
Design Yelp
Problem Context
🍽️ Yelp is a local business discovery platform where users find restaurants, shops, and services based on location, ratings, and reviews.
Functional Requirements
Yelp does a lot: reservations, food delivery, check-ins, photos. But the main product is discovering local businesses and reading reviews. We will focus on that for our article.
Core Functional Requirements
- FR1: Users should be able to search for businesses by location and keywords.
- FR2: Users should be able to view business details, including aggregated ratings and reviews.
- FR3: Users should be able to write reviews and rate businesses.
Out of Scope:
- User authentication and profiles.
- Reservations and waitlist management (Yelp Reserve).
- Food ordering and delivery (Yelp Eat24).
- Business owner tools and advertising.
- Check-ins and social features.
Non-Functional Requirements
Core Non-Functional Requirements
- NFR1: Search results should return in < 200ms.
- NFR2: System should be highly available (99.99%+).
- NFR3: System should handle 50K+ searches per second during peak hours.
- NFR4: New reviews should be reflected in ratings within 1 minute.
Here's what we have so far:

Let's build Yelp.
The Set Up
The Core Challenge
When someone searches "sushi near downtown Seattle," we need to:
- Find all businesses within a geographic boundary (location filter)
- Filter to those matching "sushi" (text search)
- Rank by some combination of rating, distance, and relevance
- Return results in under 200ms
With 200M+ businesses worldwide, we can't scan everything. We need indexes that understand both geography and text.
Core Entities
These entities form the foundation of our data model. The relationship between businesses and reviews drives many of our design decisions.
Business
{
businessId: "biz_abc123",
name: "Sakura Sushi",
categories: ["Japanese", "Sushi Bars"],
location: {
address: "123 Pike St, Seattle, WA",
lat: 47.6097,
lng: -122.3331
},
avgRating: 4.3,
reviewCount: 847,
priceRange: "$$"
}
Review
{
reviewId: "rev_xyz789",
businessId: "biz_abc123",
userId: "user_456",
rating: 5,
text: "Best salmon sashimi in Seattle! Fresh fish...",
createdAt: "2026-01-09T14:30:00Z",
usefulCount: 23
}
Search Query
{
query: "sushi",
location: {lat: 47.6062, lng: -122.3321},
radiusMeters: 5000,
sortBy: "best_match", // best_match | rating | distance
limit: 20
}
API Interface
We can split our APIs into Search (FR1), Business Details (FR2), and Reviews (FR3).
Search API: FR1
GET /api/v1/search?term=sushi&lat=47.6062&lng=-122.3321&radius=5000&limit=20&cursor={cursor}
Response:
{
"businesses": [
{ "businessId", "name", "rating", "reviewCount", "distance", ... }
],
"nextCursor": "cursor_page2"
}
The search service parses coordinates, queries the geospatial index, filters by text match, ranks by relevance, and returns paginated results.
Business Details API: FR2
GET /api/v1/businesses/{businessId}
Response:
{
"businessId": "biz_abc123",
"name": "Sakura Sushi",
"rating": 4.3,
"reviewCount": 847,
"ratingBreakdown": { "5": 412, "4": 289, ... },
"location": { "address", "city", "lat", "lng" },
...
}
GET /api/v1/businesses/{businessId}/reviews?sortBy=recent&limit=20&cursor={cursor}
Response:
{
"reviews": [
{ "reviewId", "userId", "rating", "text", "createdAt", ... }
],
"nextCursor": "cursor_next"
}
Review API: FR3
POST /api/v1/businesses/{businessId}/reviews
Body: { userId, rating, text }
Response: { reviewId, status, createdAt }
The rating aggregation step is trickier than it looks. Recomputing an average across 10,000 reviews on every new review is expensive. We'll address this in the deep dives.
High-Level Design
We'll start with the simplest working system and fix problems as they arrive.
In an interview, acknowledge you're starting simple. You need to get a working system before optimizing.
