
Design Job Scheduler (Distributed CRON)
Problem Context
⏰ A job scheduler is a system that executes tasks at specified times or intervals.
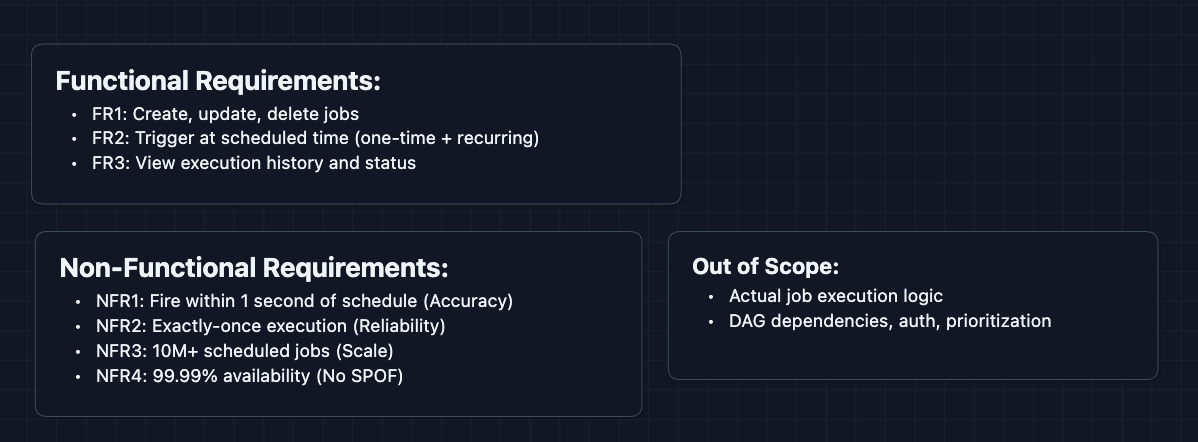
Functional Requirements
Core Functional Requirements
- FR1: Users should be able to create, update, and delete scheduled jobs.
- FR2: The system should trigger jobs at their scheduled time (one-time or recurring).
- FR3: Users should be able to view job execution history and status.
Out of Scope:
- The actual job execution logic (we trigger a callback URL).
- Complex DAG dependencies (that's Airflow's domain).
- User authentication and authorization.
- Job prioritization and resource allocation.
In an interview, explicitly stating what's out of scope for this system prevents scope creep and shows product thinking to your interviewer.
Non-Functional Requirements
Core Non-Functional Requirements
- NFR1: Jobs should fire within 1 second of their scheduled time.
- NFR2: Jobs must execute exactly once (no duplicates or misses).
- NFR3: System should handle 10M+ scheduled jobs.
- NFR4: 99.99% availability with no single point of failure.
Here's what we have so far:
Let's build this system.
The Set Up
Planning the Approach
We have two main paths through the system:
- Job Management: Users create and configure jobs (CRUD operations).
- Job Execution: The scheduler detects due jobs and triggers them reliably.
The complexity lives in execution: ensuring jobs run on time, exactly once, even when machines fail.
In an interview, start with a working system before optimizing. Note the flaws to you interviewer but also that you will address them in the deep dives.
Defining the Core Entities
- Job: The scheduled task itself (ID, name, schedule, callback URL, payload).
- Schedule: When to run. This can be either a CRON expression (
0 9 * * *= 9am daily) or a one-time timestamp. - Execution: A single run of a job (execution ID, status, start time, end time, result).
CRON expressions follow the format: minute hour day-of-month month day-of-week. For example, */5 * * * * means "every 5 minutes."
API Interface
Our APIs serve two purposes: Job Management (external, for users) and Execution Callbacks (internal, how we trigger jobs).
Job Management APIs (External): FR1, FR3
These are how users interact with the scheduler.
1. Create Job
POST /api/v1/jobs
Request:
{
"name": "daily-report-generator",
"schedule": "0 9 * * *", // CRON: 9am every day
"callback_url": "https://reports.internal/generate",
"payload": { "report_type": "sales" }
}
Response:
{
"job_id": "job_abc123",
"next_run_at": "2024-01-12T09:00:00Z"
}
The callback_url is where we send an HTTP POST when the job is due.
