
Design Distributed Queue (Kafka/RabbitMQ)
Problem Context
📨 A message queue lets services talk to each other without waiting. For instance, Kafka processes 7 trillion messages per day at LinkedIn.
Functional Requirements
We need to clarify the scope with our interviewer first, as there are a lot of ways we can approach this problem.
Core Functional Requirements
- FR1: Producers should be able to send messages to the queue.
- FR2: Consumers should be able to receive messages from the queue.
- FR3: Messages should survive server restarts (durability).
Out of Scope:
- Schema validation: Checking if message content matches a predefined structure (Avro/Protobuf) to prevent bad data.
- Stream processing: Performing real-time calculations on the data (Flink/Spark).
- Exactly-once delivery: Ensuring a message is processed exactly one time, never lost or duplicated (complex).
- Multi-tenancy: Hosting multiple unrelated customers (tenants) on the same infrastructure while keeping them isolated.
Non-Functional Requirements
Core Non-Functional Requirements
- NFR1: Send latency < 10ms at p99.
- NFR2: Handle 1M+ messages per second.
- NFR3: 99.99%+ uptime.
- NFR4: Zero message loss after acknowledgment.

Let's continue with the design.
The Set Up
Core Entities
Producer: Service that sends messages.Consumer: Service that receives and processes messages.Topic: A named channel for messages (orders, user-signups).Partition: A shard of a topic. Enables parallel writes.Offset: A message's position in a partition (0, 1, 2, ...).Consumer Group: Consumers sharing the work of reading a topic.
API Interface
We need two simple operations: send and receive.
Real queues (like Kafka) use binary protocols for performance. These HTTP examples are simplified for illustration.
1. Send (Producer)
Producers publish messages to a specific queue.
POST /messages
{ "queue": "orders", "body": "...", "key": "order_789" }
2. Receive (Consumer)
Consumers pull a batch of messages to process.
GET /messages?queue=orders
3. Ack (Consumer Side-channel)
Real queues require an explicit "Ack" to confirm the job is done. This prevents data loss if a consumer crashes.
POST /ack
{ "messageId": "msg_42847" }
High-Level Design
Let's start with our functional requirements:
- FR1: Send messages
- FR2: Receive messages
- FR3: Survive restarts
We'll build the simplest system first, then rebuild as we move along.
1) The Simplest Queue: FR1, FR2
One server holds messages in memory. The producer sends and the consumer receives.
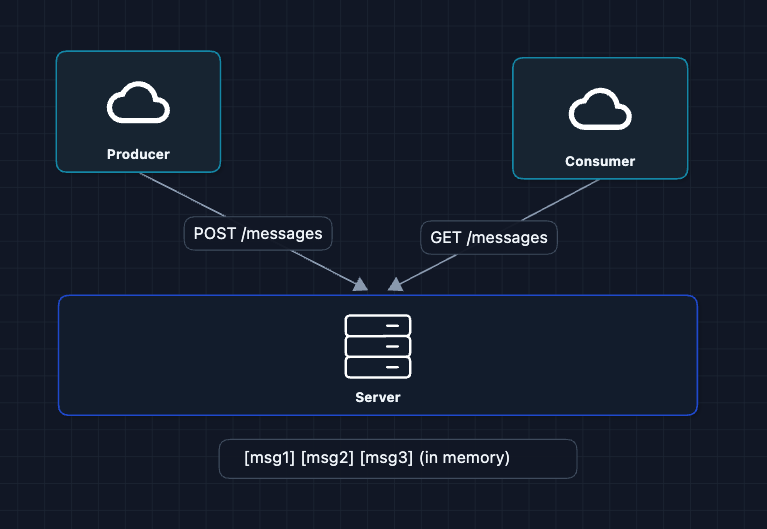
This works! But what happens if the server restarts? All messages are gone.
2) Write to Disk: FR3 ✅
To survive restarts, we write messages to disk before acknowledging the producer.