1) The Simplest Search: FR1 (Basic Search)
When someone searches "sushi near Seattle," just query the database:
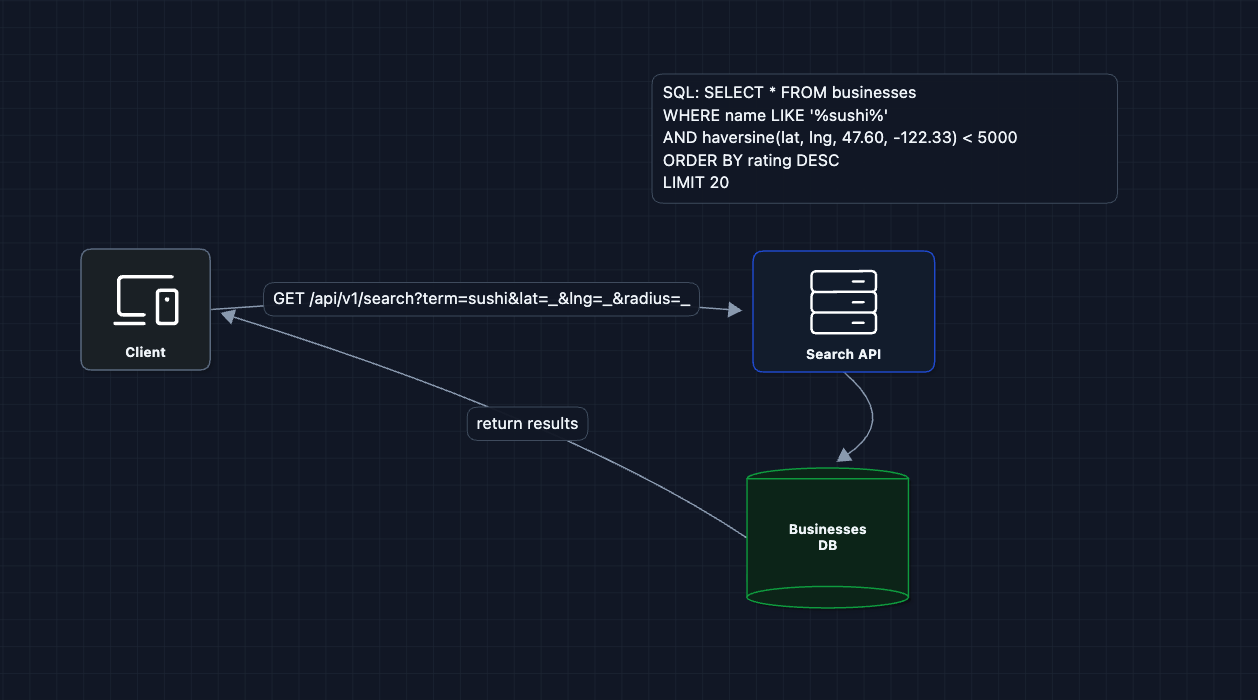
Why does this break?
- Full table scan: Every search scans 200M rows
LIKE '%sushi%': Can't use indexes (must check every row)- Distance calculation: Computing haversine for 200M rows is incredibly slow
This might take 30 seconds per query. We need specialized indexes.
2) Add Geospatial Index: FR1 (Location Search)
The key insight: we can divide the world into a grid and index businesses by grid cell. When searching, we only look at cells within the search radius.
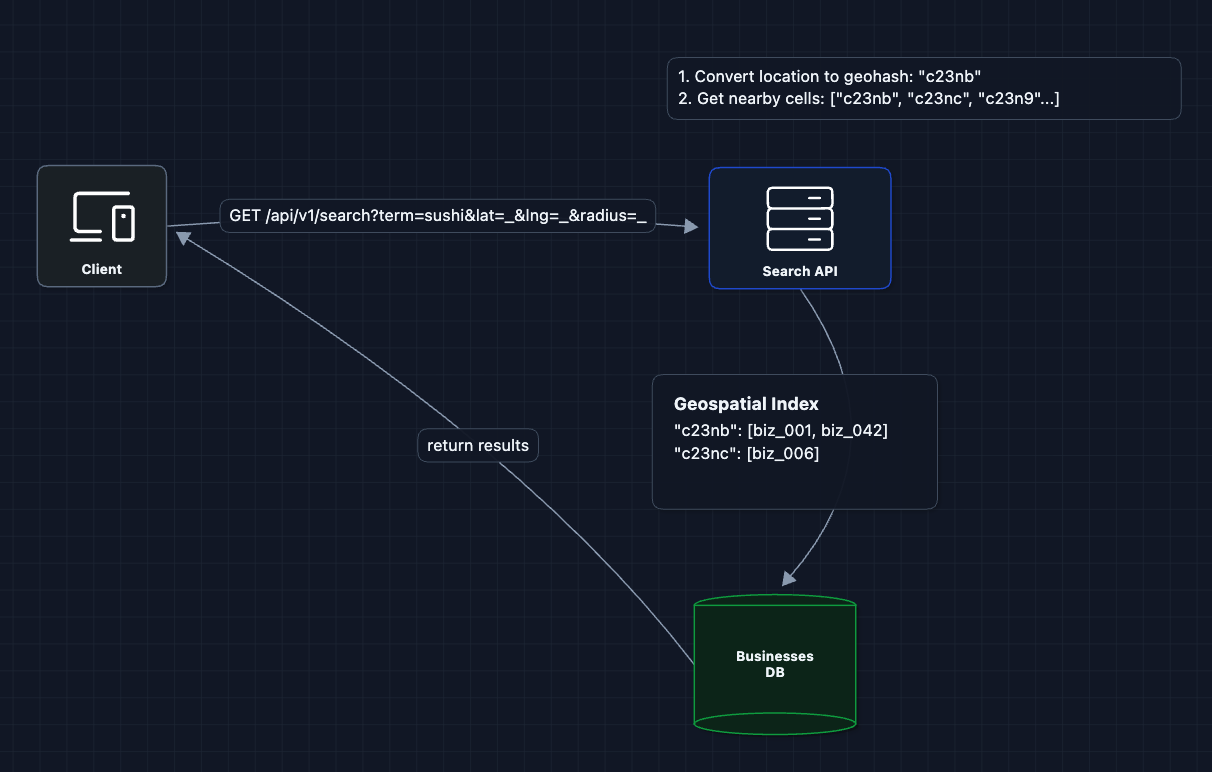
What's a geohash?