2. Get Job
GET /api/v1/jobs/{job_id}
Response:
{
"job_id": "job_abc123",
"name": "daily-report-generator",
"schedule": "0 9 * * *",
"next_run_at": "2024-01-12T09:00:00Z"
}
3. Update Job
PUT /api/v1/jobs/{job_id}
Request:
{
"schedule": "0 10 * * *" // Changed to 10am
}
Response:
{
"next_run_at": "2024-01-12T10:00:00Z"
}
4. List Executions
GET /api/v1/jobs/{job_id}/executions?limit=10
Response:
{
"executions": [
{
"execution_id": "exec_xyz789",
"status": "success",
"started_at": "2024-01-11T09:00:00Z",
"http_status": 200
},
{
"execution_id": "exec_xyz788",
"status": "failed",
"started_at": "2024-01-10T09:00:00Z",
"error": "Connection timeout"
}
]
}
This supports FR3 (viewing execution history).
High-Level Design
Let's build a HLD that satisfies all functional requirements:
- FR1: Create/update/delete jobs
- FR2: Trigger at scheduled time
- FR3: View execution history
We'll start from the basics to get a working system and then we will rebuild to address scale.
1) Single Server Polling
Let's start with one server and a database. The server wakes up periodically, checks for due jobs, and executes them.
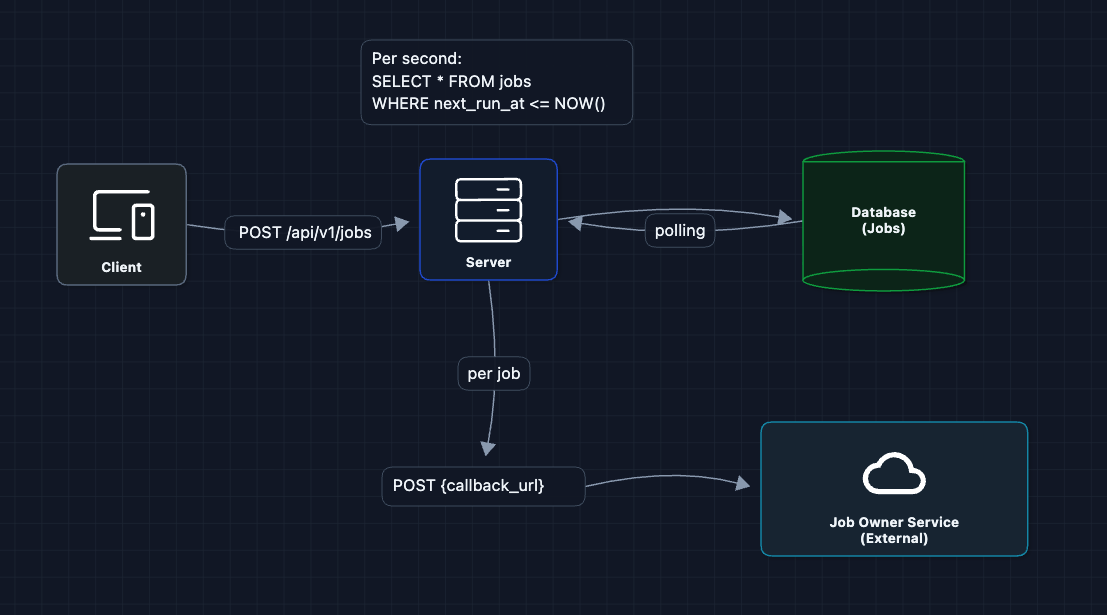
This works! Users create jobs (FR1), the server triggers them (FR2), and we could log executions (FR3).
But what breaks?
- Polling is inefficient: We're querying ALL jobs every second. At 10M jobs, this is expensive.
- Single point of failure: If the server dies, nothing runs.
- No exactly-once guarantee: If the server crashes after calling the callback but before updating the database, restarting could trigger the job again.
2) Priority Queue
Instead of scanning all jobs, we keep them sorted by next_run_at. The soonest job is always at the top, so we just check if the top job is due. We use a min-heap (priority queue) to keep jobs sorted.
