
Design Ticketmaster (Seat Reservations)
Problem Context
🎟️ Ticketmaster is the world's largest ticket marketplace, processing billions of dollars in ticket sales annually. You have millions of users competing for thousands of tickets.
In this system, we're not serving infinite content to users. We're managing scarce, unique inventory under extreme concurrent demand. Every seat can only be sold once, and we must never oversell.
In this article, we will focus on Assigned Seating (specific seat_ids), which is harder. For General Admission, we would simply atomically decrement a capacity counter.
Functional Requirements
Core Functional Requirements
- FR1: Users should be able to browse events and view real-time seat availability.
- FR2: Users should be able to select seats and temporarily hold them during checkout.
- FR3: Users should be able to complete purchase and receive confirmed tickets.
Out of Scope:
- Event creation and venue management (admin functionality).
- Payment processing internals.
- Ticket scanning and venue entry.
- Resale/transfer marketplace.
- Mobile app push notifications.
Acknowledging what's out of scope shows the interviewer you understand the full product but can prioritize. You can refine this to what your interviewer wants to see.
Non-Functional Requirements
Core Non-Functional Requirements
- NFR1: System should handle 100K+ concurrent users during flash sales.
- NFR2: Zero overselling.
- NFR3: Seat holds should automatically expire after ~10 minutes.
- NFR4: System should be highly available (99.99%+).
Here's what we have so far:

Let's get to work.
The Set Up
Planning the Approach
Based on our requirements, we have two distinct challenges:
- The Reading Problem: Showing seat availability to potentially millions of browsers.
- The Writing Problem: Actually reserving and purchasing seats without overselling.
Reading is high-volume but tolerates slight staleness. Writing is lower-volume but demands perfect accuracy.
In the interview, start with a working system first. Acknowledge the flaws but get something functional before optimizing.
Defining the Core Entities
For this problem, we have several entities to work with:
- Event: A concert, game, or show with a specific date/time and venue.
- Venue: A physical location with a defined seat map (sections, rows, seats).
- Seat: A specific seat with a status:
available,held, orsold. - Reservation: A temporary hold on one or more seats (expires after timeout).
- Ticket: A confirmed purchase. The seat is permanently assigned to a user.
API Interface
Our APIs naturally split into browsing (read-heavy, tolerates caching) and booking (write-heavy, requires strong consistency).
Browsing APIs (Read-Heavy): FR1
These power the seat map that users see when shopping for tickets.
1. Get Event Details
GET /events/{eventId}
Response:
{
"eventId": "evt_taylor_2024",
"name": "Taylor Swift - Eras Tour",
"venue": "SoFi Stadium",
"date": "2024-08-15T19:00:00Z",
"sections": ["Floor", "Lower Bowl", "Upper Bowl"]
}
2. Get Seat Availability
GET /events/{eventId}/seats?section=Floor
Response:
{
"section": "Floor",
"seats": [
{"seatId": "F-A-1", "row": "A", "number": 1, "status": "available", "price": 450},
{"seatId": "F-A-2", "row": "A", "number": 2, "status": "held", "price": 450},
{"seatId": "F-A-3", "row": "A", "number": 3, "status": "sold", "price": 450}
]
}
Why return all statuses? The seat map UI needs to show which seats are available (clickable), held by others (grayed out), or already sold (marked X).
Booking APIs (Write-Heavy): FR2, FR3
These handle the actual reservation and purchase flow.
1. Create Reservation (Hold Seats)
POST /reservations
Request:
{
"eventId": "evt_taylor_2024",
"seatIds": ["F-A-1", "F-A-3"],
"userId": "user_123"
}
Response:
{
"reservationId": "res_abc789",
"seats": ["F-A-1", "F-A-3"],
"expiresAt": "2024-08-01T10:10:00Z", // 10 minutes from now
"status": "held"
}
What happens here? The system attempts to grab these seats. If successful, they're marked held and other users can't select them. The user has 10 minutes to complete checkout.
2. Complete Purchase
POST /orders
Request:
{
"reservationId": "res_abc789",
"paymentToken": "tok_visa_4242"
}
Response:
{
"orderId": "ord_xyz456",
"tickets": [
{"ticketId": "tkt_001", "seat": "F-A-1", "barcode": "..."},
{"ticketId": "tkt_002", "seat": "F-A-3", "barcode": "..."}
],
"status": "confirmed"
}
What happens here? The reservation is converted to permanent tickets. Seats transition from held to sold. The reservation is deleted.
3. Release Reservation (Cancel)
DELETE /reservations/{reservationId}
Response:
{
"status": "released",
"seats": ["F-A-1", "F-A-3"] // Now available again
}
Why explicit release? User changed their mind, payment failed, or they just closed the browser. We need to free those seats for others.
