
Design Netflix
Problem Context
🎬 Netflix is a global video streaming platform that delivers on-demand movies and TV shows to hundreds of millions of users worldwide. As of today, it streams content to 260M+ subscribers.
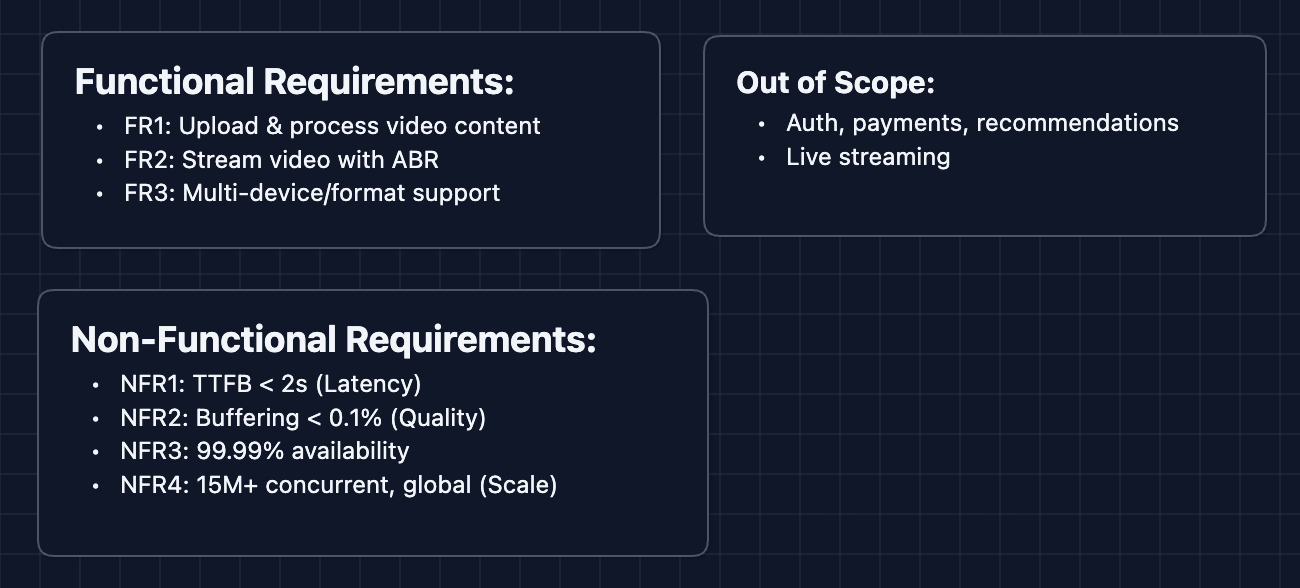
Functional Requirements
Requirements clarifications are essential for Netflix because the scope is so large. We need to establish clear boundaries with our interviewer about what pieces of the system we're designing.
Core Functional Requirements
- FR1: Content team should be able to upload video files and have them processed for streaming.
- FR2: Users should be able to stream video content with adaptive bitrate support.
- FR3: The system should support multiple device types and video formats.
Out of Scope:
- User authentication and subscription management.
- Recommendation algorithm (this is its own massive system).
- Social features (profiles, watch parties).
- Payment processing.
- Live streaming.
In the design, you need to focus on only a few main functional requirements. However, acknowledging other aspects demonstrates your product architecting skill to the interviewer.
Non-Functional Requirements
Core Non-Functional Requirements
- NFR1: Time to first frame should be < 2 seconds.
- NFR2: Buffering ratio should be < 0.1%.
- NFR3: System should be highly available (99.99%+).
- NFR4: System should scale to handle 15M+ concurrent streams globally.
Here's what we have so far:
Let's keep going!
The Set Up
Planning the Approach
Based on our requirements, let's sketch out a plan for the interviewer. We'll tackle this in phases:
- Content Ingestion Pipeline: How video gets uploaded, processed, and stored.
- Content Delivery Architecture: How video gets from storage to the user's device.
- Playback Service: How the client requests and receives video.
Remember, in the interview you first need to get a working system. Make it clear to your interviewer that you recognize flaws in your design but are trying to get to a prototype.
Defining the Core Entities
For this problem, we have several entities to work with:
- Video/Title: The movie or TV show (metadata, not the actual video bytes).
- Video File: The actual encoded video content.
- Chunk/Segment: A small piece of video (2-10 seconds) that can be independently requested.
- Manifest: A file describing all available chunks and quality levels for a video.
- Encoding Profile: A specific combination of codec, resolution, and bitrate.
API Interface
Our APIs fall into two categories: Ingestion (Internal) and Playback (External).
Focus on the purpose of each endpoint rather than exact syntax.
Content Ingestion APIs (Internal): FR1
1. Initialize Upload
POST /videos/upload
Returns a presigned URL so the client uploads the large file directly to S3. This saves server processing power.
