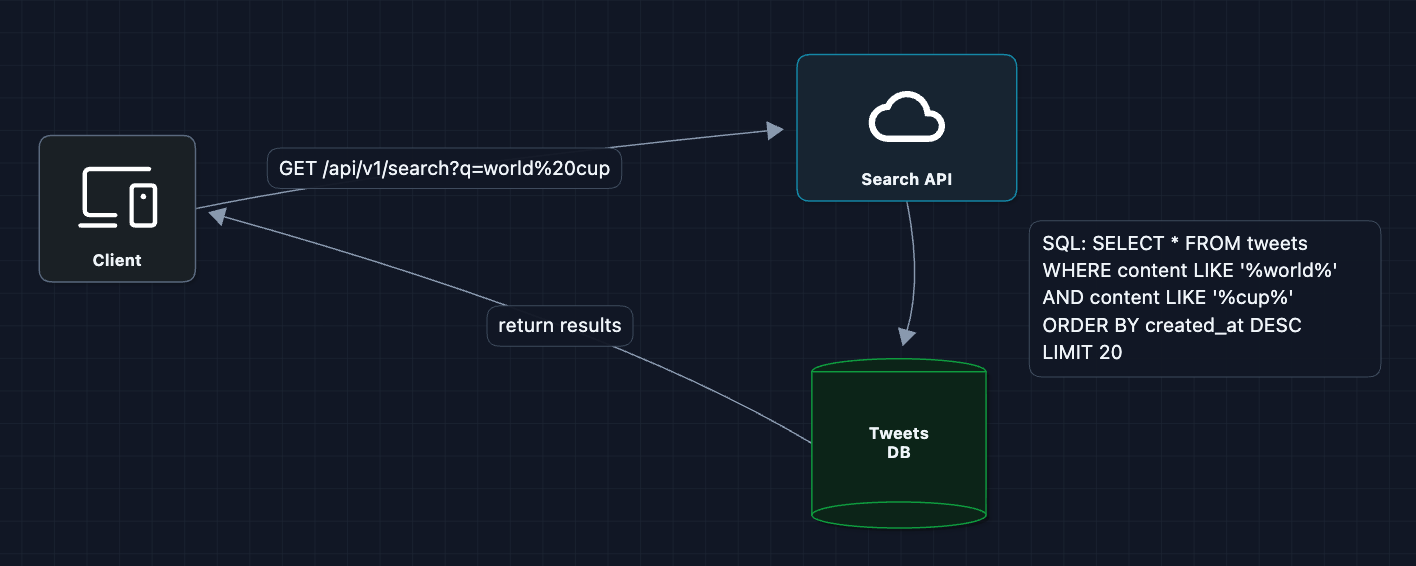
The database scans for matching rows and returns them.
Why does this break immediately?
- Full table scan:
LIKE '%word%'can't use indexes (it scans every row) - 500 billion rows × 20K queries/sec is impossible
- Response time: Scanning billions of rows takes minutes, not milliseconds
We need a fundamentally different data structure.