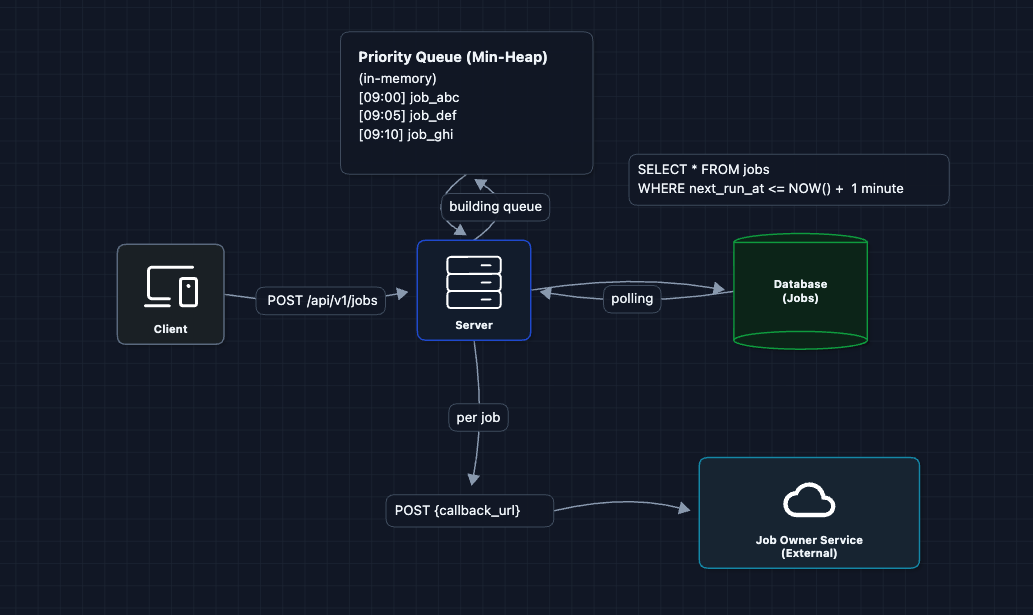
Now we only process jobs that are actually due efficiently.
But what breaks?
- Still a single point of failure: One server crash stops everything.
- In-memory queue is volatile: Server restart loses state.
- Can't scale: One server can only trigger so many callbacks per second.
3) Distributed Workers: Multiple Schedulers
Let's add multiple scheduler instances for availability and throughput.
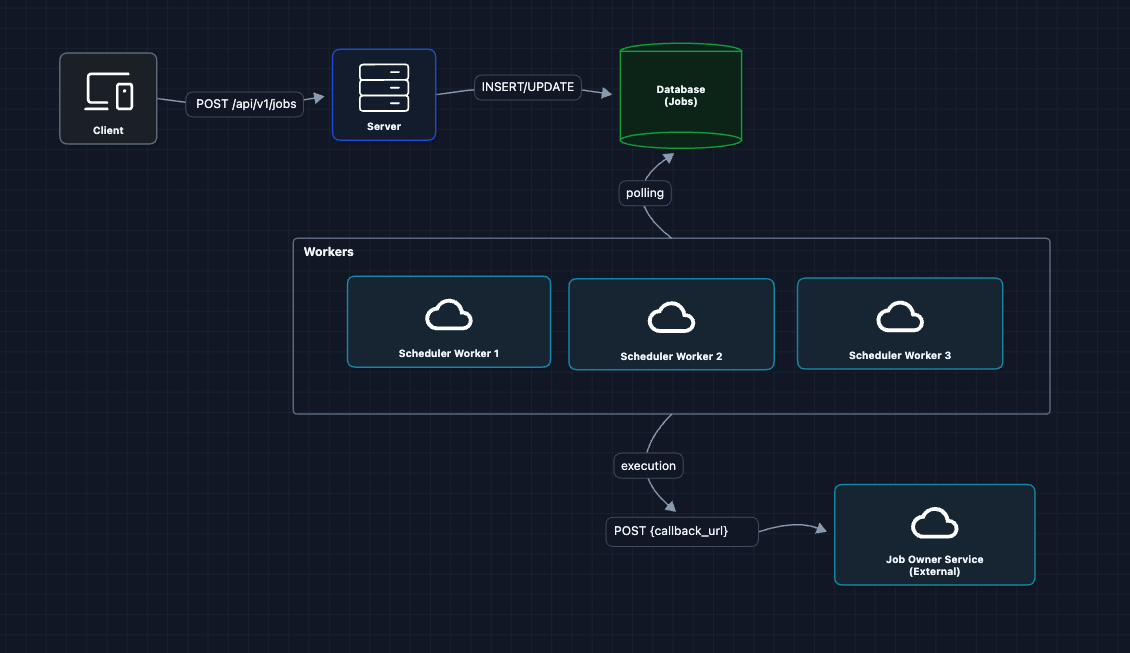
Each worker polls the database independently. More workers means more throughput, and if one dies, others continue.