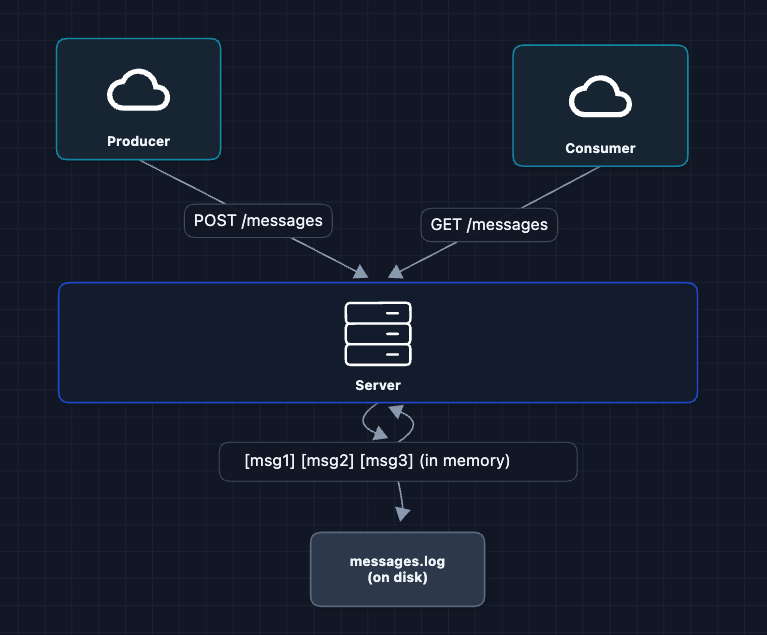
Now messages survive restarts. Our server comes back up, reads the log, and continues.
But what breaks?
- One server means limited throughput.
- If this server dies permanently, messages are lost.
3) Add More Servers (Partitions): NFR2 ✅
One server can't handle 1M messages/second. The solution: add more servers, each handling a portion of the messages. We call each portion a partition.
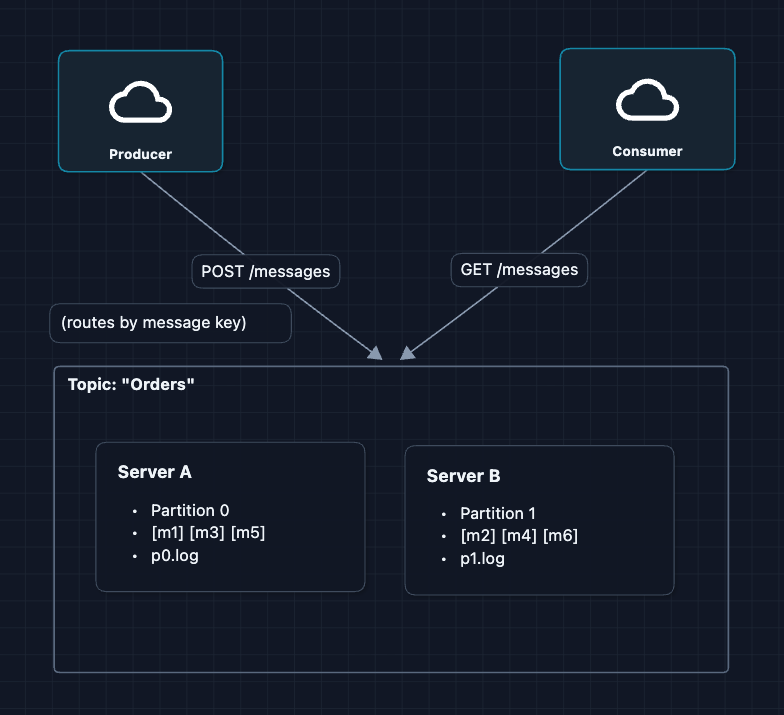
What's a partition? Instead of all messages going to one server, we split them across multiple servers. Each server stores a portion of the messages in its own log file. That portion is called a partition.
Capacity: Realistically, a partition varies but typically holds up to 100 GB of data.
Partition Assignment:
- No Key (Round-Robin): Cycles through partitions to balance load.
- With Key (Hashing): Uses
hash(key) % num_partitions. Ensures all messages for a specific Key go to the same partition to maintain order.
A queue split into partitions is called a topic in Kafka.
What breaks? If Server A dies, Partition 0 is gone forever. We need backup copies.
4) Add Backup Copies (Replication): NFR3, NFR4 ✅
If a server dies, that partition is lost. The solution: keep a backup copy of each partition on another server.
