
Design Trending Hashtags / Top-K
Problem Context
📈 Trending hashtags appear across Twitter, Instagram, TikTok, and countless other platforms. At Twitter's scale, this means processing 500 million tweets per day.
The challenge is simple: count how often each hashtag appears and show the top ones. But when you're processing hundreds of thousands of events per second across millions of unique hashtags, and things break down fast.
Functional Requirements
The scope of trending systems varies widely. Clarify your scope with your interviewer, but we will focus on hashtag trends in this article.
Core Functional Requirements
- FR1: Users can include hashtags in their posts, and each usage generates an event.
- FR2: The system computes and returns the Top-K trending hashtags in near real-time.
- FR3: Trending results can be scoped by time window (last hour, last 24h) and optionally by region.
Out of Scope
- The post creation system itself (we receive hashtag events as input).
- Spam/bot detection and filtering.
- Personalized trending (showing different trends per user).
- Hashtag content moderation.
Acknowledging out-of-scope items shows you understand the broader system, even when you're focusing on a specific part.
Non-Functional Requirements
Core Non-Functional Requirements
- NFR1: Trending list should reflect reality within ~1 minute of a spike.
- NFR2: System should handle 100K+ hashtag events per second.
- NFR3: System should be highly available (99.9%+).
- NFR4: Rankings can tolerate minor inaccuracies for efficiency.
Here's what we have so far:

Let's build this system.
The Set Up
Planning the Approach
The main system breaks down into two distinct operations:
- Counting: Ingesting a firehose of hashtag events and maintaining counts.
- Ranking: Extracting the Top-K hashtags from potentially millions of candidates.
In an interview, call out early that this is a streaming aggregation problem. The challenge isn't storing data but processing it fast enough.
Defining the Core Entities
For this problem, we work with:
- Hashtag Event: A single occurrence (hashtag string, timestamp, region, post ID).
- Hashtag Count: Aggregated count for a hashtag within a time window.
- Trending List: The final Top-K hashtags with their counts and metadata.
- Time Window: A defined period for aggregation (e.g., last 60 minutes).
API Design
We have two main API categories: one for ingesting events (internal) and one for retrieving trends (external).
Event Ingestion (Internal)
When a user creates a post with hashtags, the post service extracts them and sends events.
1. Submit Hashtag Event
POST /api/v1/events/hashtags
Request:
{
"postId": "post_12345",
"hashtags": ["WorldCup", "Football"],
"timestamp": "2024-12-15T14:30:00Z",
"region": "us-east"
}
Response:
{
"status": "accepted"
}
This endpoint just acknowledges receipt. The actual counting happens asynchronously.
Trending Retrieval (External)
Users and clients request the current trending hashtags.
1. Get Trending Hashtags
GET /api/v1/trending?k=10®ion=us-east&window=1h
Response:
{
"trending": [
{"rank": 1, "hashtag": "WorldCup", "count": 2847291},
{"rank": 2, "hashtag": "Football", "count": 1923847},
{"rank": 3, "hashtag": "Messi", "count": 892341},
...
],
"window": "1h",
"region": "us-east",
"computedAt": "2024-12-15T14:30:45Z"
}
Parameters explained:
k: How many top hashtags to return (default: 10)region: Filter by geographic region (optional, default: global)window: Time window for counting (1h, 24h, etc.)
High-Level Design
Let's build toward our functional requirements:
- FR1: Receive hashtag events from posts
- FR2: Compute Top-K trending in real-time
- FR3: Scope by time window and region
We'll start with the most obvious approach and discover why it fails at scale (we will fix these in the deep dive). This mirrors how you'd think through the problem in an interview.
1) The Simplest Approach
The simplest approach is to store counts in a database as events come in.