// Request
{ "title": "Stranger Things S5E1", "filename": "raw_master.mp4" }
// Response
{ "videoId": "vid_abc123", "uploadUrl": "https://s3.aws.com/presigned/..." }
2. Trigger Processing
POST /videos/{videoId}/process
Kicks off the transcoding job (splitting video into multiple qualities).
// Request
{ "resolutions": ["4k", "1080p", "720p"] }
// Response
{ "jobId": "job_xyz789", "status": "queued" }
3. Check Status (Optional)
GET /videos/{videoId}/status
// Response
{ "videoId": "vid_abc123", "status": "processing", "progress": 67 }
Content Playback APIs (External): Supports FR2, FR3
Called by client apps (TV, Phone, Web) to play video.
1. Get Manifest
GET /videos/{videoId}/manifest
The Playback Service checks device headers (X-Device-Type) and returns an adaptive streaming manifest (HLS/DASH) pointing to the nearest CDN.
#EXTM3U
#EXT-X-STREAM-INF:BANDWIDTH=15000000,RESOLUTION=3840x2160
https://edge-sydney.netflix.com/vid_abc123/4k/playlist.m3u8
...
2. Get Video Segment
GET /videos/{videoId}/segments/{quality}/{segmentNumber}.ts
Fetches actual video binary data (~4s chunks). These requests go directly to CDNs, not our API servers.
High-Level Design
Let's start off with our functional requirements:
- FR1: Upload & process video content
- FR2: Stream video with adaptive bitrate
- FR3: Multi-device/format support
For the sake of explanation, we'll start with the most straightforward design and improve it. In an interview, you can start with Diagram 2.
1) The Simplest System: FR2 (Streaming)
Let's start with a simple fetch and response of a video stream.
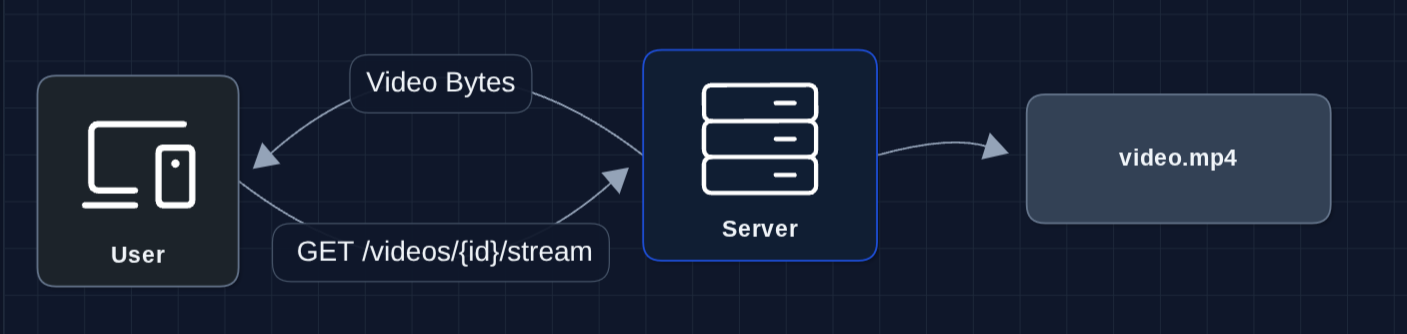
The user requests video, server sends it. In theory, this works for a small scale.
But what breaks?
- The server disk fills up (videos are huge)
- If the server dies, everyone loses access
- We can only store a few videos
We need to separate storage from serving.
2) Separate Storage from Compute: FR2 (Streaming)
Let's move videos to dedicated storage (S3/blob storage):
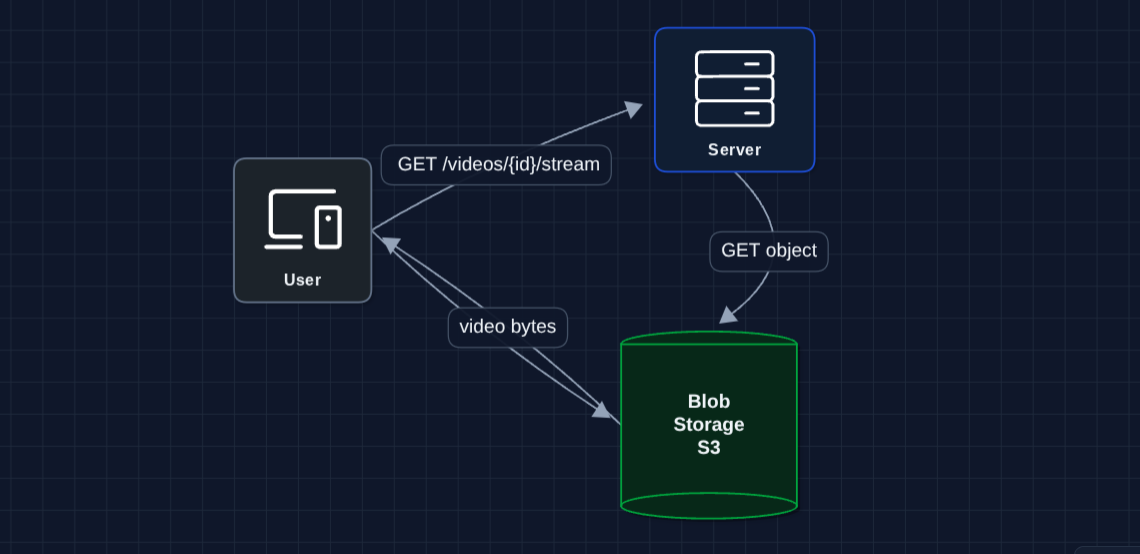
This is better. Object storage specifically designed to store media, such as S3, can store petabytes.