A geohash encodes latitude/longitude into a short string. Nearby locations share a common prefix:
c23nb62w= exact locationc23nb= city block (~150m * 150m)c23n= neighborhood (~1km * 1km)c23= city area (~5km * 5km)
By indexing businesses by geohash prefix, we can quickly find all businesses in a geographic area.
What breaks?
- We can find businesses in an area, but we still need text search for "sushi"
- Two separate indexes (geo + text) means we're doing work twice
3) Add Text Search: FR1 (Keyword Matching)
Now we need to filter by keywords. We add a text search layer:
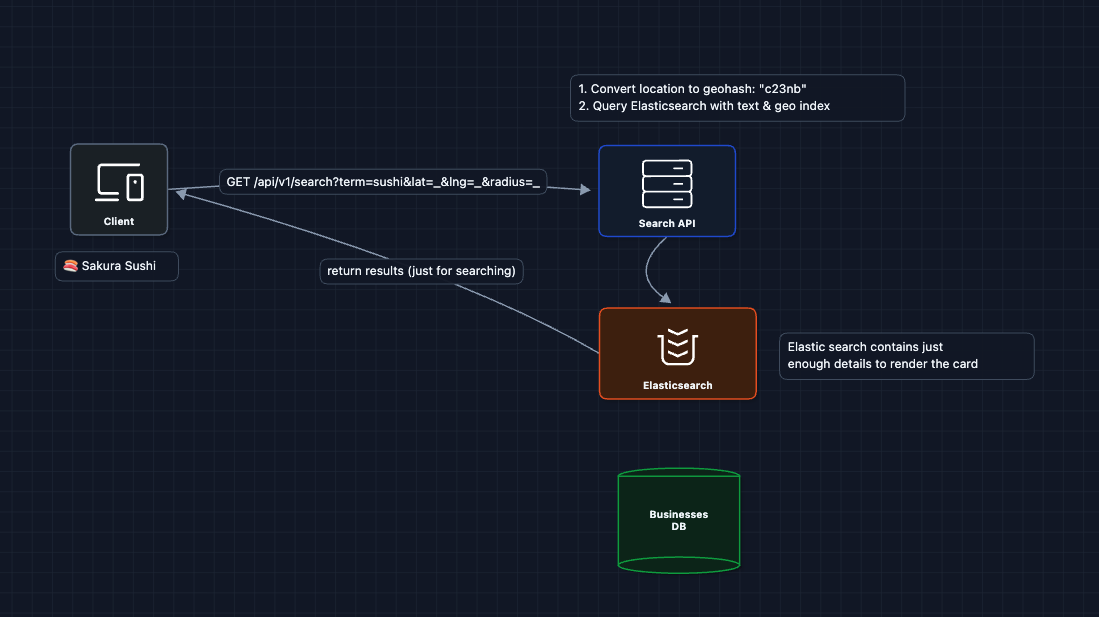
Elasticsearch handles both geospatial queries (geo_distance) and text search (match) in a single index. This is our search layer.
What breaks?
- We have search, but no data for business details or reviews
- Search returns IDs, but we need full business data
We need to separate our data stores by use case.