2) Introduce the Inverted Index: FR1 (Search)
Instead of scanning tweets for words, let's pre-compute which tweets contain each word:
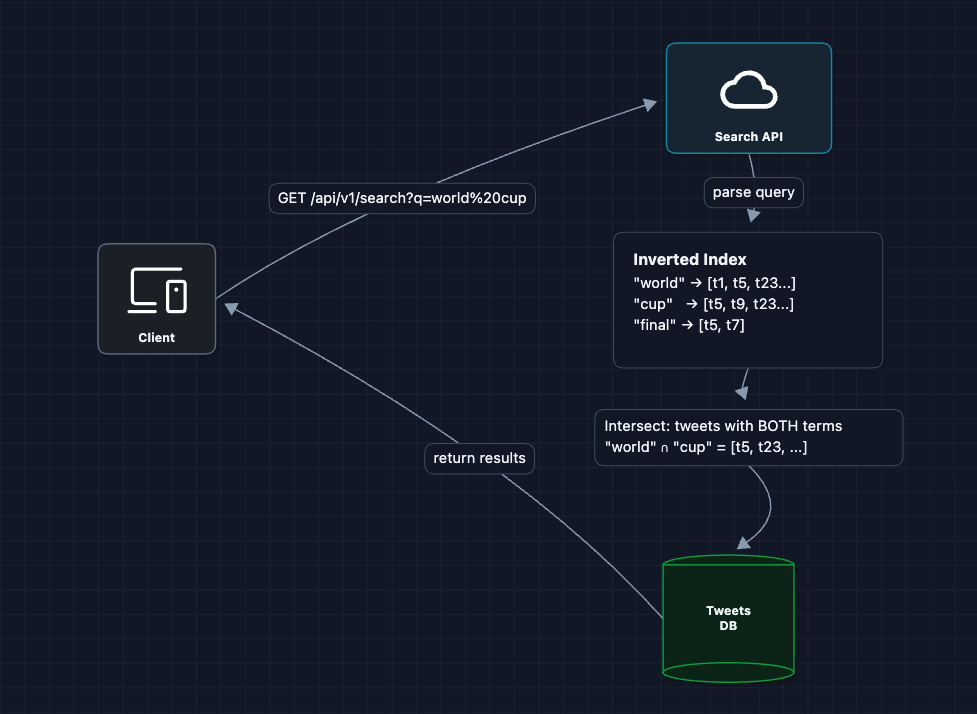
Now search is a lookup, not a scan! We find matching tweets in O(1) per term.
What's a posting list? The list [t1, t5, t23...] next to each term is the posting list (all tweets containing that word).
Do we index every word? No. Common words like "the", "a", "is" (called stop words) are filtered out. We also lowercase everything and may stem words.
What breaks?
- Scale: The index itself is massive (every word in 500B tweets)
- Single server: One machine can't hold the entire index in memory
- Write path: How do new tweets get into the index?
We need to split this index across multiple servers.
3) Shard the Index: FR1 (Search at Scale)
One server can't hold 500 billion tweets. Let's partition:
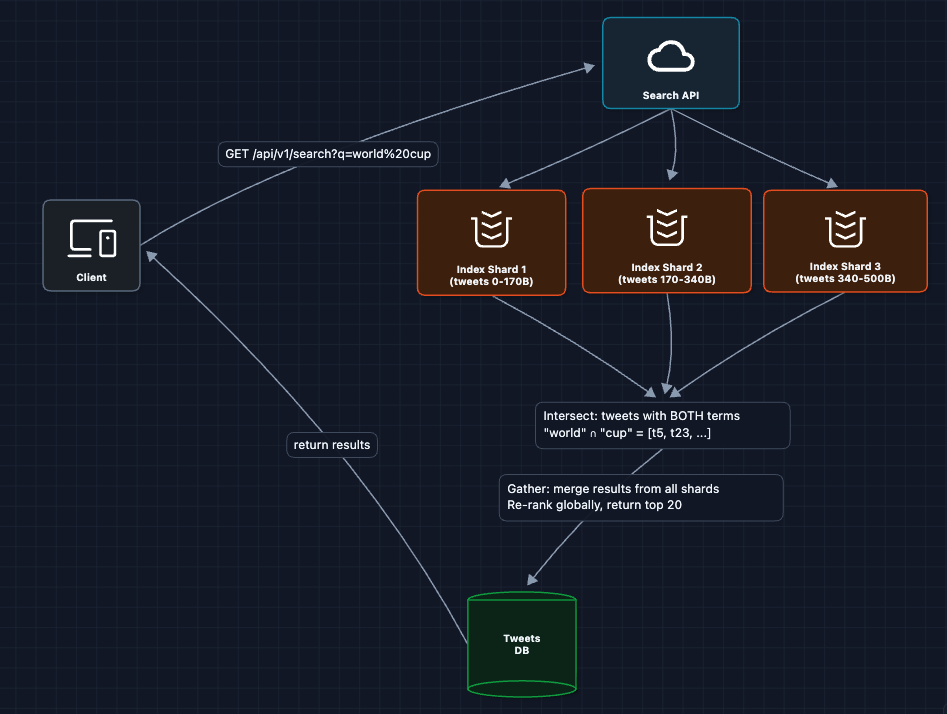
Why document-based sharding?