But what breaks?
- Latency: If S3 is in us-east-1, and our user is in Sydney, we get 200ms round trip per request.
- Expensive: S3 egress costs add up at scale.
- Single region: If us-east-1 goes down, nobody gets to watch anything.
We need content closer to users.
3) Add a Cache: FR2 (Streaming)
We're still working on FR2. First, let's put a cache between the server and blob storage.
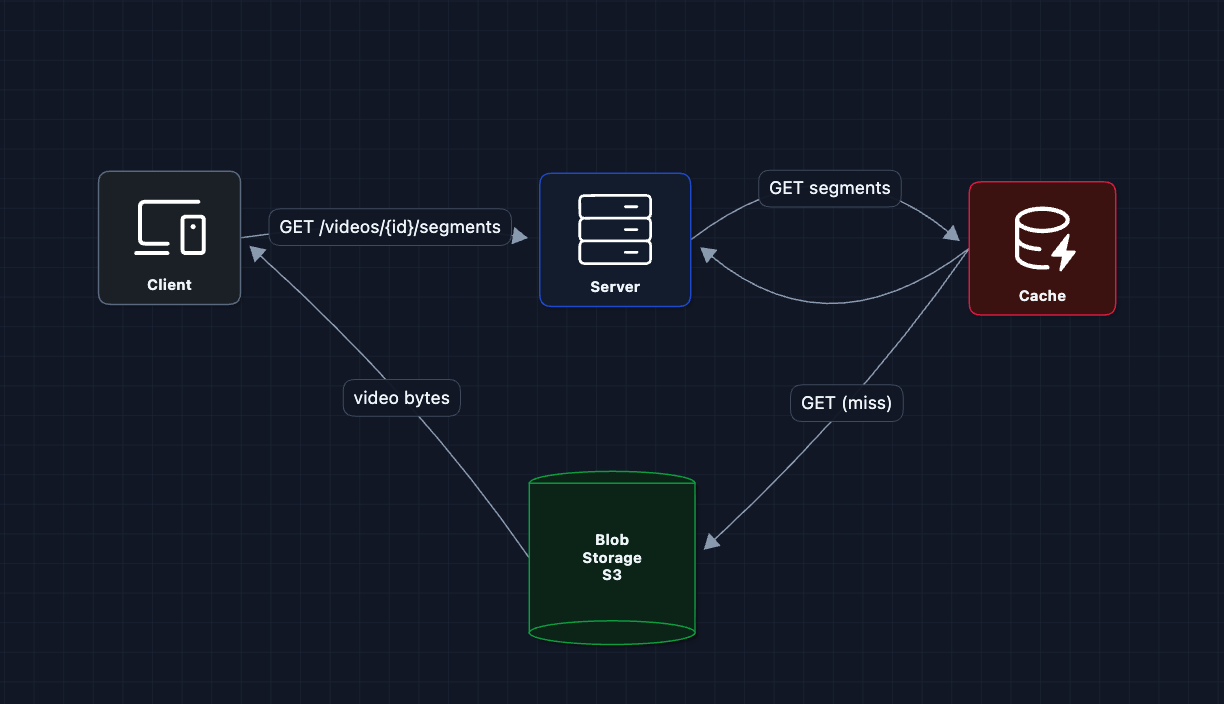
Now, popular content stays cached. Repeat viewers get faster responses.
What breaks?
- A single cache: We still have our original problem. Sydney users are still far from the cache
- One cache means a single point of failure
- One cache means a capacity limit (can't serve 15M concurrent users)
- Cached video bytes flow through the server: This is a common pitfall. The server becomes a bandwidth bottleneck
We need multiple caches in multiple locations.