4) Separate Read Paths: FR1 + FR2 (Search vs. Details)
Search and details have different access patterns:
- Search: Filter millions of records, return 20 results (needs specialized indexes)
- Details: Fetch one business by ID (needs fast key-value lookup)
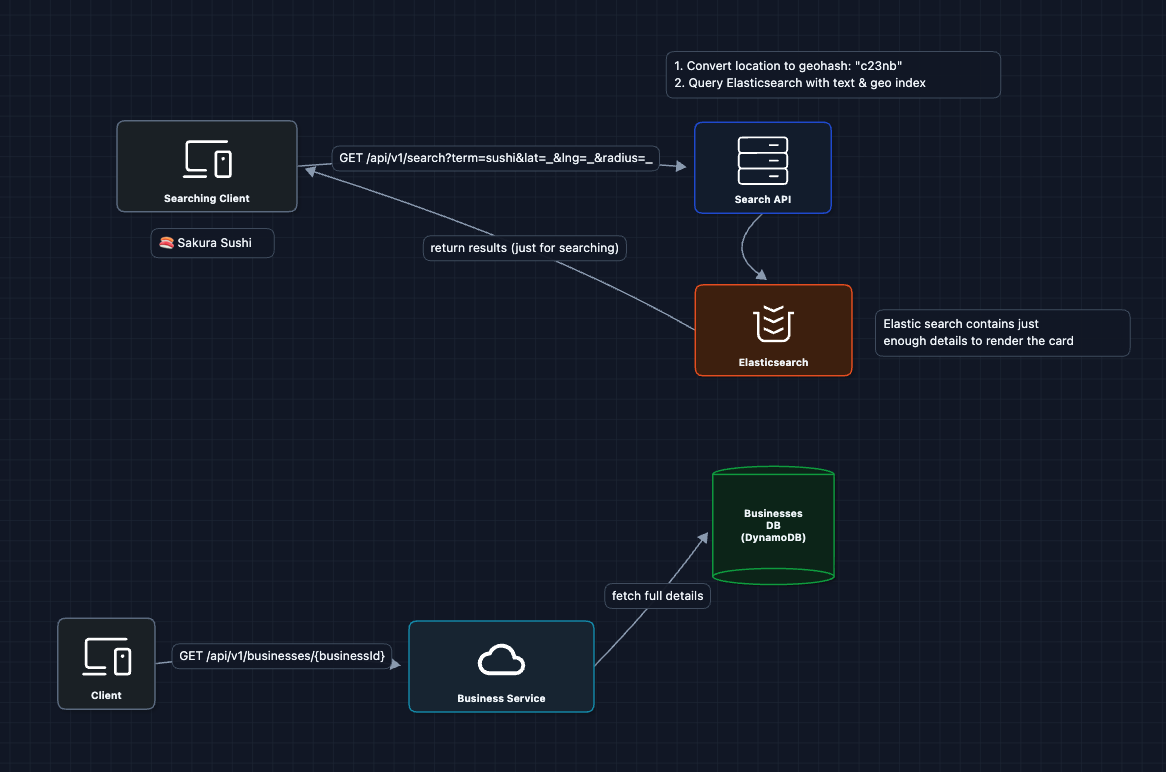
What we added:
- Elasticsearch: Handles geographic and text search efficiently
- DynamoDB: Fast key-value lookups for business details
- Hydration: Search returns IDs, then we fetch full details
What breaks?
- Where do reviews come from?
- How do new businesses and reviews get into the search index?
5) Add Review Storage: FR2 + FR3 (Reviews)
Reviews are a high-volume write path. Users read reviews on business pages and write new ones. Let's add the review layer:
DynamoDB design for reviews:
- Partition Key:
businessId(all reviews for one business) - Sort Key:
createdAt(sorted by date for pagination)
This lets us efficiently query (Get reviews for business X, sorted by date, page 2)
What breaks?
- Updates to business rating and search index are synchronous
- If Elasticsearch is slow, review submission takes a long time
- How does the rating updater know when a new review is made?
We need asynchronous processing.
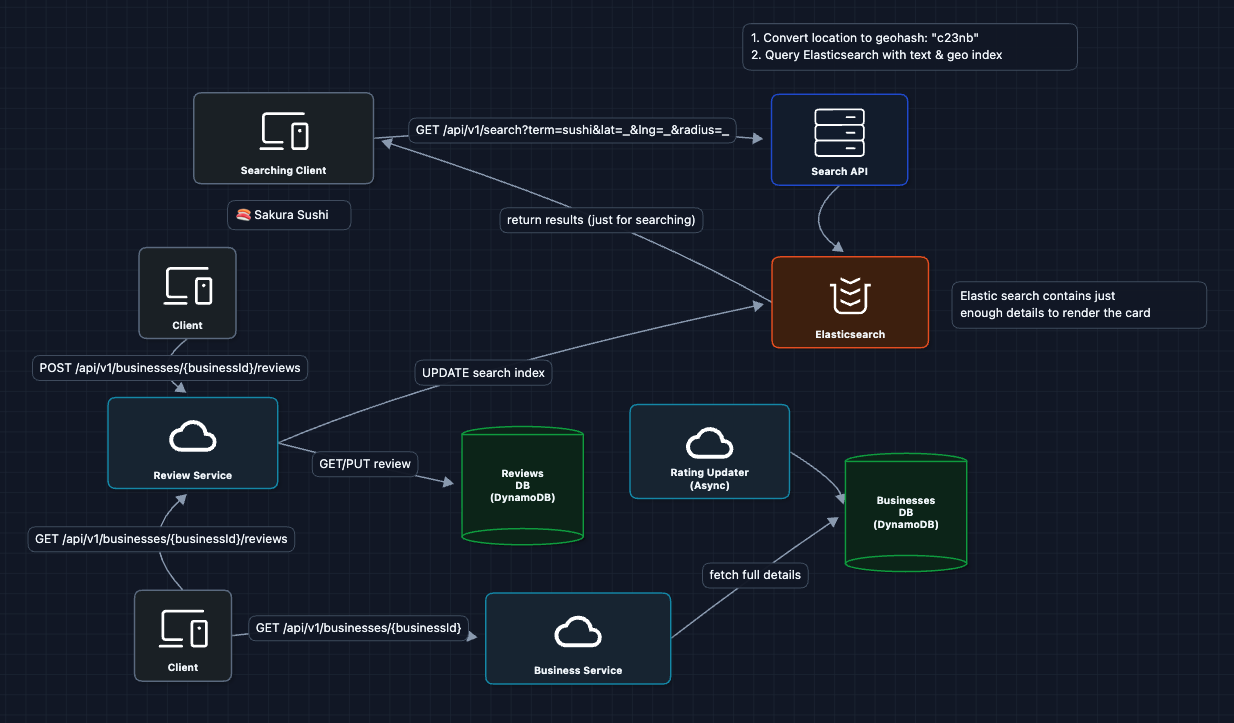
6) Add Async Processing: FR3 + NFR4 (Write Path)
Decouple the write path so review submission is fast:
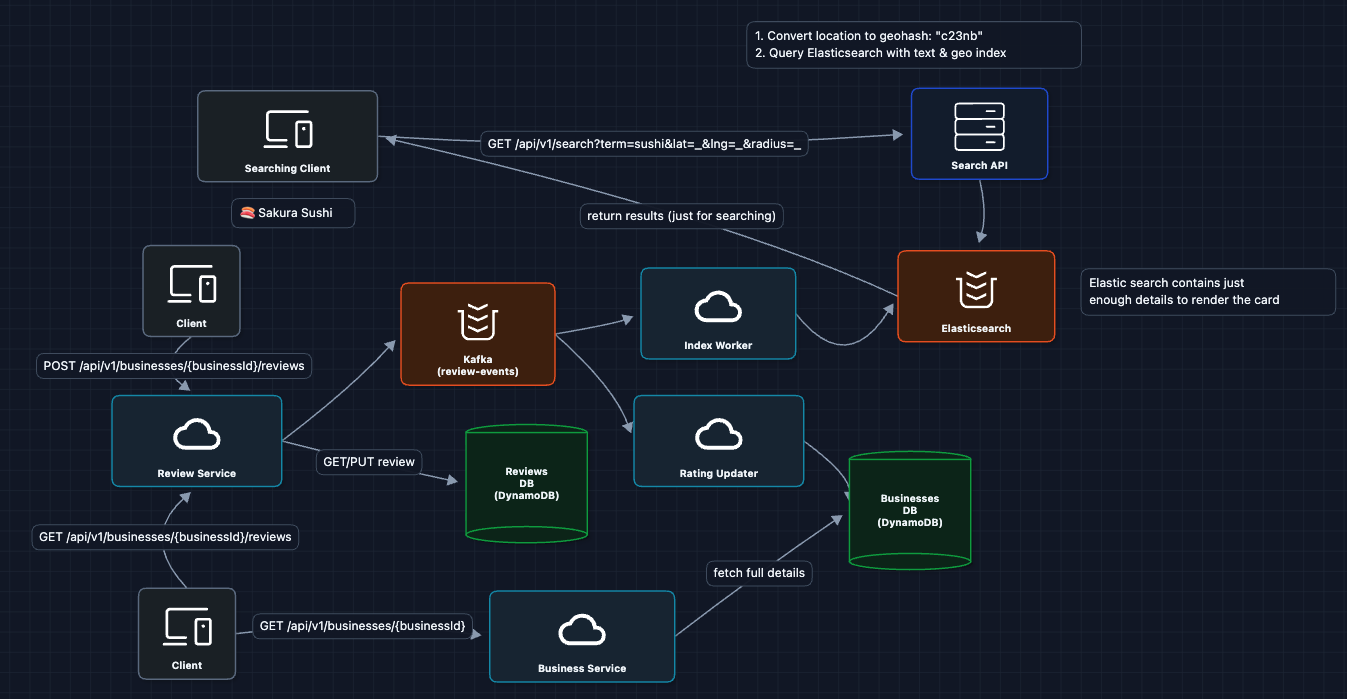
The flow now:
- User submits review, we store it in the Reviews DB
- Event published to Kafka, we return immediately
- Rating Worker recalculates business average (async)
- Index Worker updates Elasticsearch (async)
New reviews are reflected in search results swiftly.