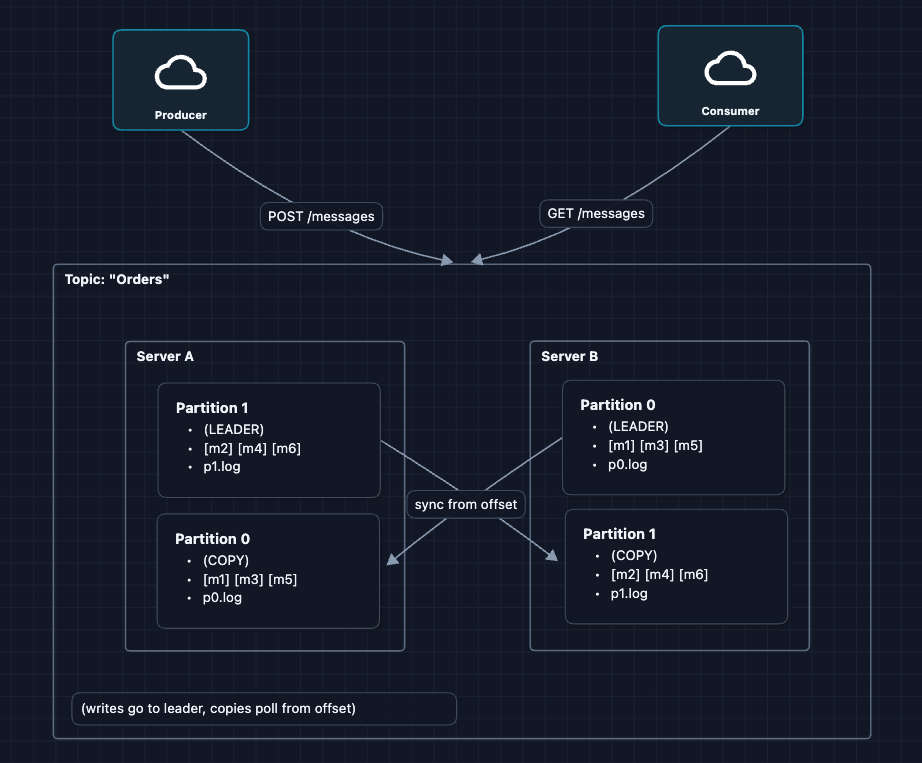
What did we change?
Each server now holds two partitions:
- One as the leader (handles reads/writes)
- One as a copy (backup that syncs from the other server's leader)
Reading the diagram:
| Server | Leader for | Backup copy of |
|---|---|---|
| Server A | Partition 0 | Partition 1 |
| Server B | Partition 1 | Partition 0 |
Why this works:
- If Server A crashes, Server B has a copy of Partition 0 and becomes the new leader
- If Server B crashes, Server A has a copy of Partition 1 and becomes the new leader
- No data is ever lost
5) Scale Consumers (Consumer Groups): FR2 ✅
One consumer can't keep up with a high-throughput topic. The solution is multiple consumers sharing the work.
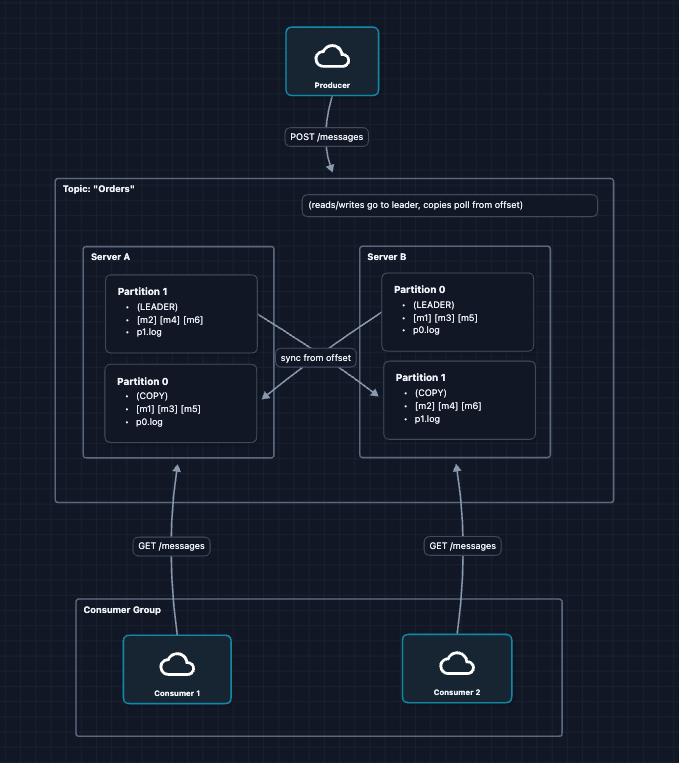
A consumer group is a set of consumers that work together:
- Each partition is assigned to exactly one consumer in the group.
- If Consumer 2 dies, its partition is reassigned to a surviving consumer.
- Multiple groups can read the same topic independently (one for email, one for analytics).
Within a group, each message is processed by exactly one consumer.