High-Level Design
Let's start with our functional requirements:
- FR1: Browse events & view seat availability
- FR2: Select & temporarily hold seats
- FR3: Complete purchase & receive tickets
We'll start with the simplest design and fix problems as we go (for explaining sakes). You can start at diagram 3 in an actual interview.
1) The Simplest Design: FR3 (Purchase)
Let's start with the simplest process: a user picks a seat and we mark it sold.
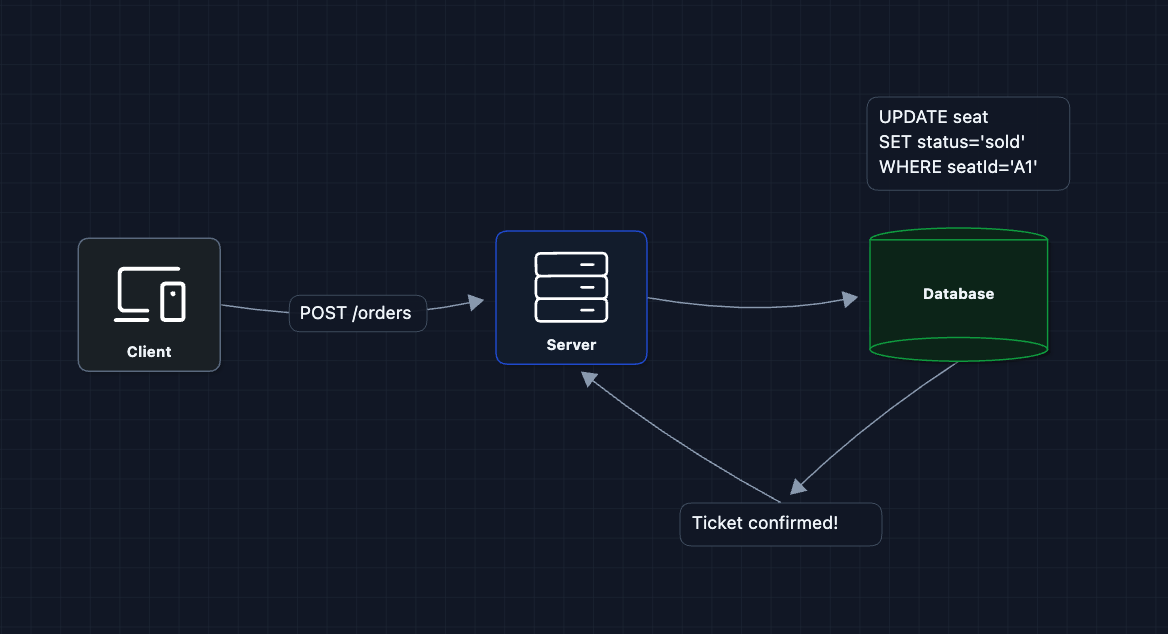
seats table:
| seat_id | status | user_id |
|---|---|---|
| A1 | sold | user123 |
| A2 | available | null |
The user clicks seat, the server updates the database, and the ticket is confirmed. This actually works for a low-traffic scenario.
But what breaks?
- Race condition: Two users click the same seat at the exact same moment. Both queries run and succeed. We just sold seat A1 to two people.
This is the core problem of ticketing systems.
2) The Race Condition Problem
Let's visualize what goes wrong with concurrent requests:
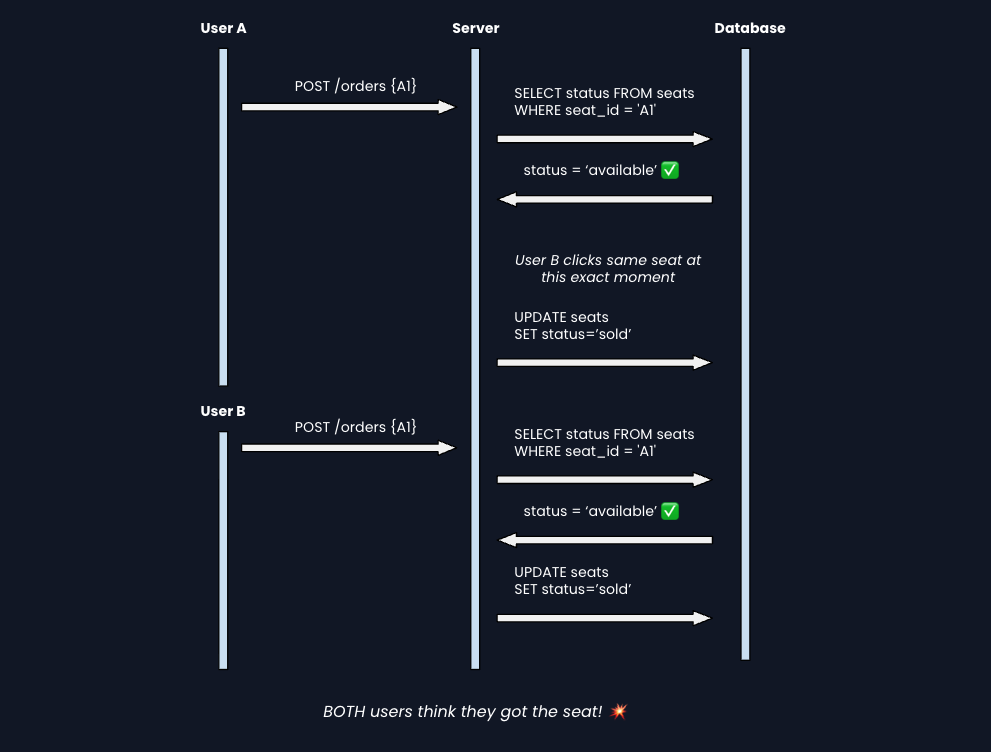
How do we fix this? We need to make the check-and-update atomic. They must happen as one indivisible operation.