4) Multiple Caches (CDN): FR2 (Streaming)
We're still working on FR2. We can scale from one cache to many. This is a Content Delivery Network (CDN):
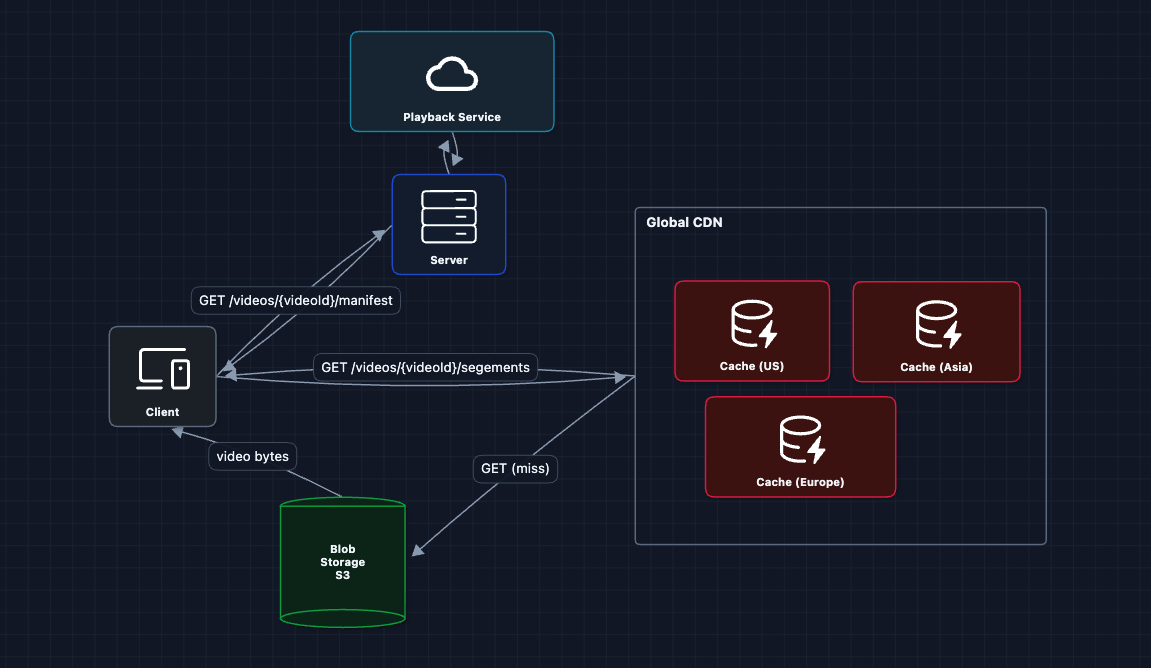
The Sydney user can use the Asia cache. Our client requests a manifest from the server and is able to get segments from the nearest edge cache. Now, it's much faster!
But what breaks?
- Where do videos from S3 come from? We need an ingestion pipeline.
5) Add Content Ingestion: FR1 (Upload & Process)
The content team needs to upload videos, but raw uploads (4K master files) are huge and in formats users can't play. We need to process them.
But how does Playback Service know what videos exist? We need a Metadata DB too.
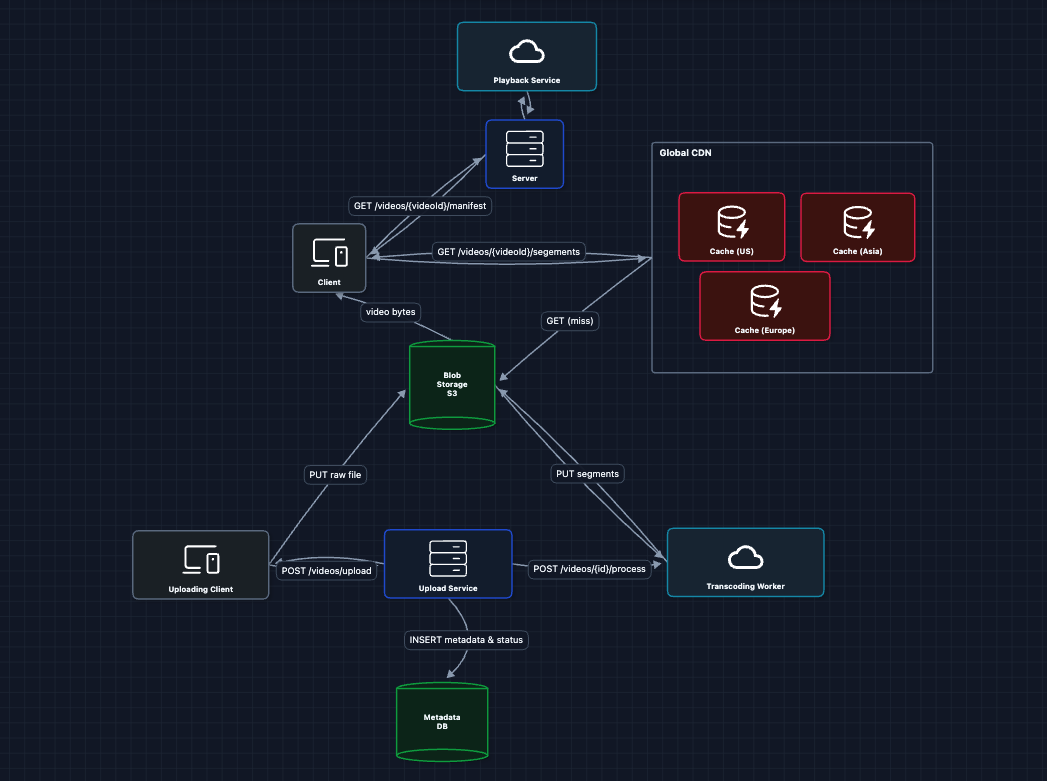
The ingestion flow:
- Content team calls
POST /videos/upload(the upload Service returns a presigned URL) - Upload Service writes to Metadata DB:
{videoId, status: "pending"} - Content team uploads raw file directly to S3 (100GB never touches our servers!)