But what breaks?
- Duplicate execution: If Worker 1 and Worker 2 both poll at 09:00:00, they might both see
job_abcis due and both execute it. Sending two daily reports is not good.
This is the main challenge of distributed schedulers.
4) Distributed Locking
To prevent duplicates, workers must claim a job before executing it. We use a lock so that only one worker can hold the lock at a time.
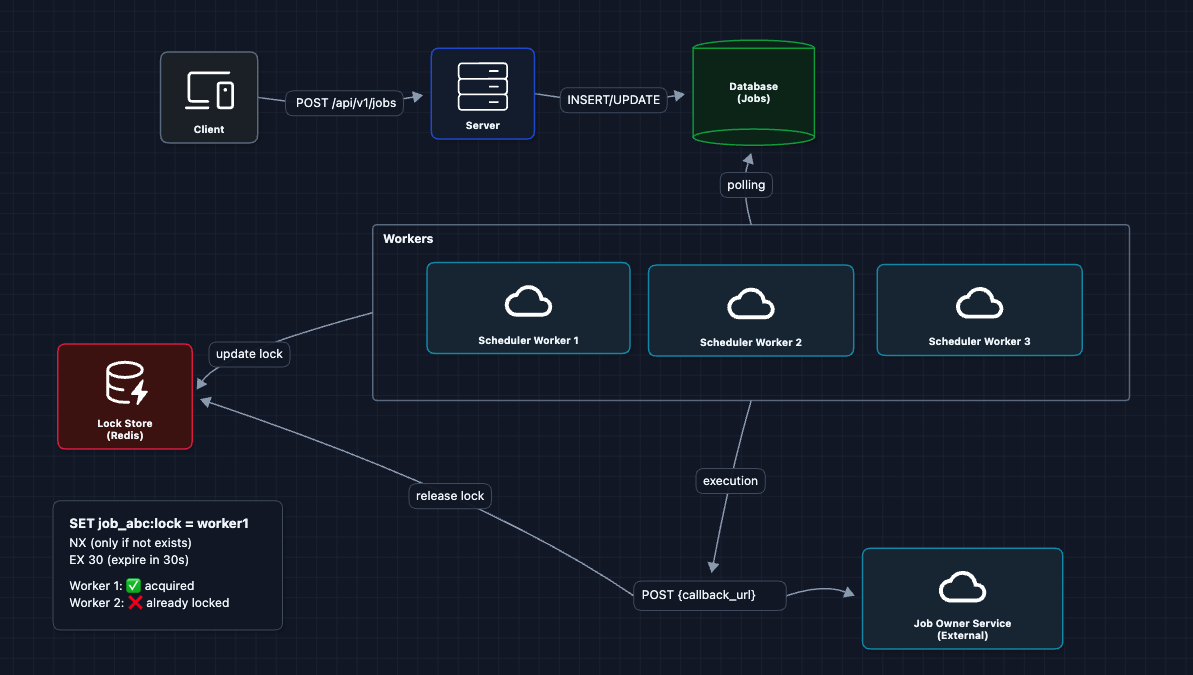
Redis SET NX EX is atomic, so only one worker wins the lock. The expiration (EX 30) is a safety net. If Worker 1 crashes, the lock auto-releases after 30 seconds.
But what breaks?