3) Fix Race Conditions with Atomic Updates: FR3 (Purchase) ✅
Instead of SELECT then UPDATE, we do a conditional UPDATE that only succeeds if the seat is still available:
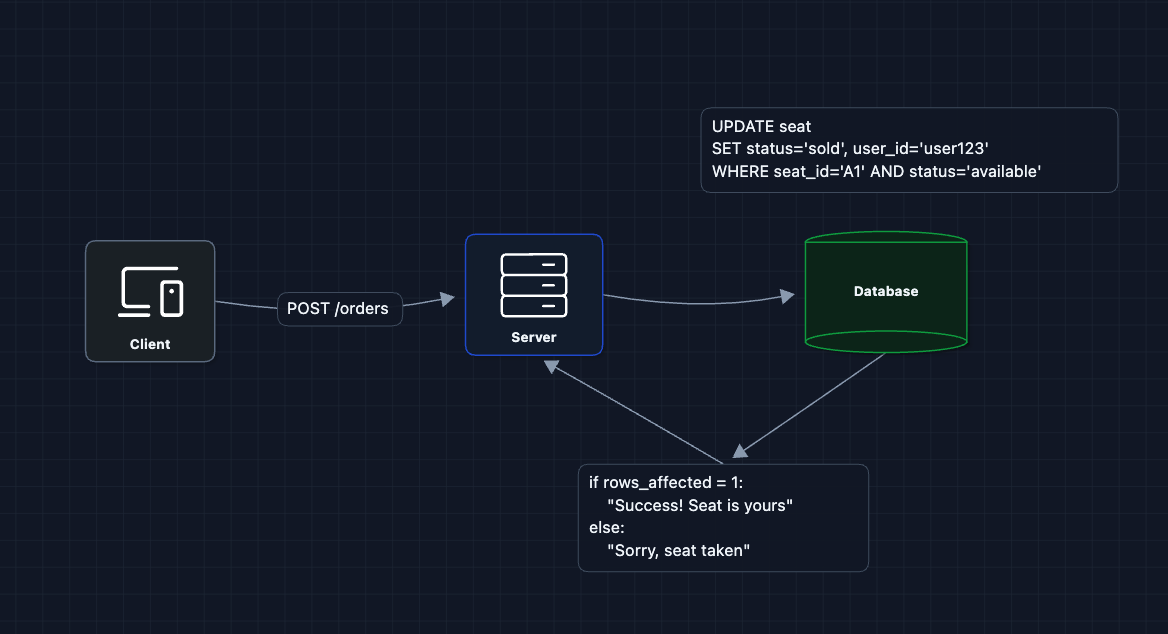
How does this prevent double-booking?
The database guarantees that the UPDATE is atomic. Even if two requests arrive at the same microsecond, the database processes them one at a time. The first one changes status to sold. The second one's WHERE clause (status='available') no longer matches.
Why this approach? There are two ways to prevent race conditions:
-
Pessimistic locking: Lock the row before checking. Other users wait in a queue until you're done. This guarantees success but creates bottlenecks during a flash sale because everyone waits in line.
-
Optimistic locking (what we're doing): Try the update and check if it worked. No waiting, but you might fail if someone beat you to it.
Pessimistic locking would serialize all requests and crush throughput during high-demand sales.
What breaks?
- We're going straight to
sold. What if the user needs time to enter payment info? We need an intermediateheldstate.