- Content team calls
POST /videos/{id}/process, triggering transcoding - Worker reads raw file from S3, encodes, writes segments back
- Worker updates Metadata DB:
{status: "ready", qualities: ["4K", "1080p", "720p"]} - Now Playback Service can read from Metadata DB and serve it!
Metadata DB stores:
- Video ID, title, duration
- Status:
processing|ready|failed - Available qualities:
["4K_h265", "1080p_h265", "720p_h264"] - Encoding progress per quality
- Content metadata (genre, rating, audio tracks)
What breaks?
- Transcoding a 2-hour 4K movie into 20 formats takes 40+ hours sequentially. We need to parallelize.
6) Parallelize Transcoding: FR1 (Upload & Process) ✅
We're still on FR1. Instead of one worker processing the whole video, we can split the into chunks and process in parallel:
The splitting into chunks will help us when we deep dive into our streaming mechanism.
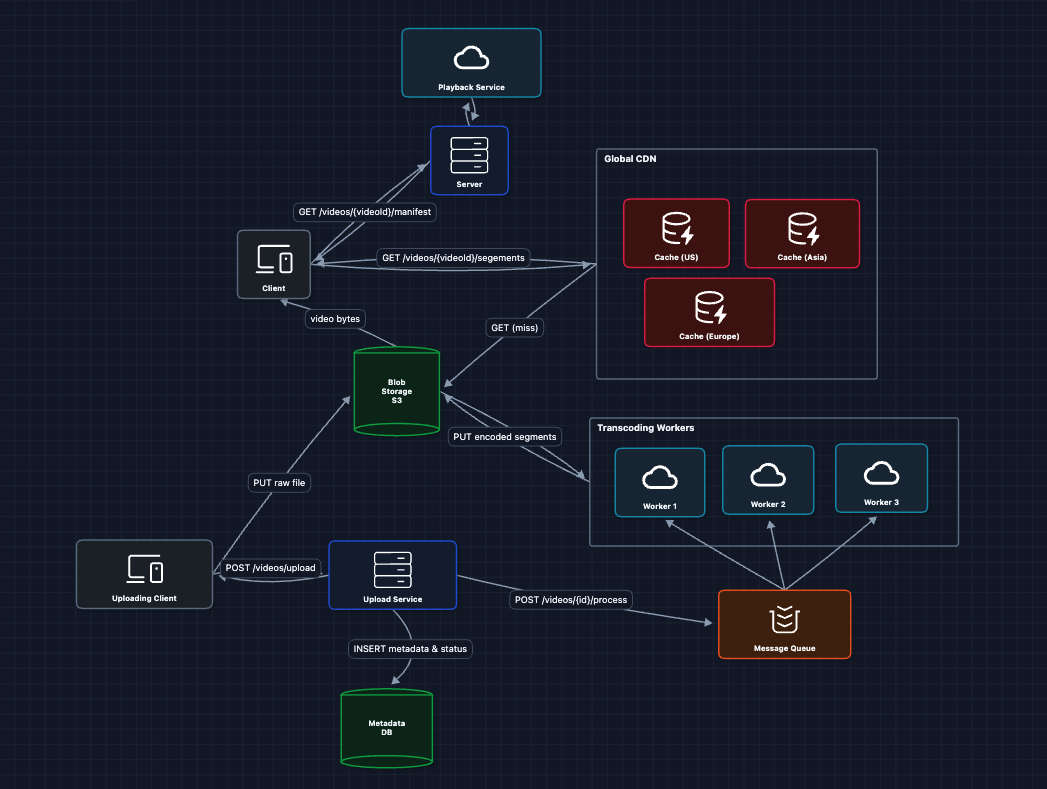
Note: Use SQS or RabbitMQ since jobs should be deleted after processing and not retained for replay.