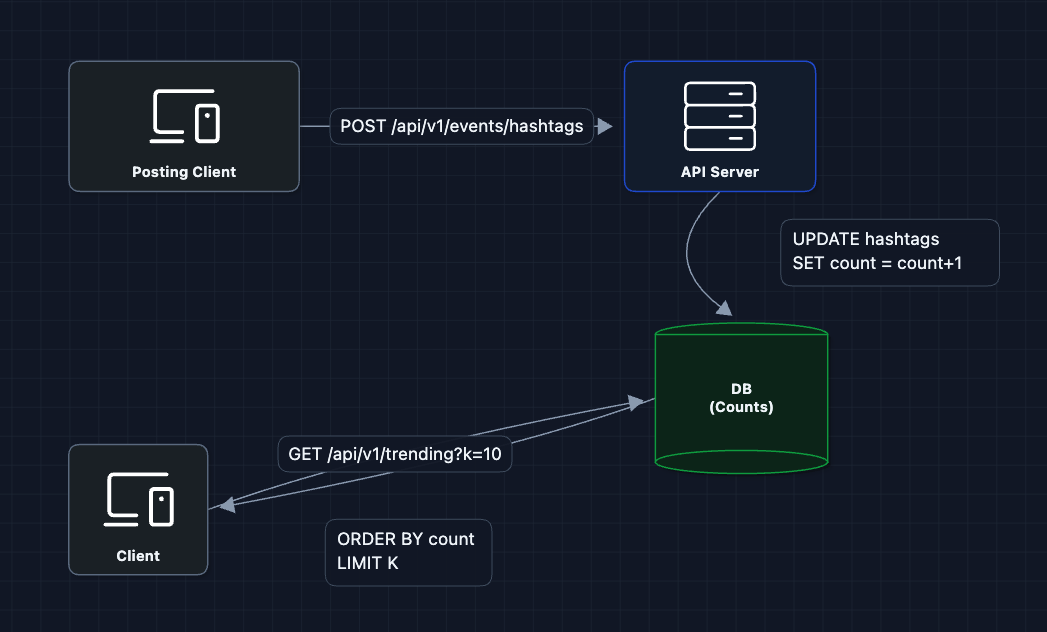
For each hashtag event, we run UPDATE hashtags SET count = count + 1 WHERE tag = 'WorldCup'. To get trending, we query ORDER BY count DESC LIMIT 10.
Why this fails at scale:
- Write contention: Popular hashtags get updated thousands of times per second. The row for "WorldCup" becomes a bottleneck.
- Query performance: Sorting millions of rows on every read is expensive.
- Time windows: How do we "forget" old counts? We'd need to continuously decay values.
We need to decouple ingestion from counting.
2) Add a Message Queue: FR1 ✅
Let's separate event receipt from processing. The API just accepts events and pushes them to a queue.
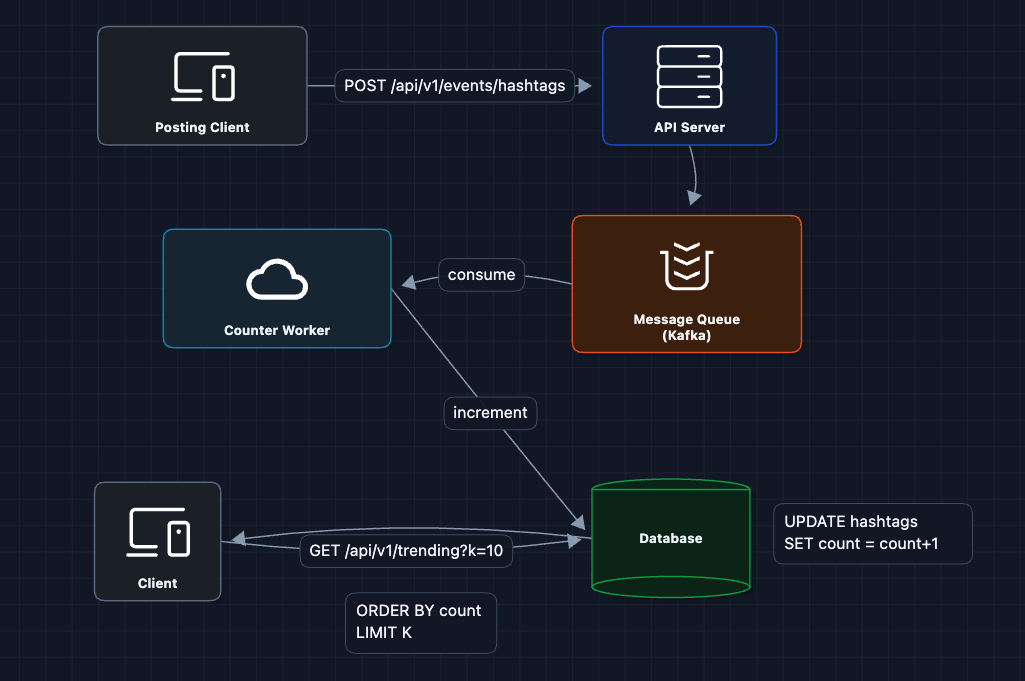
The API server responds immediately after queueing. Counter workers process events at their own pace.