We could shard by term, but then:
- We would create hot spots
- Multi-word queries would still hit all shards
Document-based means each shard is self-contained. Every shard can independently answer "which of MY tweets match this query?"
What breaks?
- No write path: How do newly posted tweets get indexed?
- Latency: All shards must respond before we can return results
- Availability: If one shard dies, queries fail
Let's add the indexing pipeline.
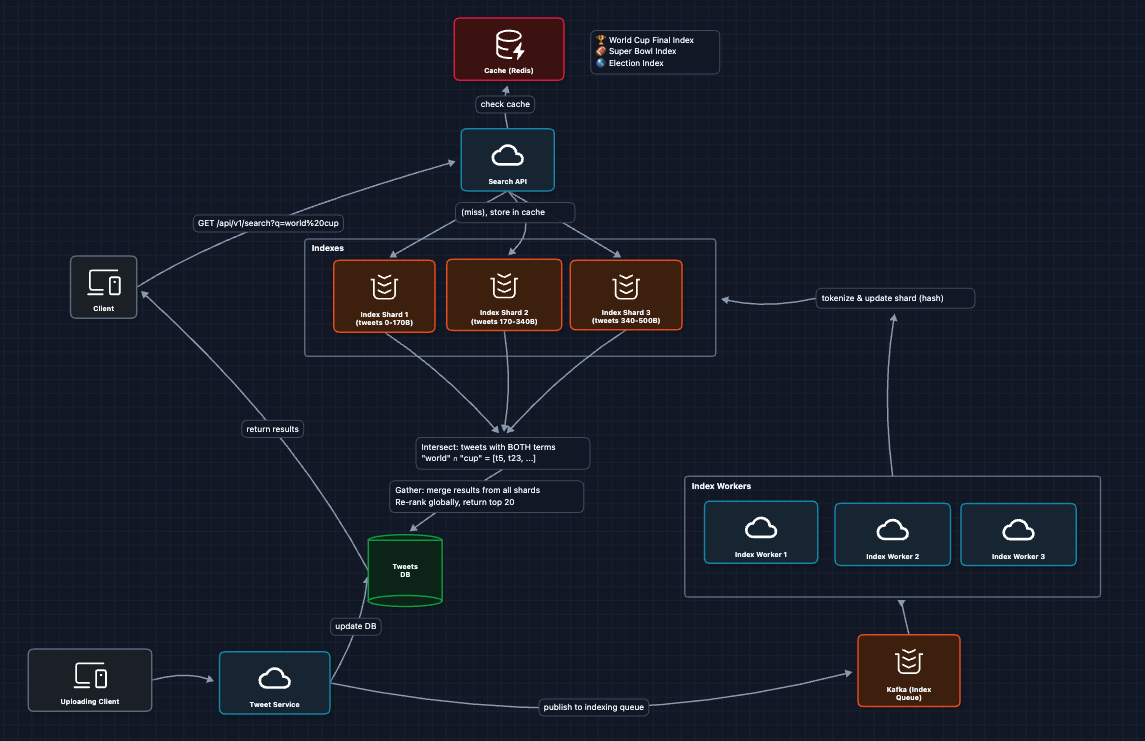
4) Add Real-time Indexing Pipeline: FR3, NFR4 (Freshness)
When a user posts a tweet, it needs to be searchable within 10 seconds. We need an async pipeline:
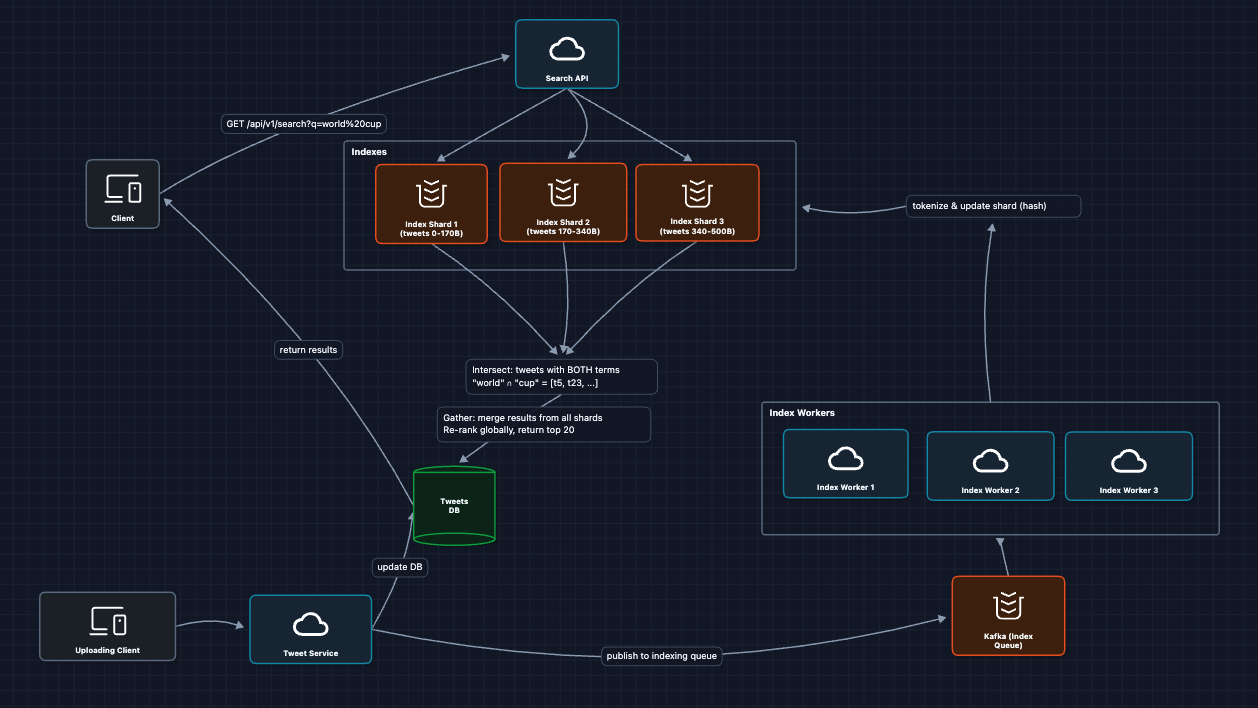
What we added:
- Kafka for reliable async processing
- Index Workers that tokenize and route tweets to shards
- Decoupled write path from read path
Tokenization explained:
Input: "Germany wins World Cup! 🏆 #WorldCup2026"
Output: ["germany", "wins", "world", "cup", "worldcup2026"]
Steps:
1. Lowercase everything
2. Remove punctuation
3. Extract hashtags as terms
4. Optionally stem words ("winning" → "win")
What breaks?
- Hot queries: When something trends, millions search the same terms
- Response time degrades under high load
We need caching.
5) Add Caching for Hot Queries: NFR1, NFR3 (Latency & Scale)
Trending topics create massive query hotspots. "World cup final" might get searched 100K times per second during the match. Let's cache:
Cache hit rates during trending events:
- "Super bowl" during game: 98% cache hit rate
- Random obscure query: 5% cache hit rate
- Average across all queries: 40-60%
Caching offloads massive pressure from the index shards during spikes.
Complete System
This is our baseline architecture!
We satisfy all functional requirements:
- FR1 ✅ Search tweets by keywords (inverted index + scatter-gather)
- FR2 ✅ Ranked by relevance (ranking step after gather)
- FR3 ✅ Searchable within 10 seconds (Kafka + workers pipeline)
Now we can address some of our non-functional requirements in the deep dives:
- NFR1 (Latency): How does the inverted index actually work?