Now we have a complete working system that satisfies all functional requirements:
- FR1 ✅ Upload & process (Diagrams 5-6)
- FR2 ✅ Stream video (Diagrams 1-4)
- FR3 ✅ Multi-device (Workers output multiple formats)
Now we can address our non-functional requirements (and more) in the deep dives:
- NFR1 (Latency < 2s): How do we route to optimal caches?
- NFR4 (Scale): How do we warm caches for big launches?
- NFR3 (Availability): What happens when things fail?
- NFR2 (Quality): How does video quality adapt to network speed?
Potential Deep Dives
1) How does Playback Service pick the right cache?: NFR1 (Latency < 2s)
In Diagram 5, we said Playback Service tells the user to use cache-asia.netflix.com. But how does it decide?
It's simple. Just use coordinates to find the nearest CDN.
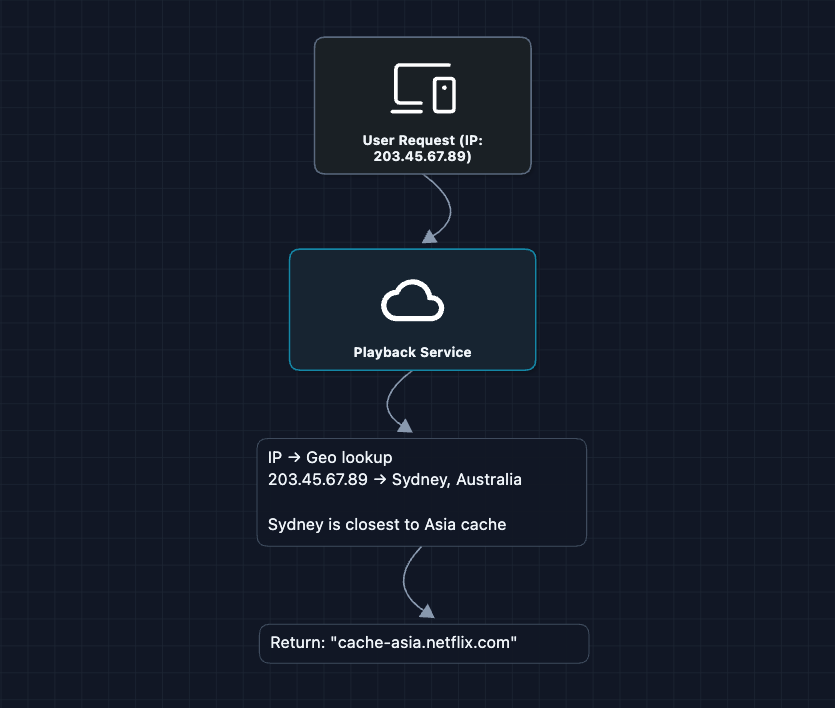
This is great! ... when we are fully functional.
But what breaks?
- The Asia cache might be overloaded (everyone's watching Squid Game)
- The Asia cache might be down
- The network path from Sydney to the Asia cache might be slow
We can consider more than one factor, using monitoring data

What we added:
- Health monitoring
- Multiple options in response (there is room for failover)
- Ranking based on latency and load
2) How do we warm caches before big launches?: NFR4 (Scale)
In Diagram 4, caches pull from origin on cache miss.
What happens when Stranger Things season 5 drops and millions of people hit play at the same moment?
The problem:
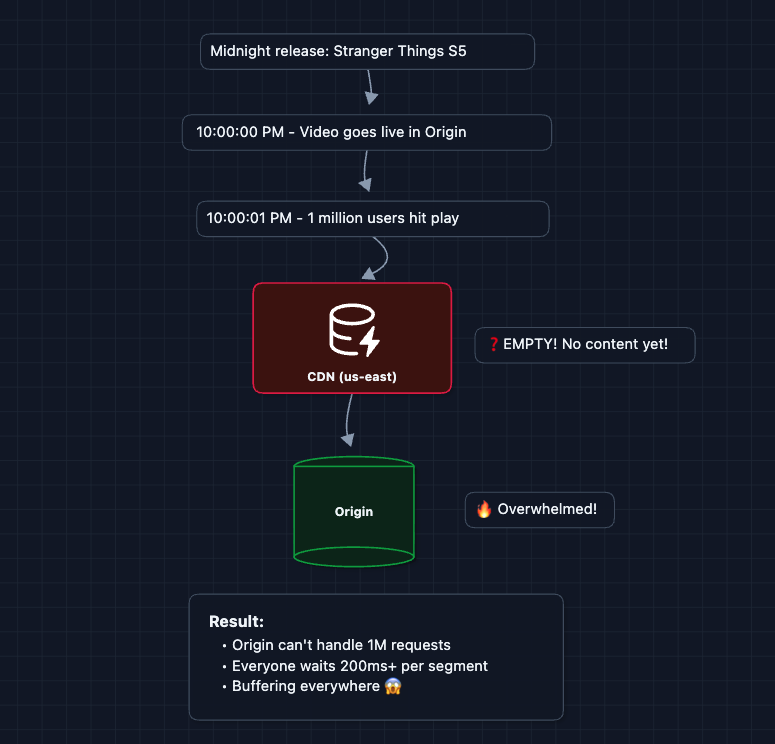
What breaks?