What this fixes:
- API servers stay fast (just queue, don't compute)
- Workers can be scaled independently
- Kafka handles 100K+ messages/second easily
What still breaks:
- Workers still write to the database per-event
- We're still doing synchronous DB updates for every hashtag
- The WorldCup row is still a bottleneck
We need to batch our counting.
3) Stream Processing with Micro-Batches: FR2 (in progress)
Instead of counting one event at a time, we aggregate in memory over small windows.
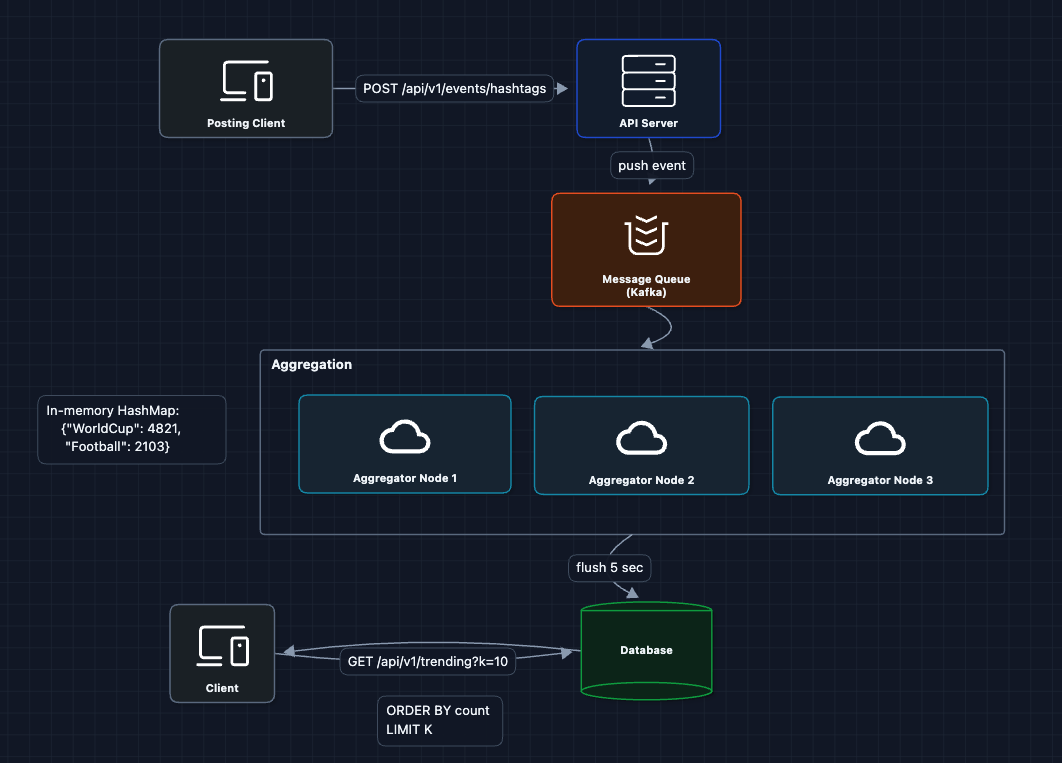
Each aggregator node:
- Consumes events from Kafka
- Maintains an in-memory HashMap of hashtag and count
- Every 5 seconds, flushes accumulated counts to storage
This reduces writes from 100K/sec to maybe 1K/sec (batched updates).
What this fixes:
- Massive reduction in database writes
- No row-level contention (we batch updates)
- Aggregators can scale horizontally
What still breaks:
- Memory usage: If there are 10 million unique hashtags in an hour, each aggregator needs a huge HashMap.