4) Add Temporary Holds (Reservations): FR2 (Hold Seats)
Real checkout flows take time (entering credit card, confirming details). We can't make users race to type faster. Let's add a held state:
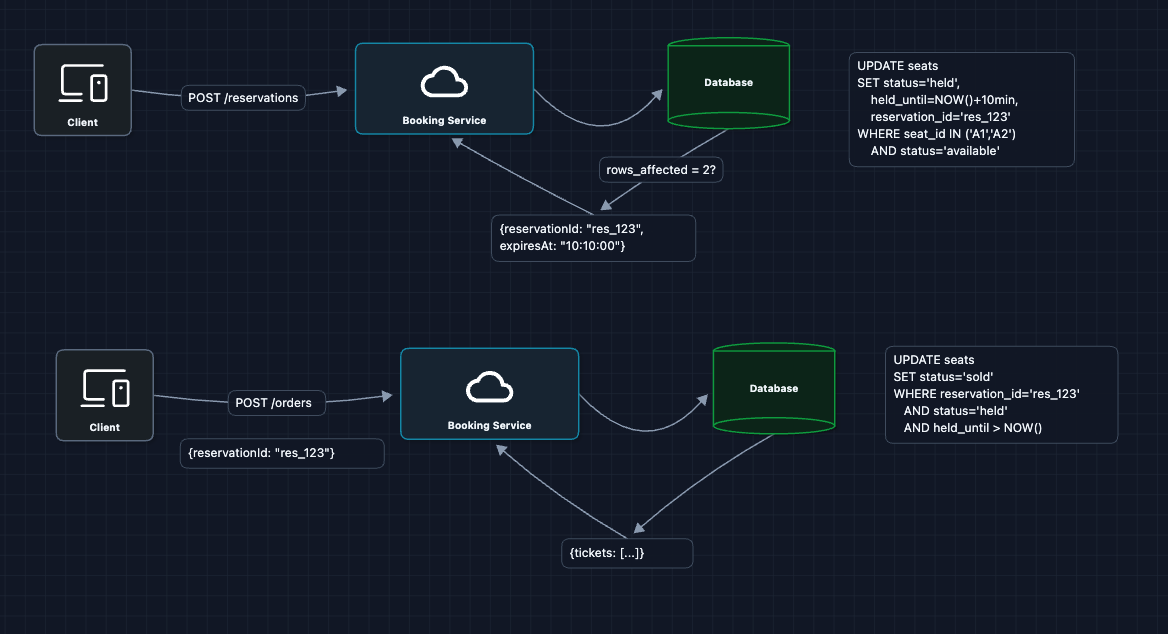
Key points:
held_untiltimestamp tracks when the hold expires- The purchase UPDATE checks
held_until > NOW()to reject late completions
What breaks?
- What happens when
held_untilpasses and the user hasn't paid? Those seats are stuck asheldforever.
5) Auto-Expire Stale Holds: NFR3 (Fairness)
We need a way to reclaim abandoned seats. There are two approaches:
Approach A: Use an Expiry Worker
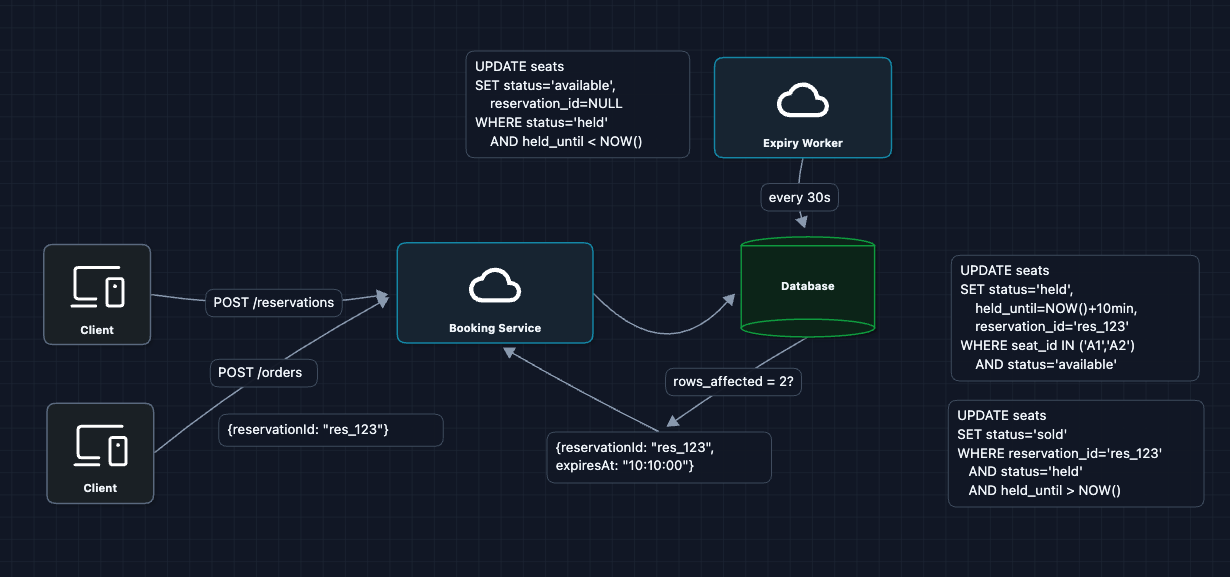
Approach B: Check on Read (Lazy Expiration)
We can also check for expiration when reading the data. If a seat is held but the held_until time has passed, we treat it as available immediately. This logic happens instantly during the query, so users never see stale held seats.