- NFR3 (Scale): How do we shard effectively?
- NFR1 (Latency): How do we rank results quickly?
- NFR3 (Scale): How do we handle trending queries?
Potential Deep Dives
1) How does the Inverted Index actually work?: NFR1 (Latency)
In Diagram 2, we introduced the inverted index. Let's look inside.
The posting list structure:
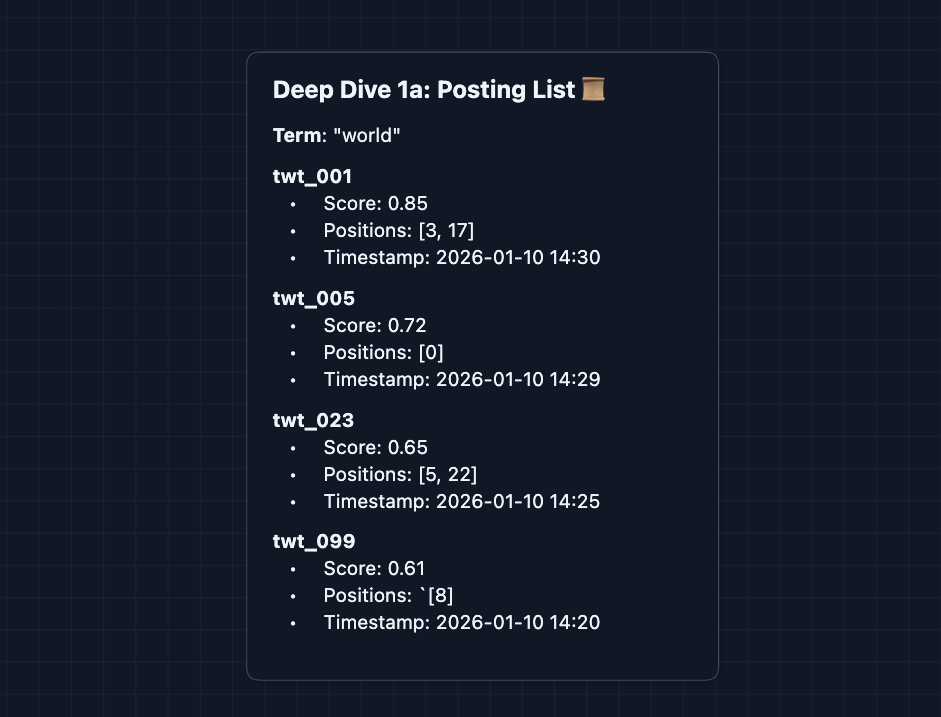
Key Components:
- Score: A static rating calculated at creation. It measures how relevant this word is to this tweet (is it in the title? is the author verified?). It serves as a baseline quality score.
- Positions: Where in the tweet the term appears (needed for phrase matching).
- Timestamp: Critical for recency-based ranking (showing new tweets first).
Multi-term query (intersection):

The intersection logic:
From our example up above, we're looking for IDs in BOTH lists. List A (world) is at ID 1. List B (cup) is at ID 5.
Can the t1 post exist in the second list? No. The IDs are sorted by time. List B starts at 5 and only gets bigger, so we skip t1 and advance List A.
Why Snowflake IDs matter here:
Twitter uses Snowflake IDs: 64-bit integers that are time-ordered. A tweet posted at 2:00 PM always has a lower ID than one posted at 2:01 PM.
64 bits = [1 unused][41 timestamp][10 machine ID][12 sequence]
Timestamp bits dominate → IDs naturally sort by time
Sequence bits → multiple tweets/ms on same machine
Because tweet IDs are time-ordered, our posting lists are automatically sorted by time. This gives us two wins:
- Fast intersection: We use a two-pointer merge. O(n + m) instead of O(n × m).
- Recency for free: The end of the list always has the newest tweets.