- Lock contention at scale: With 10M jobs, many becoming due at once (all "hourly" jobs at :00), workers fight over the same jobs. Redis becomes a bottleneck.
- Thundering herd: At popular times (top of the hour), many jobs become due simultaneously.
5) Scaling: Partition Jobs Across Workers
Instead of all workers competing for all jobs, we partition jobs so each worker owns a subset. Workers only process their assigned partitions.
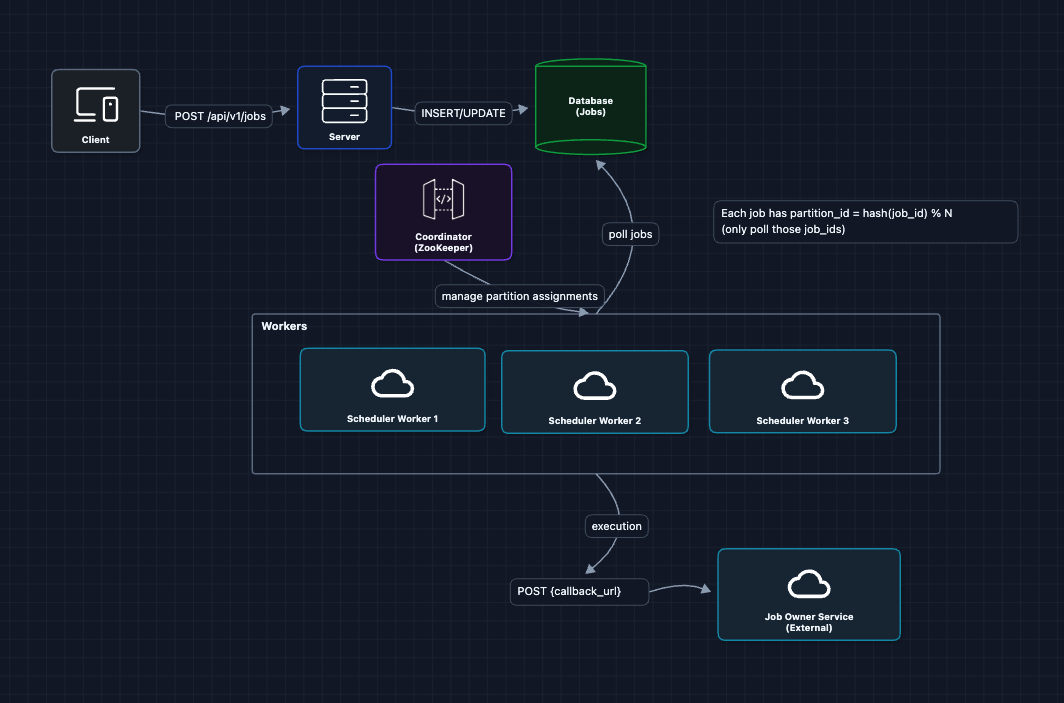
Now Worker 1 only queries: SELECT * FROM jobs WHERE partition_id = 0 AND next_run_at <= NOW(). No more lock contention!
But what breaks?
- What if Worker 1 dies? Partition 0 jobs stop running.
- How do workers know their assignments? We need coordination.
- What if we reassign partitions? During rebalancing, both the old worker (zombie) and new owner might execute the same job, causing duplicates.
We'll address these in the deep dives.
6) Complete HLD: FR1, FR2, FR3 ✅
Database Tables:
- Jobs Table:
job_id,name,schedule,callback_url,payload,next_run_at,partition_id,status,created_at- The
partition_idis calculated using consistent hashing when the job is created
- The
- Executions: Not shown in the main diagram, but we can asynchronously save execution results (status, retries, etc.) to a separate table or log store for history and debugging.
This is our baseline architecture. We've satisfied:
- FR1 ✅ CRUD via API Service
- FR2 ✅ Workers trigger jobs at scheduled time
- FR3 ✅ Executions logged and queryable
Now we can address our non-functional requirements in the deep dives:
- NFR1 (Accuracy): How do we ensure jobs fire within 1 second?
- NFR2 (Exactly-once): How do we guarantee no duplicates even with failures?
- NFR3 (Scale): How do we handle 10M+ jobs?