SELECT seat_id,
CASE
WHEN status='held' AND held_until < NOW()
THEN 'available'
ELSE status
END as effective_status
FROM seats
WHERE event_id = ?
Why check status='held'?
Most seats are just available or sold. For these, the condition fails immediately, and we simply return the ELSE status. We only check the timestamp for seats that are actually held.
Recommendation: Use BOTH
- Lazy expiration ensures immediate accuracy for users browsing the map.
- Background worker actually updates the database rows to keep the table clean.
What breaks?
- We're handling writes well, but what about reads? During a flash sale, millions of users are refreshing the seat map. Our database will collapse under the read load.
6) Separate Read Path from Write Path: FR1 (View Availability)
Now, reads and writes have very different requirements.
- Writes (reservations, purchases): Must be 100% consistent, hit primary database
- Reads (seat map): Can tolerate 1-2 seconds of staleness, can be cached/replicated
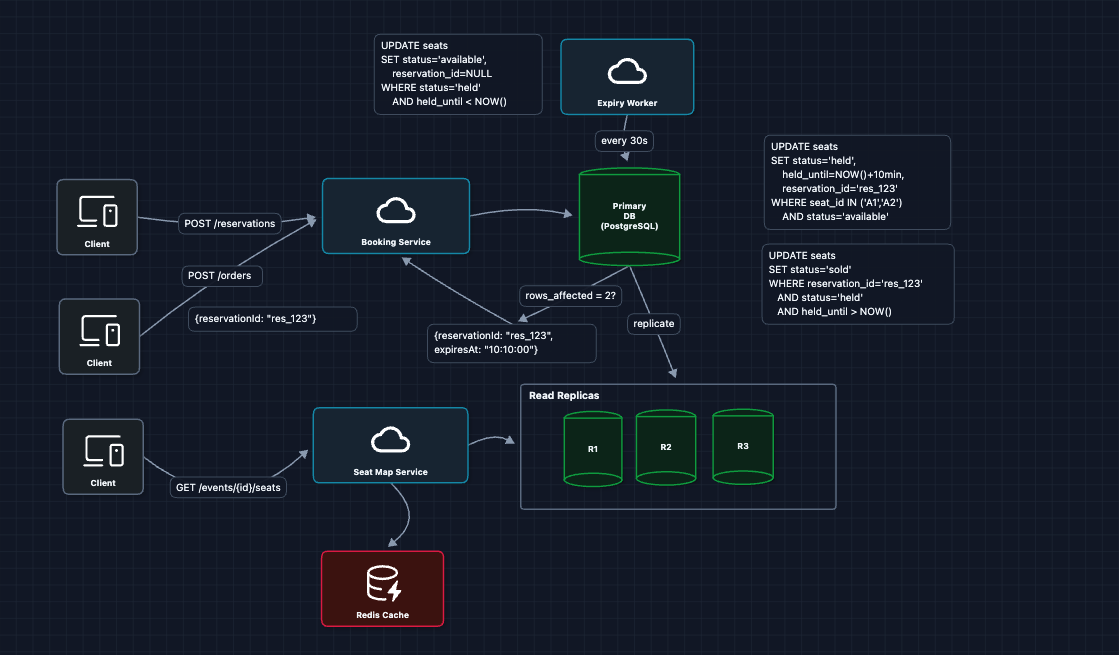
This pattern is called CQRS (Command Query Responsibility Segregation). Commands (writes) and queries (reads) go through different optimized paths.
What breaks?
- During a major on-sale event, even this architecture struggles. 500K users hitting "reserve" in the first second will still overwhelm the primary database.