We need a more memory-efficient counting structure.
4) Count-Min Sketch for Memory Efficiency: FR2 ✅
The Count-Min Sketch (CMS) is a probabilistic data structure that estimates frequencies using far less memory than a full HashMap.
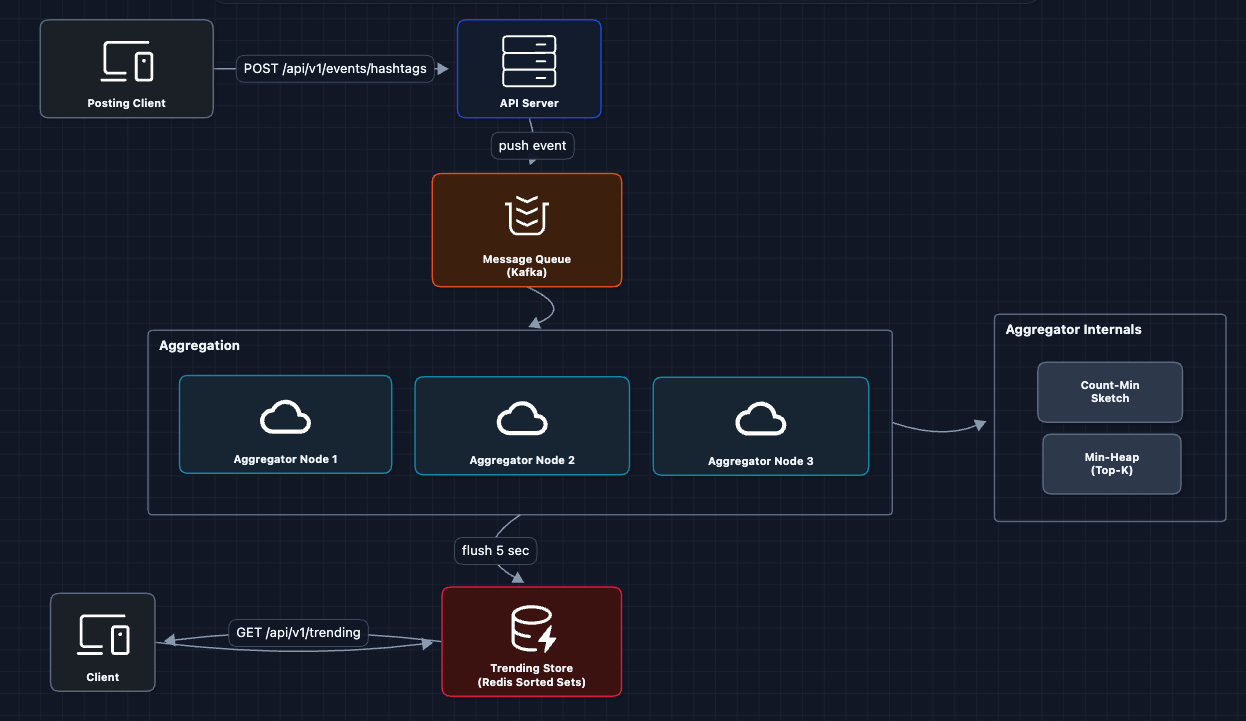
Two problems to solve:
- Memory: 10M unique hashtags is gigabytes of RAM per aggregator if we use a HashMap.
- Speed: Traditional DBs are too slow (disk writes, sorting millions of rows).
Why Redis instead of a traditional DB?
| Operation | PostgreSQL | Redis Sorted Set |
|---|---|---|
| Update count | Disk write per event | In-memory, instant |
| Get Top-10 | ORDER BY ... LIMIT scans rows | ZREVRANGE 0 9 is already sorted |
Redis keeps everything in memory and sorted sets are always in order. No sorting needed at read time.
Memory-efficient counting: The aggregator uses a Count-Min Sketch + Min-Heap to count millions of hashtags with fixed memory. We'll cover how this works in the deep dive.
The min-heap is only partially sorted (just tracks Top-K candidates). The full sorting happens in Redis sorted sets, which is what clients read from.