- NFR4 (Availability): What happens when workers or the coordinator fail?
Potential Deep Dives
1) How do we guarantee exactly-once execution?: NFR2
Partitions ensure only one worker processes each job, but what if a worker crashes and the partition is reassigned?

The callback service must implement idempotency: store the idempotency key and response for ~24 hours. If the same key arrives again, return the cached response without re-executing.
2) How do we maintain timing accuracy at scale?: NFR1
With 10M jobs, we can't poll them all every second. And jobs clustered at popular times (top of the hour) create spikes.
Problem: Thundering herd at :00

Fix: Time-bucketed pre-fetching
Instead of waiting until 09:00:00 to discover due jobs, workers fetch upcoming jobs in advance and hold them in memory.

Workers continuously pre-fetch. By the time 09:00:00 arrives, jobs are already loaded.
This shifts database load from execution time (when precision matters) to earlier (when we have slack).
Handling updates: If a user updates a job's schedule, the API Service can push an invalidation message to workers. Workers discard the stale pre-fetched job and re-query if needed.
3) How do we handle 10M+ jobs?: NFR3
We covered partitioning in the HLD. Let's go deeper on the strategy.
When jobs are created, we assign them a partition_id using consistent hashing and store it in the jobs table. Workers query only their assigned partitions: SELECT * FROM jobs WHERE partition_id IN (0, 1, 2) AND next_run_at <= NOW().
Option 1: Consistent hashing to distribute jobs across workers (what we use)

Consistent hashing ensures minimal data movement when scaling. See the Distributed KV Store article for a deep dive on how consistent hashing works.
Option 2: Time-range partitioning

Hybrid: Use consistent hashing with enough partitions (like 1024) to spread load. Combined with time-bucketed pre-fetching, this handles scale well.
Database Sharding: The database itself can also be sharded by partition_id using consistent hashing. Each database shard contains jobs for specific partitions. Workers query the appropriate shard based on their assigned partitions.
4) What happens when a worker dies?: NFR4
The coordinator (ZooKeeper/etcd) detects failures and reassigns partitions.

Heartbeats: Workers send periodic heartbeats to the coordinator (ex. every 3 seconds). If the coordinator misses N consecutive heartbeats, it considers the worker dead.
There's a trade-off: shorter heartbeat intervals mean faster failure detection but more overhead. Typical values are 3s heartbeat, 10s failure threshold.
What to Expect?
Let's summarize what you should cover at each level.
Mid-level
- Breadth over Depth (80/20): Get to a working system (the HLD). Understand why we need partitioning, even if you can't explain all edge cases.
- Expect Probing: The interviewer may ask, "What happens if a worker dies?" or "How do you prevent running a job twice?"
- Assisted Driving: The interviewer may guide you through trickier parts.
- The Bar: Complete the HLD and demonstrate you understand the key challenges in the deep dives (exactly-once, scale, timing accuracy).
Senior
- Balanced Breadth & Depth (60/40): Quickly build the HLD, then dive into 2-3 critical areas based on interviewer questions or NFRs you identify as most important.
- Proactive Problem-Solving: You identify issues before the interviewer: "At scale, we'll have thundering herds at popular times. Here's how we handle that..."
- Articulate Trade-offs: "Consistent hashing gives us better scaling properties when adding partitions, but time-range partitioning would spread thundering herds more naturally at the cost of complexity."
- The Bar: Design the full system and explain solutions to the key challenges (exactly-once semantics, timing accuracy at scale, and failure recovery).
Staff
- Depth over Breadth (40/60): Breeze through the HLD in ~15 minutes. Spend time on the hard problems: exactly-once in distributed systems, handling thundering herds, or coordinator failure modes.
- Experience-Backed Decisions: Draw from real-world: "At my previous company, we used ___ and hit X problem. Here's how we'd avoid that."
- Full Proactivity: You drive the conversation. "Before we go further, let me address how we guarantee exactly-once. Here's what could go wrong and how we'd handle it..."
- The Bar: Address all major challenges unprompted. Discuss factors like why idempotency keys are critical even with partitioning.
Practice with AI mock interviews and nail your real one. Good luck! ⏰