7) Add Virtual Queue for Flash Sales: NFR1 (Scale)
When Taylor Swift tickets go on sale, we can't let all 500K users hit the booking system simultaneously. We need a waiting room that meters traffic:
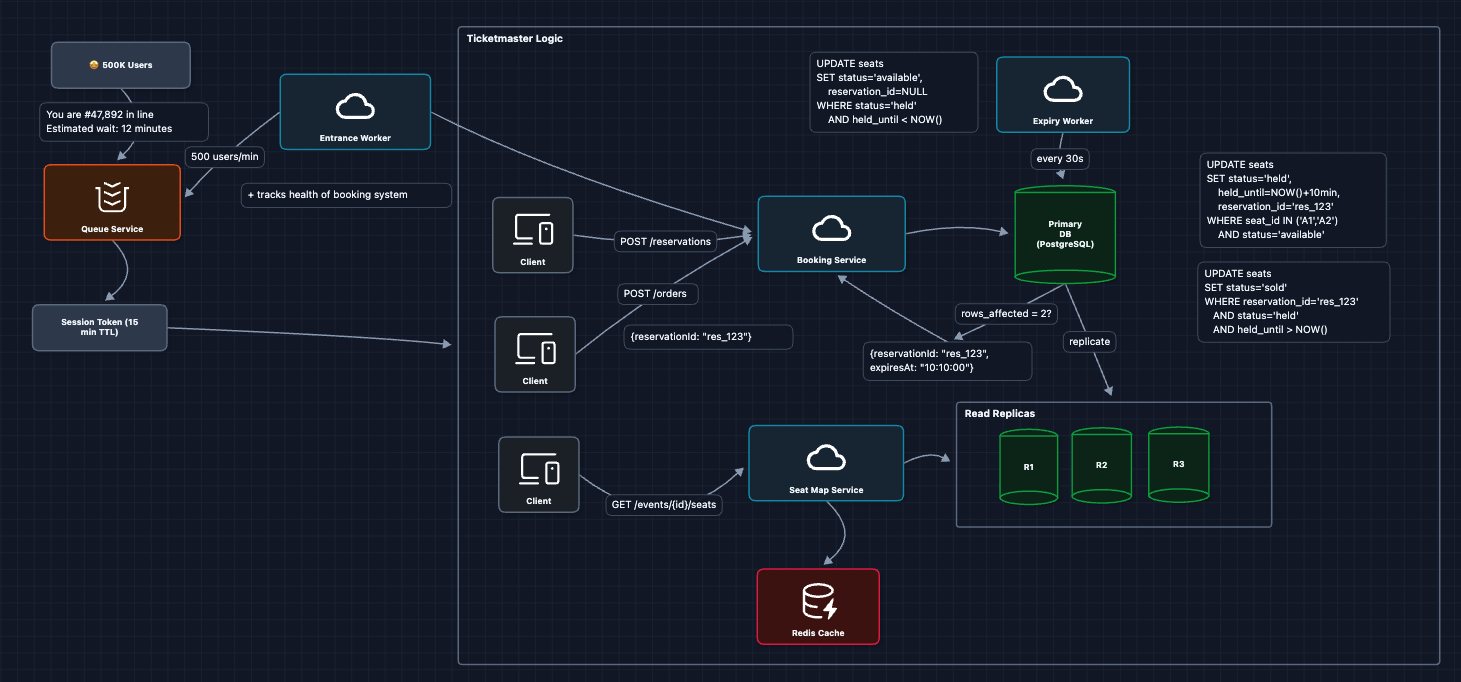
Why does this work?
- We control how many users can actively shop at once
- Users get a fair, first-come-first-served experience
- The booking system operates at a sustainable load
- Users see their position rather than getting errors
What breaks?
- We've been assuming a single database. What happens when it fails?
We'll cover this in the deep dives.
8) Complete HLD
Now we have a complete working system that satisfies all functional requirements:
- FR1 ✅ View availability (Diagram 6: read replicas + cache)
- FR2 ✅ Hold seats (Diagrams 4-5: reservations with expiry)
- FR3 ✅ Complete purchase (Diagram 3: atomic updates)
This is our baseline architecture.
Now we can address our non-functional requirements in the deep dives:
- NFR2 (Consistency): How exactly do we prevent double-booking?
- NFR3 (Fairness): How do we handle hold expiration reliably?
- NFR1 (Scale): How does the virtual queue actually work?
- NFR4 (Availability): What happens when things fail?