Complete System
This is our baseline architecture!
We satisfy all functional requirements:
- FR1 ✅ Search businesses by location and keywords (Elasticsearch with geo and text)
- FR2 ✅ View business details and reviews (DynamoDB lookups)
- FR3 ✅ Write reviews (async rating updates via Kafka)
Now we can address our non-functional requirements in the deep dives:
- NFR1 (Latency): How does geospatial indexing actually work?
- NFR1 (Latency): How do we paginate results efficiently?
- NFR3 (Scale): How do we handle 50K searches/sec?
- NFR2 (Availability): What happens when things fail?
Potential Deep Dives
1) How does geospatial search actually work?: NFR1 (Latency)
In Diagram 2, we mentioned geohashing. Let's go deeper.
The problem: Given coordinates (47.6062, -122.3321) and radius 5km, find all businesses in that circle. With 200M businesses, we can't check each one.
Geohashing explained:
Geohashing divides the world into a grid. Each grid cell gets a string identifier. Importantly, nearby cells share prefixes.
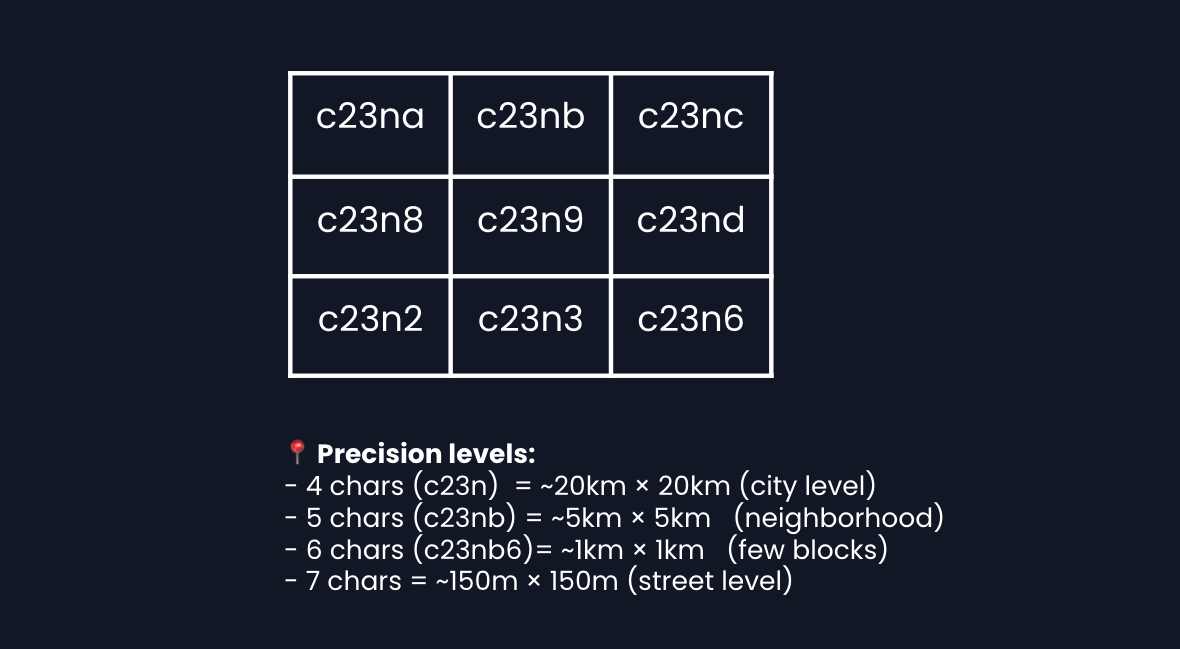
Index structure:

Edge case: partial cells
Some cells are fully inside your search radius (include all businesses). Some are fully outside (skip entirely). But cells at the edge are only partially inside that radius, so you must fetch all businesses from that cell and check each one's exact distance.
Elasticsearch handles this automatically with geo_distance queries. Under the hood, it uses a similar grid-based approach.
2) How do we rank search results?: NFR1 (Latency + Relevance)
Returning results in the order they appear in the geo index isn't useful. Users expect the best results first.