What this fixes:
- Fixed memory (~1-2MB) even with 10M+ hashtags
- No per-event database writes
- Only K results stored in Redis
Trending data is ephemeral. Each flush overwrites the previous Top-K in Redis. If you need historical analytics, write to a separate database.
What still breaks:
- Single aggregator can't handle all traffic
- No regional breakdown yet
Let's partition the work.
5) Partitioned Aggregation by Region: FR3 ✅
For regional trends and better scalability, we partition events by region.
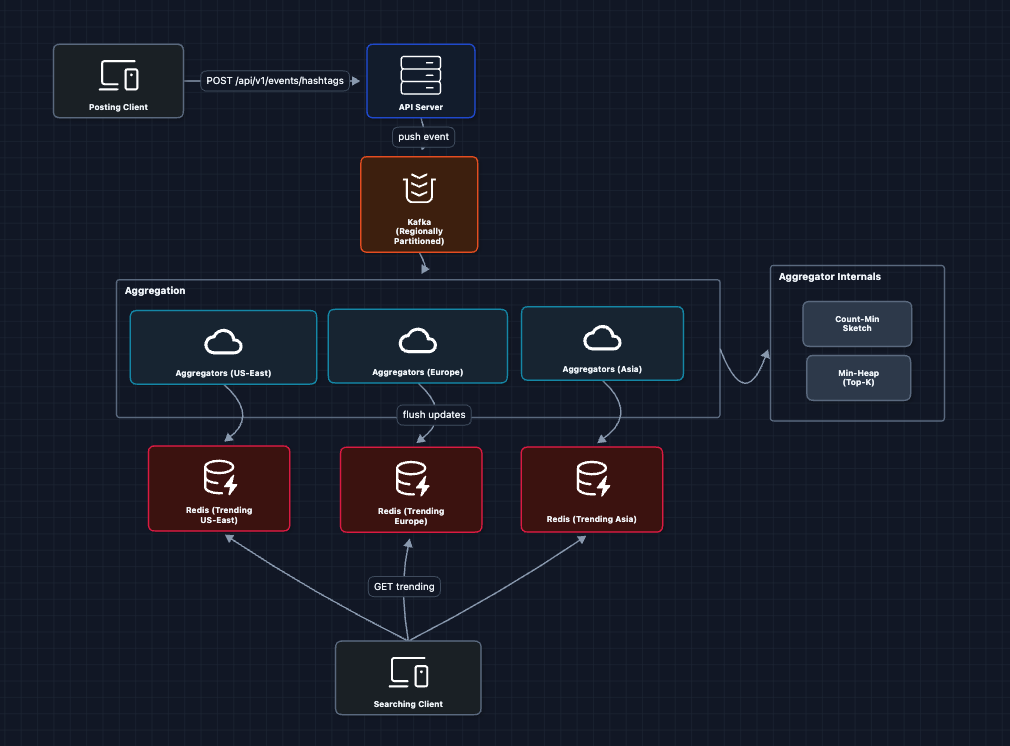
Each aggregator processes events for one region and maintains its own Top-K.
What this fixes:
- Horizontal scaling (add more aggregators per region)
- Regional trends work out of the box
- Each partition has bounded throughput
What still breaks:
- No global trending (combining all regions)
- Clients hit our aggregation layer directly
Let's complete the system.
6) Complete System with Global Aggregation ✅
The final piece is to merge regional trends into global trends.