Potential Deep Dives
1) Reserving Multiple Seats Atomically: NFR2 (Zero Overselling)
In the HLD, we showed atomic updates for a single seat. But users often want multiple seats together (a family of 4, a group of friends). This introduces a new failure mode:
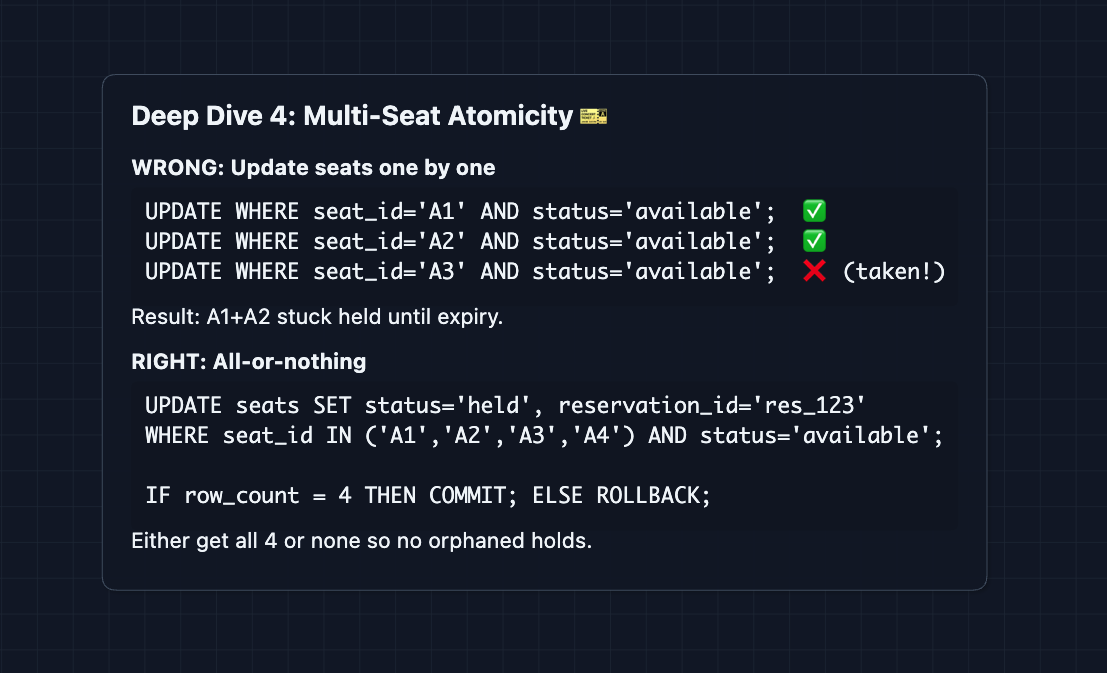
The transaction ensures we either get all requested seats or none. There are no orphaned holds.
2) How does the virtual queue actually work?: NFR1 (Scale)
From Diagram 7, we introduced the concept. Here's how it flows:

The queue gates entry to the booking system. We only process how many tokens we pass out in the first place.
How does the Token work?
- Format: We use a JWT (JSON Web Token) that is signed by the Queue Service's private key.
- Storage: The user's browser stores this token (ex. in
localStorageor a cookie). - Scope (What is Gated?):
- Protected:
GET /seats(Viewing the map),POST /reservations, andPOST /orders. We gate the view so that we don't overwhelm our Read Replicas, and so 500k people aren't fighting over the same 20k seats visually. - Public: The Event Landing Page (Date, Venue, Artist) remains public so people know what they are queuing for.
- Protected:
- Validation: When the user makes a protected request, the service merely checks the signature of the JWT using the public key. It works instantly without a database lookup.