6) Complete HLD
Putting it all together with a coordinator:
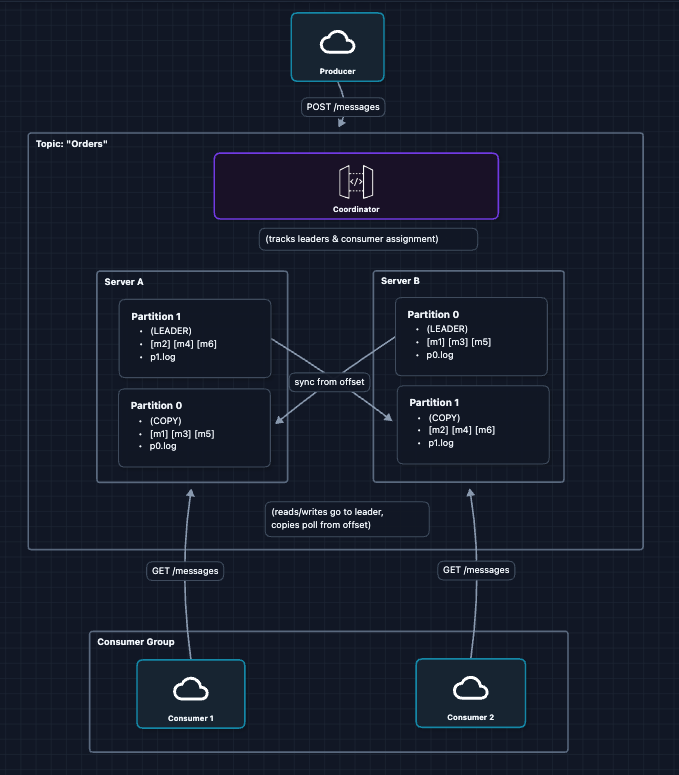
What each component does:
| Component | Role |
|---|---|
| Producers | Send messages to partition leaders |
| Servers | Store partitions on disk, replicate to each other |
| Coordinator | Tracks which server leads each partition, manages consumer groups |
| Consumer Groups | Pull messages, each group gets every message once |
This satisfies all our requirements:
- FR1 ✅ Producers send to partition leaders
- FR2 ✅ Consumer groups pull and process
- FR3 ✅ Messages on disk + replicated
Now let's deep dive into our non-functional requirements and more:
- How do we write to disk so fast?
- What happens when a server dies?
- How do consumers track their progress?
Potential Deep Dives
1) How is disk I/O so fast?: NFR1 (< 10ms latency)
Disk is slow, so how do we hit < 10ms?
We can use append-only writes. We never update or delete. We just append to the end of the file.

Why is sequential so fast?
The storage device knows exactly where to write next (the end), so there's no time wasted seeking. This is true for both hard drives and SSDs.
How consumers read efficiently:
Each consumer tracks its position using an offset (message number). To catch up, it reads sequentially from that offset forward. No indexing or scanning required.
2) What happens when a server dies?: NFR3 (Availability)
In the HLD, we replicated partitions. But what does failover look like?
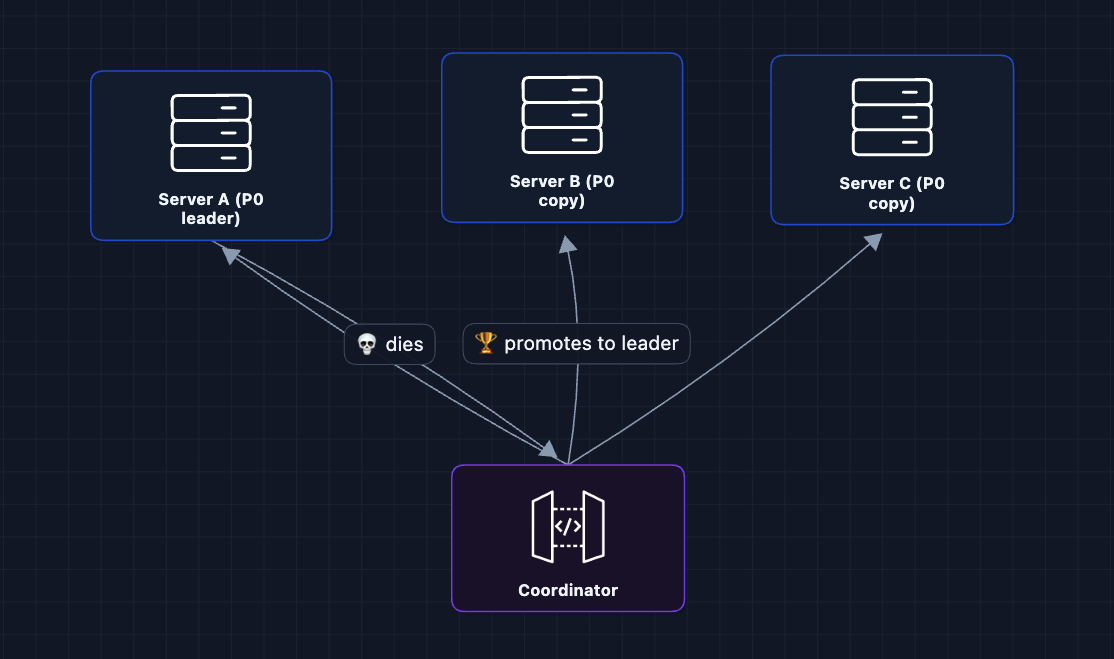
Failover steps:
- Coordinator detects A is unresponsive (missed heartbeats)
- Coordinator picks a copy that's fully caught up
- That copy becomes the new leader
- Producers/consumers are notified, redirect traffic
3) How do consumers track progress?