For a typical "sushi near me" query (5km radius), we might get 100-500 matching businesses in a dense city. Ranking a few hundred candidates is straightforward. Elasticsearch scores them based on multiple factors:
Ranking factors:
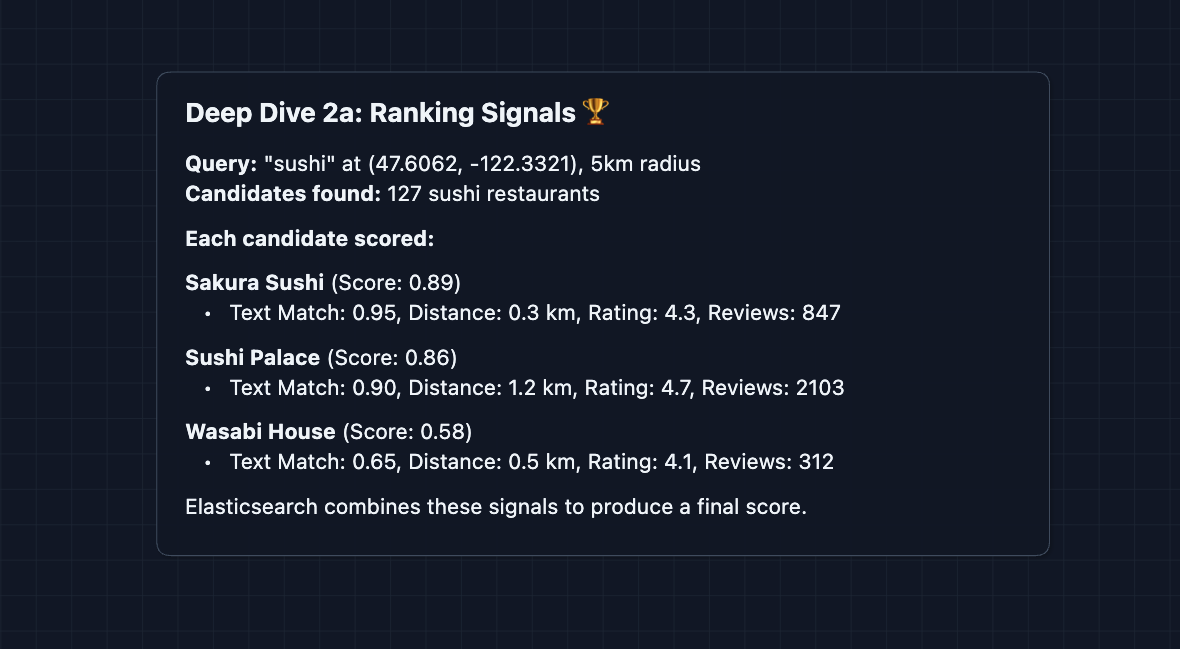
Two-phase ranking (for broader searches):
For a 5km radius search, we rank all 100-500 candidates directly. But for city-wide searches or vague queries like "food" that match thousands of businesses, we use two phases:
- Phase 1 (Elasticsearch): Fast filter 8,000 candidates down to 200 using simple scoring.
- Phase 2 (Application): Rich ranking of 200 candidates down to 20 results (add personalization).
Most queries don't need this, but two-phase ranking handles edge cases of broader searches.
3) How do we paginate search results?: NFR1 (Latency)
Users scroll through results. We can't return all 500 sushi restaurants at once. There are two approaches:
Offset pagination:
GET /api/v1/search?term=sushi&lat=47.60&lng=-122.33&offset=20&limit=20
"Give me results 21-40"
Simple, but breaks at scale. To get page 50, the database must skip 1000 rows then return 20. The deeper you go, the slower it gets.
Cursor pagination:
GET /api/v1/search?term=sushi&lat=47.60&lng=-122.33&cursor=biz_xyz&limit=20
"Give me 20 results after biz_xyz"
The cursor encodes where we left off (the last result's ID). Elasticsearch jumps directly to that position.

4) How do we handle 50K searches per second?: NFR3 (Scale)
Our search path goes: User to Search Service to Elasticsearch to Business DB to Response.
At 50K requests/sec, we need to scale every layer.
Layer 1: Caching popular queries
We have many searches in for popular areas. "pizza in Manhattan" is searched thousands of times per hour, so we can cache these!