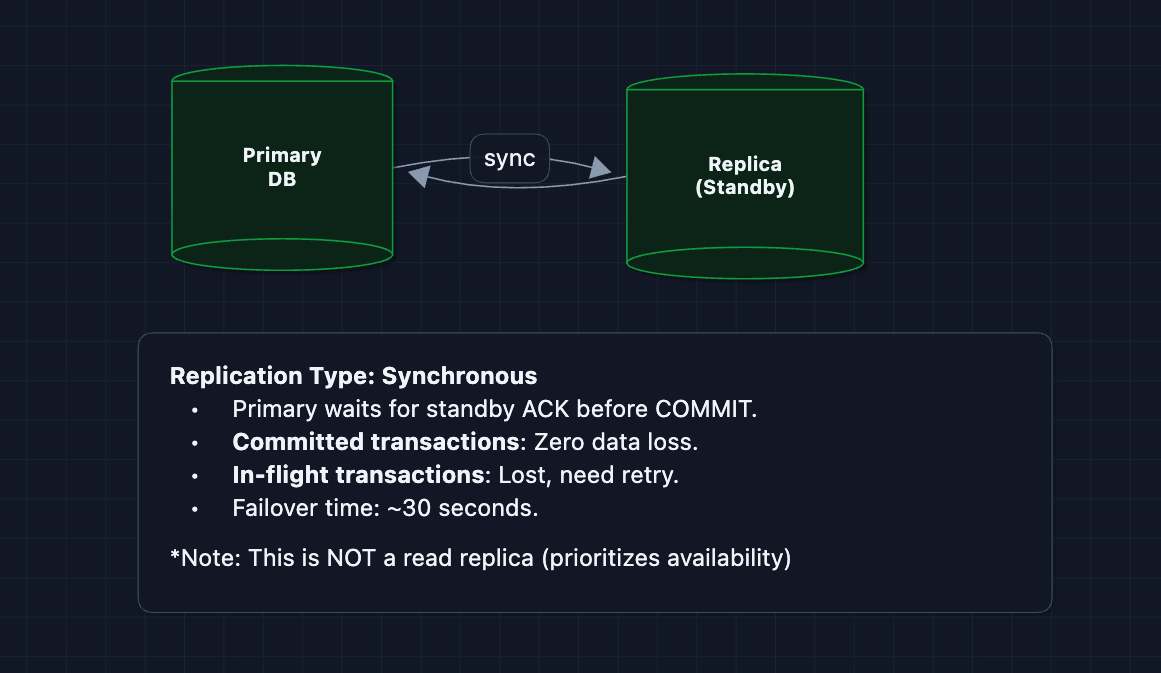
3) What happens when things fail?: NFR4 (Availability)
Our system has multiple failure modes. Here's how we handle them:
4) How do we scale beyond a single database?
A single database can't handle all global events. We need to shard by event.
Sharding Strategy: Partition by event_id
Request for evt_taylor_2024:
→ hash(evt_taylor_2024) % num_shards
→ Routes to Shard 2
Why this works:
- Independence: Each event's seats are completely independent. No cross-event transactions needed.
- Atomicity Preserved: All seats for
evt_taylor_2024live on Shard 2. Multi-seat reservation transactions work as before. - Load Distribution: Taylor Swift tickets don't compete with NBA Finals tickets.
Schema Distribution:
Shard 0: [evt_001, evt_042, evt_089...] ← Primary + Failover Standby
Shard 1: [evt_005, evt_taylor_2024...] ← Primary + Failover Standby
Shard 2: [evt_007, evt_210, evt_512...] ← Primary + Failover Standby
Each shard has its own primary database and failover standby (as shown in Deep Dive 3).
Routing Layer:
The booking service uses consistent hashing to route requests to the correct shard. For a deep dive on how consistent hashing works, see Distributed KV Store.
What breaks with this approach?
- Cross-event queries: "Show me all events in Los Angeles" now requires querying multiple shards.
- Solution: Keep a separate Event Catalog Service with metadata (event name, venue, date) that routes users to the correct booking shard.
What to Expect?
That covered a lot! Here's what you should focus on at each level.
Mid-level
- Breadth over Depth (80/20): Get the basic flow working. Show you understand why race conditions cause overselling and how atomic conditional updates fix them.
- Expect Probing: "What happens if two people click the same seat?" "Why do we need a held state?" You should explain the checkout time problem clearly.
- Assisted Driving: You lead the initial design, but the interviewer can guide you toward the locking mechanism and hold expiration.
- The Ticketmaster Bar: Demonstrate understanding of the main booking flow. Articulate why "check then write" fails and why optimistic locking is better than pessimistic.
Senior
- Balanced Breadth & Depth (60/40): Go deeper on concurrency control. Explain optimistic vs pessimistic locking and why optimistic works for ticketing. Discuss separating reads from writes.
- Proactive Problem-Solving: Identify the flash sale problem before the interviewer mentions it. Bring up the virtual queue concept. Bring up multi-seat atomicity without prompting.
- Articulate Trade-offs: "Optimistic locking works when contention is low. During flash sales, some users get 'seat taken' errors, but that is acceptable. Pessimistic locking would serialize everyone."
- The Ticketmaster Bar: Complete the full HLD and proactively dive into multi-seat reservations, virtual queue mechanics, or database failover.
Staff
- Depth over Breadth (40/60): The interviewer assumes you know the basics. Spend around 15 minutes getting to the HLD, then go deep on interesting failure modes.
- Experience-Backed Decisions: You have built or operated similar systems. You know why Redis works for queues and can discuss real-world failure scenarios.
- Full Proactivity: You drive the conversation. The interviewer is mostly listening. You suggest alternatives: "We could use Kafka for the queue, but Redis is simpler at this scale."
- The Ticketmaster Bar: Address all deep dives without prompting. Discuss multi-seat atomicity, database failover, and how the queue gates traffic. The interviewer is looking for someone who could actually build this.
Do a mock interview of this question with AI & pass your real interview. Good luck! 🎟️