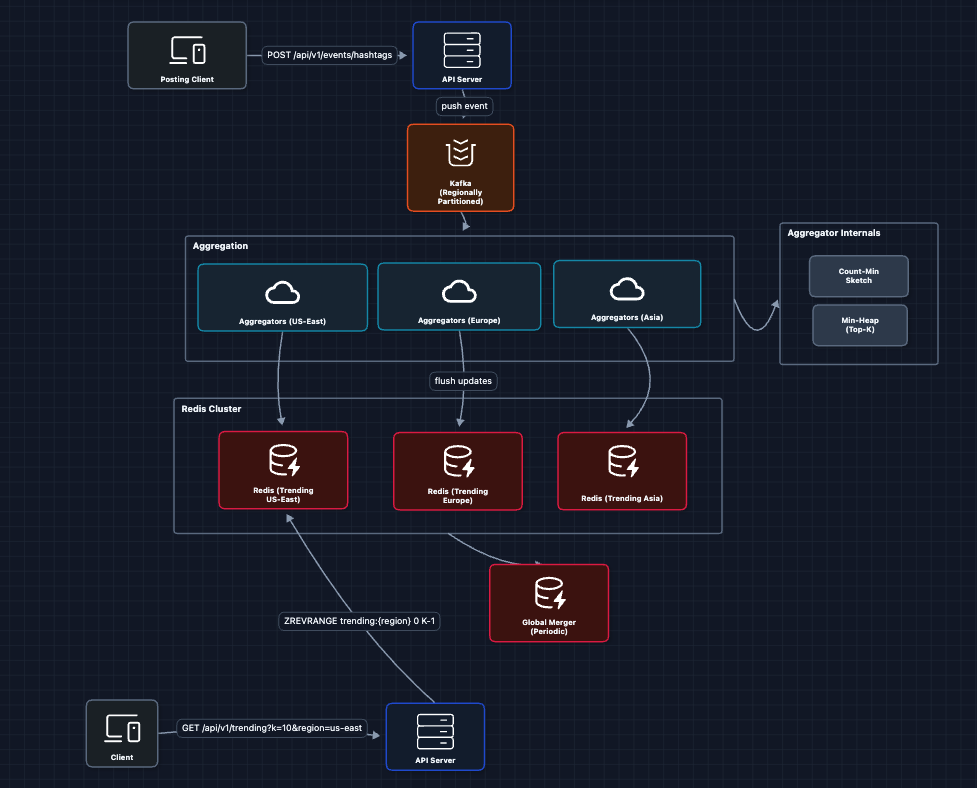
The complete flow:
Ingestion:
- API server receives hashtag events
- Events published to Kafka (partitioned by region)
- Region-specific aggregators consume their partition
- Each aggregator updates its Count-Min Sketch & Min-Heap
- Every N seconds, flush Top-K to Redis sorted set
- Global Merger reads all regional Top-Ks, merges them
Read:
- Client calls
GET /api/v1/trending?k=10®ion=us-east - API server does
ZREVRANGE trending:us-east 0 9 - Returns pre-computed Top-K (no computation at read time!)
Reads are O(n) regardless of how many events we've processed.
This satisfies all functional requirements:
- FR1 ✅: Events flow through Kafka to aggregators
- FR2 ✅: Top-K computed via CMS + Heap, stored in Redis
- FR3 ✅: Regional partitioning with global merge
Potential Deep Dives
1) Why Count-Min Sketch?: NFR2 (Throughput) + NFR4 (Accuracy)
A HashMap stores every hashtag name with its count: {"WorldCup": 50, "Football": 30, ...}. With 10 million unique hashtags, that's gigabytes of RAM. Count-Min Sketch uses a fixed-size grid instead, no matter how many hashtags you see.
The problem: Collisions
CMS doesn't store hashtag names. It just has a grid of numbers. When a hashtag arrives, we hash it to find which cell to increment. But two different hashtags can hash to the same cell and their counts get mixed together.
The fix: multiple rows with different hash functions
Each row uses a different hash function, so hashtags land in different cells per row. Two hashtags might collide in Row 1, but probably not in Row 2 or Row 3.

If we want to find the count for a hashtag, we hash the tag (no pun intended) and count from each row, based on which cells we get placed into. Then we find the minimum.
Why the minimum works: Collisions can only add to a cell's value, never subtract. So the lowest value across rows is the most accurate. It's from a row where no collision happened.
Memory vs. Accuracy trade-off:
| Configuration | Memory | Error Rate |
|---|---|---|
| 4 rows × 1K columns | 16 KB | ~0.5% |
| 5 rows × 10K columns | 200 KB | ~0.01% |
| 5 rows × 100K columns | 2 MB | ~0.001% |
For trending hashtags, a 0.1% error is perfectly acceptable. We might slightly overcount, but the ranking stays nearly identical.
2) Sliding Time Window
Trending is always scoped to a time window. With a simple 1-hour window, all data resets at the boundary. Basically, users querying at 13:01 only see 1 minute of data.