Why sorted lists? Intersection of two sorted lists is O(n + m). Unsorted would require O(n × m) comparisons. When posting lists have millions of entries, this matters enormously.
Storage optimization (Delta Encoding):
Snowflake IDs (8 bytes each):
[1357924680000000001, 1357924680000004523, 1357924680000009102, ...]
Deltas (variable-length):
[1357924680000000001, +4522, +4579, ...]
Since Snowflake IDs are time-ordered, tweets about the same term posted around the same time have IDs that are close together. The deltas are thousands or millions, not quintillions. Variable-length encoding stores small deltas in 1-3 bytes instead of 8.
Result: 4-8x compression, fitting more index in RAM.
2) How do we shard the index effectively?: NFR3 (Scale)
In Diagram 3, we partitioned the index into shards. There are two strategies:
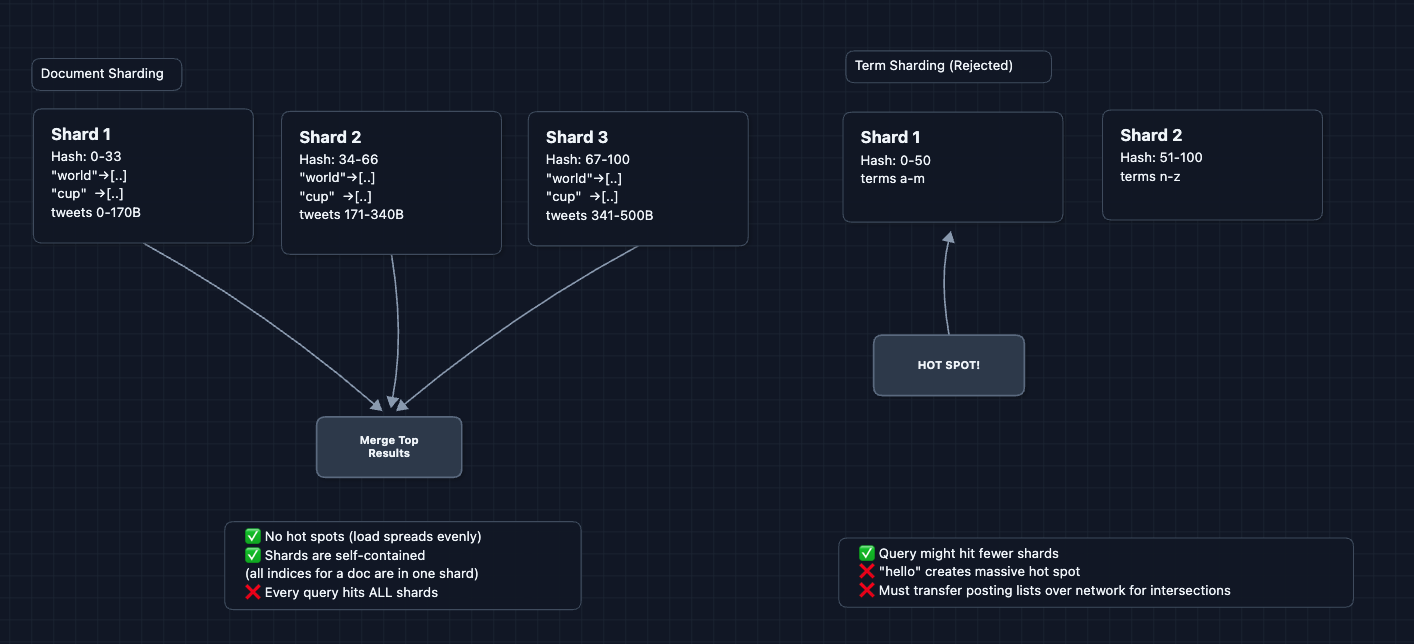
Using document sharding feels kind of obvious, but this is how you can defend your case if the interviewer asks.
The example above uses consistent hashing. Check out the Distributed KV Store article for more details on how this helps distribution.