- All users cache-miss at once
- Origin gets hammered
- Poor experience for everyone
The fix: Push content to caches before launch
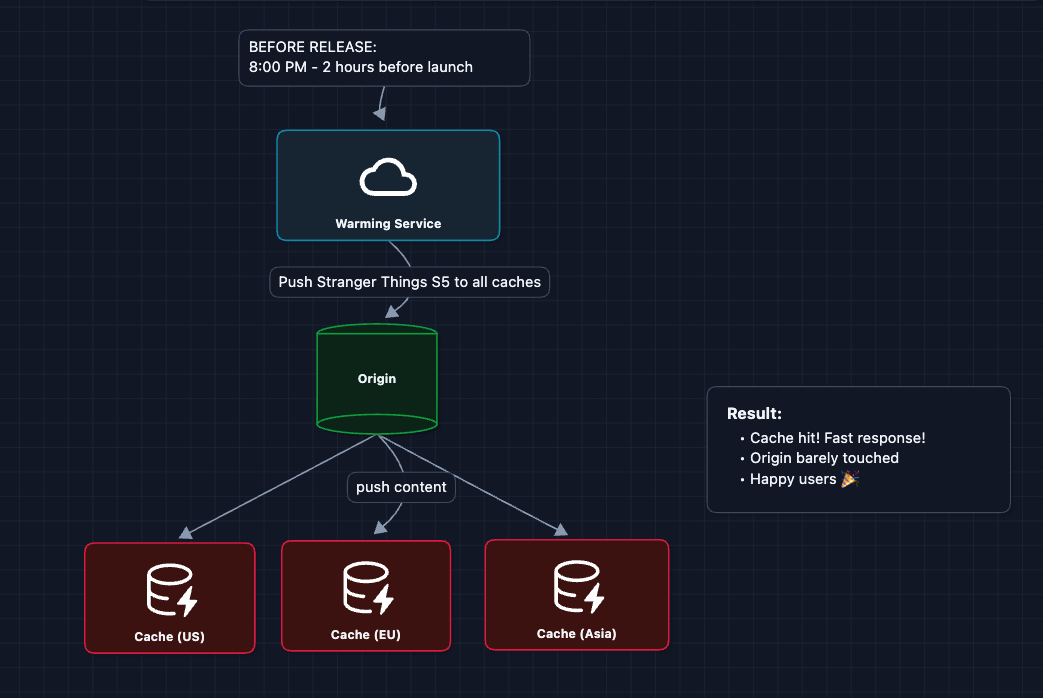
What we added to Diagram 4:
- Warming Service (knows about upcoming releases)
- Scheduled warming (runs before big releases)
Consider the following challenges:
- Which caches need which content? (US loves Stranger Things, Asia loves anime)
- We can't cache everything everywhere (storage limits)
- Push too early, content might get evicted. Push too late, we have a cold cache.
3) What happens when things fail?: NFR3 (99.99% Availability)
The pattern in our system is the same everywhere. We have redundancy and automatic failover. Here's cache failover as an example:

The same principle applies to Origin (S3) failures that are distributed globally.
4) How does video quality adapt to network speed?: NFR2 (< 0.1% Buffering)
If we only had ONE quality (1080p), fast users are happy but slow connections buffer constantly. If we pick low quality for everyone, fast users get blurry video.