Unlike traditional queues that delete messages after delivery, our queue keeps messages and tracks where each consumer group is.

Where are offsets stored?
In a special internal topic called __consumer_offsets. The queue stores consumer progress the same way it stores any message.
Delivery semantics:
When should the consumer update its offset?
| Strategy | Behavior | Risk |
|---|---|---|
| Commit before processing | If processing fails, message is skipped | At-most-once (may lose) |
| Commit after processing | If commit fails, message is re-processed | At-least-once (may duplicate) |
Most systems use at-least-once and make processing idempotent (safe to repeat).
4) How do slow copies not block producers?
If one copy is slow with message replication, should the producer wait for it?
The queue tracks which copies are keeping up in a set called the In-Sync Replicas (ISR).

Producer acknowledgment options:
| Setting | Behavior | Trade-off |
|---|---|---|
acks=0 | Don't wait | Fast, but may lose messages |
acks=1 | Wait for leader only | Fast, loses data if leader dies before replication |
acks=all | Wait for all ISR copies | Slowest, but survives any single failure |
When C catches up, it rejoins ISR automatically.
5) Rebalancing: When consumers join or leave
What happens when a consumer joins, leaves, or crashes?

Rebalance process:
- Coordinator detects missed heartbeats
- Triggers rebalance
- Reassigns orphaned partitions to surviving consumers
Rebalancing is disruptive: All consumers in the group briefly pause. Modern systems like Kafka use incremental rebalancing, redistributing in multiple rounds, to minimize this.
Why is the one partition per consumer rule important?
If two consumers read the same partition, they might both process the same message. By assigning each partition to exactly one consumer, we guarantee each message is processed once (within a group).
What to Expect?
That covered a lot! Here's what you should focus on at each level.
Mid-level
- Breadth over Depth (80/20): Focus on getting the basic flow working. Understand that producers send to partitions, consumers pull from partitions, and replication prevents data loss.
- Expect Probing: "Why do we need partitions?" (scale writes) "What if a server dies?" (replicas take over). You should explain these clearly.
- Assisted Driving: You lead the initial design, but the interviewer may guide you toward partitioning and replication.
- The Bar: Complete the HLD through Diagram 5. Explain why partitions enable parallelism and why replication prevents data loss.
Senior
- Balanced Breadth & Depth (60/40): Go deeper on trade-offs like
acks=1vsacks=all. Explain how consumer groups coordinate and rebalance. - Proactive Problem-Solving: Identify issues before asked. Bring up ISR mechanics and offset management.
- Articulate Trade-offs: "We could wait for all replicas to acknowledge, but that adds latency. For most use cases, waiting for 2 of 3 is sufficient."
- The Bar: Complete the HLD and proactively dive into 2-3 deep dives: append-only logs, ISR mechanics, or offset management.
Staff
- Depth over Breadth (40/60): The interviewer assumes you know the basics. Spend ~10 minutes getting to the HLD, then go deep on interesting problems.
- Experience-Backed Decisions: You've built or operated similar systems. Explain why append-only logs are fast, how ISR prevents slow replicas from blocking, and how offset management enables at-least-once delivery.
- Full Proactivity: You drive the entire conversation. You bring up edge cases like rebalancing disruption before being asked.
- The Bar: Address all deep dives without prompting: append-only I/O, offset management, ISR, and rebalancing. Demonstrate that given enough time, you could actually build this.
Do a mock interview of this question with AI & pass your real interview. Good luck! 📨