The solution: Store 12 small buckets (5 minutes each). To get the last hour, sum all 12 of these. This way, the data drops off every 5 minutes instead of an hour at a time.
3) Heap-Based Top-K Extraction: NFR2 (Throughput)
The problem: CMS can count any hashtag, but it can't tell you which hashtags are popular. (it doesn't store names, just a grid of numbers). You can't reverse-hash it.
The solution: The hashtag name comes from the event itself. We use that name to update CMS, query CMS, and check the heap.
Step-by-step flow:
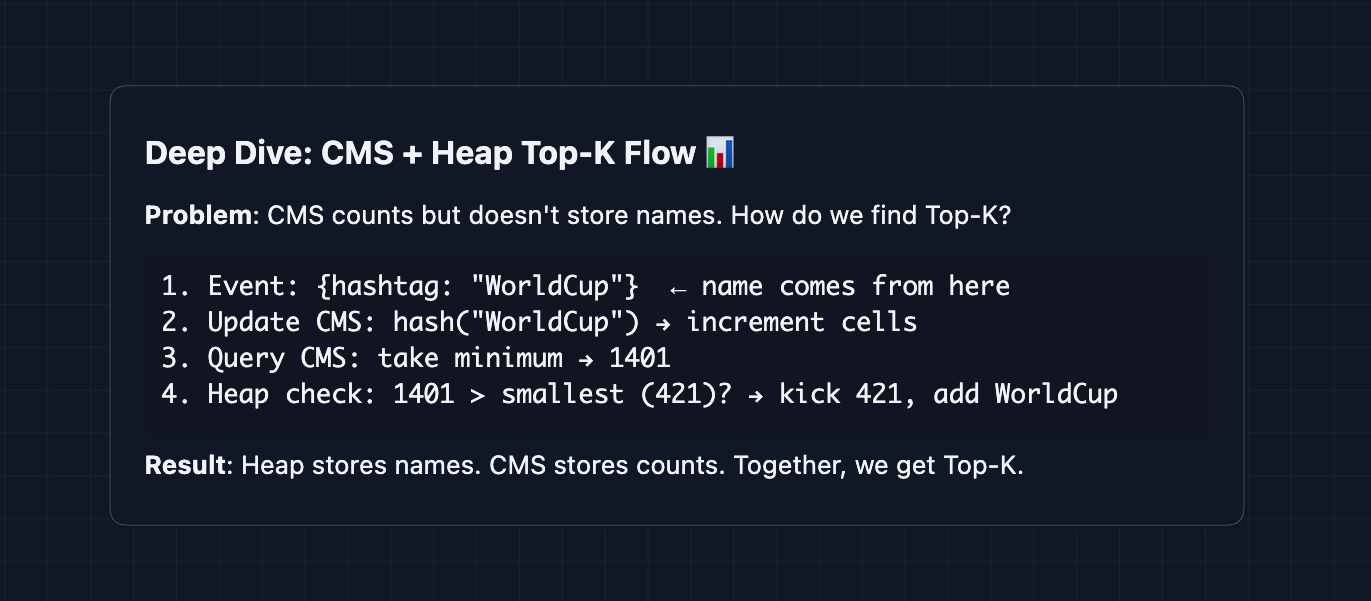
Why this approach saves memory:
| Approach | Memory |
|---|---|
| HashMap (all 10M hashtags) | Gigabytes |
| CMS grid (~1MB) + Heap (K names) | ~1-2 MB |
CMS handles the counting. Heap remembers which K hashtags are currently leading. We only store K names, not millions.
Why min-heap (not max-heap)?
We need quick access to the smallest item in our Top-K. That's the one we compare new candidates against. Min-heap gives O(1) access to the minimum.
How min-heap keeps the minimum at top:
The rule is every parent must be smaller than its children. This guarantees the root is always the smallest.