Cache key normalization:
We need to normalize coordinates, or cache misses pile up:
40.7128, -74.0060normalizes to40.71, -74.01- This way, nearby searches share cache entries
Layer 2: Elasticsearch sharding
Elasticsearch distributes data across multiple nodes. Each node handles a subset of businesses:
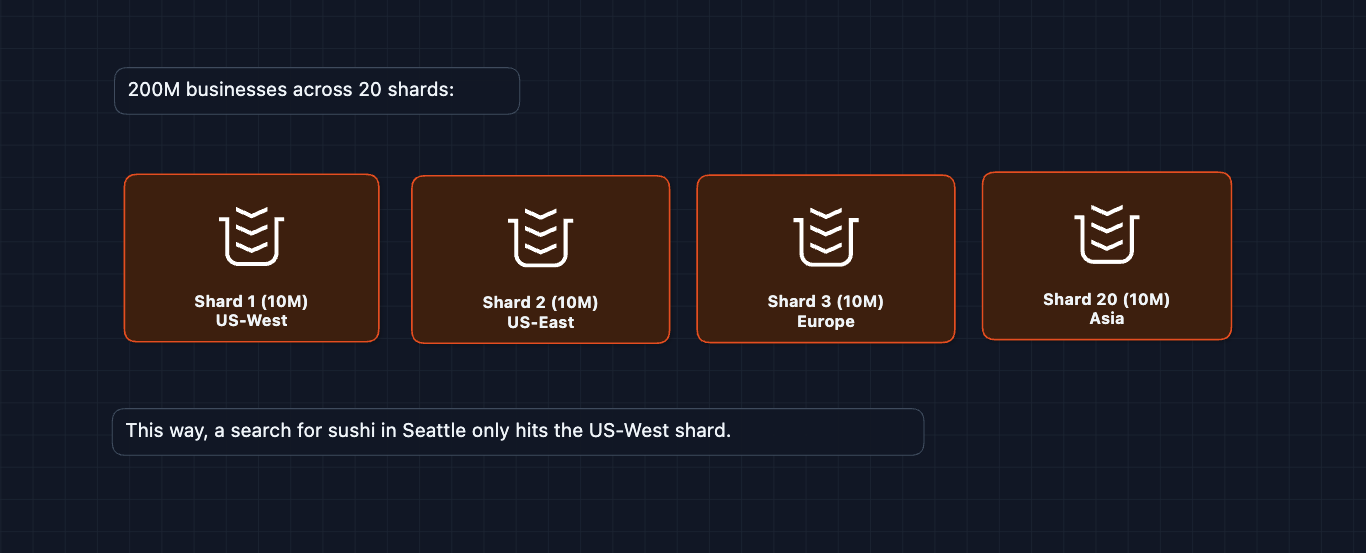
5) What happens when things fail?: NFR2 (Availability)
At 99.99% availability, we can only have 52 minutes of downtime per year. We need redundancy at every layer.
Elasticsearch failover:

DynamoDB availability:
DynamoDB is fully managed with built-in replication across availability zones. If one AZ fails, reads automatically route to another.
Graceful degradation:
If Elasticsearch is slow/down, we can:
- Return cached results (even if slightly stale)
- Show popular nearby from a pre-computed list
- Reduce result count (return 10 instead of 20)
6) How do we efficiently update ratings?: NFR4 (Freshness)
In the HLD, the Index Worker for rankings recalculates the business average. But recomputing AVG(rating) across 10,000 reviews on every new review is O(n) and expensive.
The Solution: Running Totals
Store two more values per business in DynamoDB:
totalRatingSum: Running sum of all ratingsreviewCount: Number of reviews
On new review (rating = 5):
UPDATE businesses
SET totalRatingSum = totalRatingSum + 5,
reviewCount = reviewCount + 1,
avgRating = (totalRatingSum + 5) / (reviewCount + 1)
WHERE businessId = ?
Result:
- O(1) update instead of O(n) aggregation
- No need to read all reviews
- The index worker just does a simple increment and division
What to Expect?
That covered a lot. Here's what matters at each level.
Mid-level
- Breadth over Depth (80/20): Cover the end-to-end flow from search query to results. Know that geospatial indexing is required and know the technical details behind it.
- Expect Basic Probing: "Why can't we just use SQL for this?" "How do ratings get updated?"
- Assisted Driving: You design the search path first, and the interviewer may guide you through the write path.
- The Bar: Complete the HLD with complete understanding. Explain why we need specialized indexes (geo + text). Know that async processing exists for writes, and walk through deep dives, even if they aren't super in depth.
Senior
- Balanced Breadth & Depth (60/40): You should comfortably explain geohashing, ranking factors, and rating aggregation. Pick 2-3 deep dives to discuss.
- Proactive Problem-Solving: You identify the rating aggregation problem before asked. You mention caching for popular queries without prompting.
- Articulate Trade-offs: "We could use a QuadTree instead of geohash, but geohash strings work with standard indexes while QuadTrees need custom code."
- The Bar: Complete the HLD, and proactively discuss at least 2 deep dives.
Staff
- Depth over Breadth (40/60): Breeze through the HLD in 15 minutes (your interviewer assumes you know search basics). Spend time on the hard problems: ranking at scale, handling write spikes, and consistency.
- Experience-Backed Decisions: "In my experience with Elasticsearch geo queries, we found that 6-character geohashes work best for 5km searches, but need refinement for exact boundaries."
- Full Proactivity: You drive the conversation. You bring up problems the interviewer didn't ask: "What about fake reviews? We need rate limiting and fraud detection on the write path."
- The Bar: Address ALL deep dives without prompting. Discuss operational concerns (monitoring search latency p99, when caching would be unnecessary, etc).
Do a mock interview of this question with AI & pass your real interview. Good luck! 🍽️