The fix: Store multiple qualities and let client choose per-segment
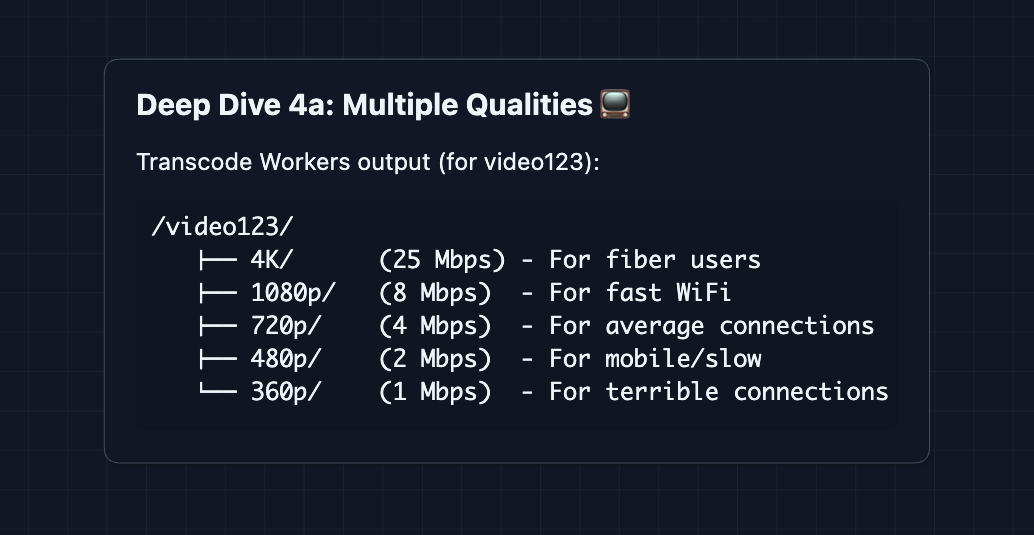

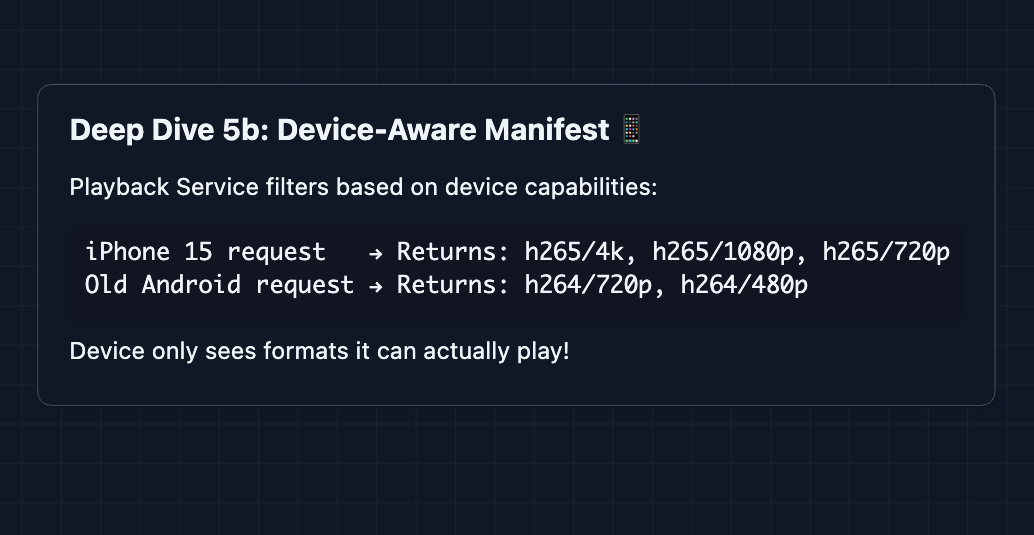
5) How do we support different devices?: FR3 (Multi-device)
The fix: Encode in multiple formats and filter per device

What to Expect?
Wow, we are finally done! Let's break down what you really need to cover in an interview.
Mid-level
- Breadth over Depth (80/20): Focus on connecting the main components to meet the functional requirements.
- Expect Basic Probing: The interviewer won't assume you know everything. Expect questions like "What exactly does a CDN do here?".
- Assisted Driving: You lead the initial design, but the interviewer will likely take the wheel later to guide you through bottlenecks or edge cases you missed.
- The Netflix Bar: You must successfully design the Ingestion Pipeline (Uploads) and Playback Flow (CDN). You understand why caching is needed, even if you don't finish all the deep dives in global scaling.
Senior
- Balanced Breadth & Depth (60/40): You should go deeper into areas you have hands-on experience with. Don't just name drop technologies, but explain how they work and why you chose them.
- Proactive Problem-Solving: You identify bottlenecks before the interviewer points them out. You're thinking about failure modes, latency, and scale as you go into deep dives.
- Articulate Trade-offs: You can thoroughly explain pros/cons of architectural choices ("Cache warming is tricky. Push too early and content gets evicted, push too late and you have a cold cache on launch").
- The Netflix Bar: Complete the full HLD and proactively dive into 2-3 deep dives: cache routing (Deep Dive 1), cache warming (Deep Dive 2), failover patterns (Deep Dive 3), or adaptive bitrate (Deep Dive 4).
Staff
- Depth over Breadth (40/60): The interviewer assumes you know the basics. Breeze through the high-level design quickly (~15 min) so you have time for what's interesting.
- Experience-Backed Decisions: You draw from real-world experience. You know which technologies to use and why. You can quickly draw an HLD and rip it apart piece by piece to identify where things go wrong.
- Full Proactivity: You drive the entire conversation. The interviewer intervenes only to focus, not to steer. You anticipate problems and propose solutions to scaling before being asked.
- The Netflix Bar: Address ALL deep dives without prompting: smart routing, cache warming, failover, adaptive bitrate, and multi-device support. The bread and butter is not just building the base system but explaining the intricacies as you go into scaling it.
Do a mock interview of this question with AI & pass your real interview. Good luck! 🎬