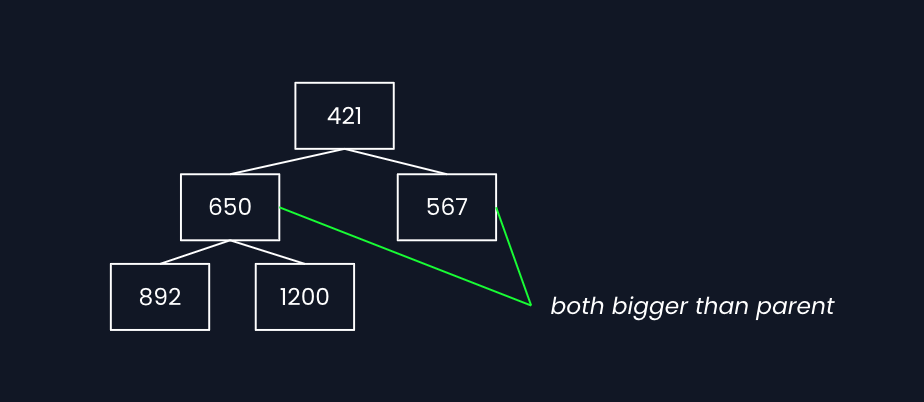
- Insert: add at start, bubble up (swap with parent if smaller)
- Remove min: take root, move last item to root, bubble down (swap with smaller child)
Both operations are O(log n) since the tree has log(n) levels.
4) Detecting Sudden Spikes: NFR1 (Freshness)
Standard Top-K shows what's most popular. But trending often means what's growing fastest.
Velocity-Based Trending:
Instead of raw count, rank by the rate of change.

How it fits with the heap:
In the HLD, the heap compared by raw count. To add velocity, we can change the heap to compare by score instead:
score = count × log(velocity + 1)
New hashtags entering the heap start with velocity at 1.0 (no history yet).
Twitter uses a combination of volume and velocity. A hashtag needs both significant volume AND unusual growth to trend.
5) Merging Regional Trends to Global: FR3
In the final step of the HLD, we have Top-K lists per region merged into a global list. But how does that work?
The Challenge:
Each region's aggregator only sees its own events. WorldCup might be #1 in Europe with 100K counts, but #5 in Asia with 20K. What's the global rank?
Current Merge (what we do):
Simply sum the counts across regions and re-rank.

Issue: Missing hashtags
If WorldCup is #150 in a region (not in Top-K), we don't have its count in the min-heap, so it is excluded.
Solutions:
- Larger K per region: Track Top-100 regionally, merge to Top-10 globally.
- Accept approximation: For most use cases, the error is acceptable.
What to Expect?
That was a lot! Here's what you realistically need to cover depending on your interview level.
Mid-level
- Breadth over Depth (80/20): Get to a working HLD. Show you understand why counting fails and how streaming aggregation solves it.
- Expect Basic Probing: "What's a Count-Min Sketch?" Be ready to explain the core idea (hash, increment, take minimum) even if you don't know the exact math.
- Assisted Guidance: The interviewer will likely help you discover the need for probabilistic data structures if you don't mention them.
- The Bar: Successfully identify the write contention problem, propose queueing/streaming, and understand that we need to avoid storing every hashtag count.
Senior
- Balanced Breadth & Depth (60/40): Cover the full HLD and go deep on 2-3 areas. Ideally, including Count-Min Sketch internals, time windowing, or the heap-based Top-K.
- Proactive Problem-Solving: You identify that global merge has accuracy gaps before being asked. You suggest larger regional K or two-tier aggregation.
- Articulate Trade-offs: "Count-Min Sketch saves memory but overcounts. For trending, that's fine."
- The Bar: Complete system with regional partitioning. Explain CMS + Heap. Discuss at least one of: time windows, velocity scoring, or merge accuracy.
Staff
- Depth over Breadth (40/60): Quickly sketch the HLD (~10 min), then spend most time on what makes this hard at very large scale.
- Deep Trade-off Reasoning: You can articulate nuanced decisions: "If we track K=100 regionally but only show K=10 globally, hashtags at #80 in multiple regions get missed. We'd need to increase regional K or accept the approximation."
- Full Proactivity: You drive the discussion. You bring up velocity scoring, spam filtering (out of scope but acknowledge it), and global consistency challenges.
- The Bar: Deep expertise in stream processing, probabilistic data structures, and distributed aggregation. You could whiteboard the CMS error bounds.
Go try a mock interview on this question with AI and good luck! 📈