The scatter-gather problem:
Hitting 1,000 shards for every query creates massive internal traffic, and latency equals the slowest shard. The fix is hot/cold tiering.
We split the index into two tiers based on time:
- Hot Index (Memory): Stores recent tweets (ex. last 2 weeks) on high-RAM servers. Since 99% of searches are for recent events, they only hit these ~50 shards.
- Cold Index (Disk): Stores older tweets on cheaper disk-based storage. These ~1000 shards are only queried when users explicitly search for historical data.
Most searches care about recent tweets. By separating hot from cold, we dramatically reduce the shards hit per query.
3) How do we rank search results?
We can't run complex ranking on millions of matches. The solution is two-phase ranking.
We use a Scatter-Gather approach with two phases:
- Phase 1 (Scatter): Each shard finds its top 100 matches using the static score and sends them to a central ranker.
- Phase 2 (Gather): The ranker collects the candidates from all shards (ex. 300 total) and re-ranks them using heavier Machine Learning models that consider social signals (likes by friends) and personalization.
This allows us to select the best content without running expensive models on billions of tweets.
Recency decay:
Age Score
───────── ─────
5 min ago 0.99
1 hour ago 0.91
24 hours ago 0.29
1 week ago 0.06
Recent tweets get big boosts. Old tweets can still appear if highly relevant, but rank lower.
4) How do we handle trending queries?: NFR3 (Scale)
During major events, millions search the same thing simultaneously. Normal load is 20K queries/sec but a World Cup goal can spike to 300K queries/sec (15x!).
To handle massive spikes, we use a layered defense:
- Caching: This is the most important layer here. We can cache search results for hot queries ("goal"). Even a 10-second cache absorbs 95% of spiking traffic.
- Request Coalescing: If 1000 requests for "goal" arrive at once, we execute the query once and return the result to all 1000 users.
- Hot Term Replication: If a specific term is overloading a specific Index Shard, we replicate its posting list to other shards to spread the load.
- Graceful Degradation: If the system is overwhelmed, return slightly stale results (30s old) instead of failing.
What to Expect?
That covered a lot of ground. Here's what matters at each level.
Mid-level
- Breadth over Depth (80/20): Cover the end-to-end flow from query to results. Know what an inverted index IS, why we need it, and how sharding works at a conceptual level.
- Expect Basic Probing: "Why can't we use SQL LIKE?" "What's the problem with everything on just one server?"
- Assisted Driving: You design the read path first, then may need a little assistance with the write path (indexing pipeline).
- The Bar: Complete the HLD. Explain why inverted indexes are necessary. Know that sharding and caching exist even if you don't get as far in detail.
Senior
- Balanced Breadth & Depth (60/40): You should comfortably explain inverted index internals, sharding tradeoffs, and real-time indexing. Pick 2-3 deep dives to really own.
- Proactive Problem-Solving: You identify the hot query problem before asked. You mention "we need to cache trending queries" without prompting.
- Articulate Trade-offs: "Scatter-gather here allows us to scale horizontally, but it introduces tail latency. Basically, the entire search request is only as fast as the slowest shard."
- The Bar: Complete all 6 diagrams, proactively discuss at least 2 deep dives (inverted index internals, sharding strategy OR ranking approach).
Staff
- Depth over Breadth (40/60): Breeze through the HLD in 15 minutes (the interviewer assumes you know search basics). Spend time on the hard problems: ranking tradeoffs, handling viral moments, consistency vs freshness.
- Experience-Backed Decisions: "In my experience with Elasticsearch, the default refresh interval of 1 second is often too slow for real-time search. We tuned it to 200ms with these tradeoffs..."
- Full Proactivity: You drive the conversation. You bring up problems the interviewer didn't ask about: "What about deleted tweets? We need to handle tombstones in the index."
- The Bar: Address ALL deep dives without prompting. Discuss operational concerns (monitoring, debugging slow queries, capacity planning). Know the real-world systems (Elasticsearch, Lucene) and their limitations.
Do a mock interview of this question with AI & pass your real interview. Good luck! 🔍